
Agentic AI: Các nguyên tắc thiết kế giúp tiết kiệm chi phí Token
Triển khai AI trong môi trường sản xuất thường rất tốn kém. Bài viết này phân tích các chiến lược tối ưu hóa như prompt caching, semantic caching, lazy-loading, định tuyến mô hình và làm sạch ngữ cảnh để giúp giảm thiểu chi phí token hiệu quả.
Làm việc với AI trong môi trường sản xuất là một khoản đầu tư không hề nhỏ. Hầu hết các nhà cung cấp đều đang nỗ lực tìm cách giảm chi phí cho các tác nhân AI (agents). Tuy nhiên, với tư cách là người xây dựng hệ thống, việc áp dụng các nguyên tắc thiết kế đúng đắn ngay từ đầu là chìa khóa để tối ưu hóa ngân sách.
Bài viết này sẽ đi sâu vào cách thức hoạt động của prompt caching, semantic caching, lazy-loading, định tuyến (routing) và quản lý ngữ cảnh để giúp bạn tiết kiệm chi phí token một cách hiệu quả nhất.
 Biểu đồ tối ưu hóa chi phí AI
Biểu đồ tối ưu hóa chi phí AI
Chi phí tăng lên khi ngữ cảnh mở rộng
Một tác nhân AI ban đầu có thể chỉ cần 500 token cho hệ thống prompt và hai công cụ, nhưng khi hệ thống phát triển, con số này có thể tăng vọt. Ví dụ, hệ thống prompt của Claude bị rò rỉ với khoảng 24.000 token, hay GPT-5 khoảng 15.000 token. Người dùng đã phàn nàn rằng một lời chào "hi" đơn giản trong Claude Code có thể tiêu tốn tới 31.000 token.
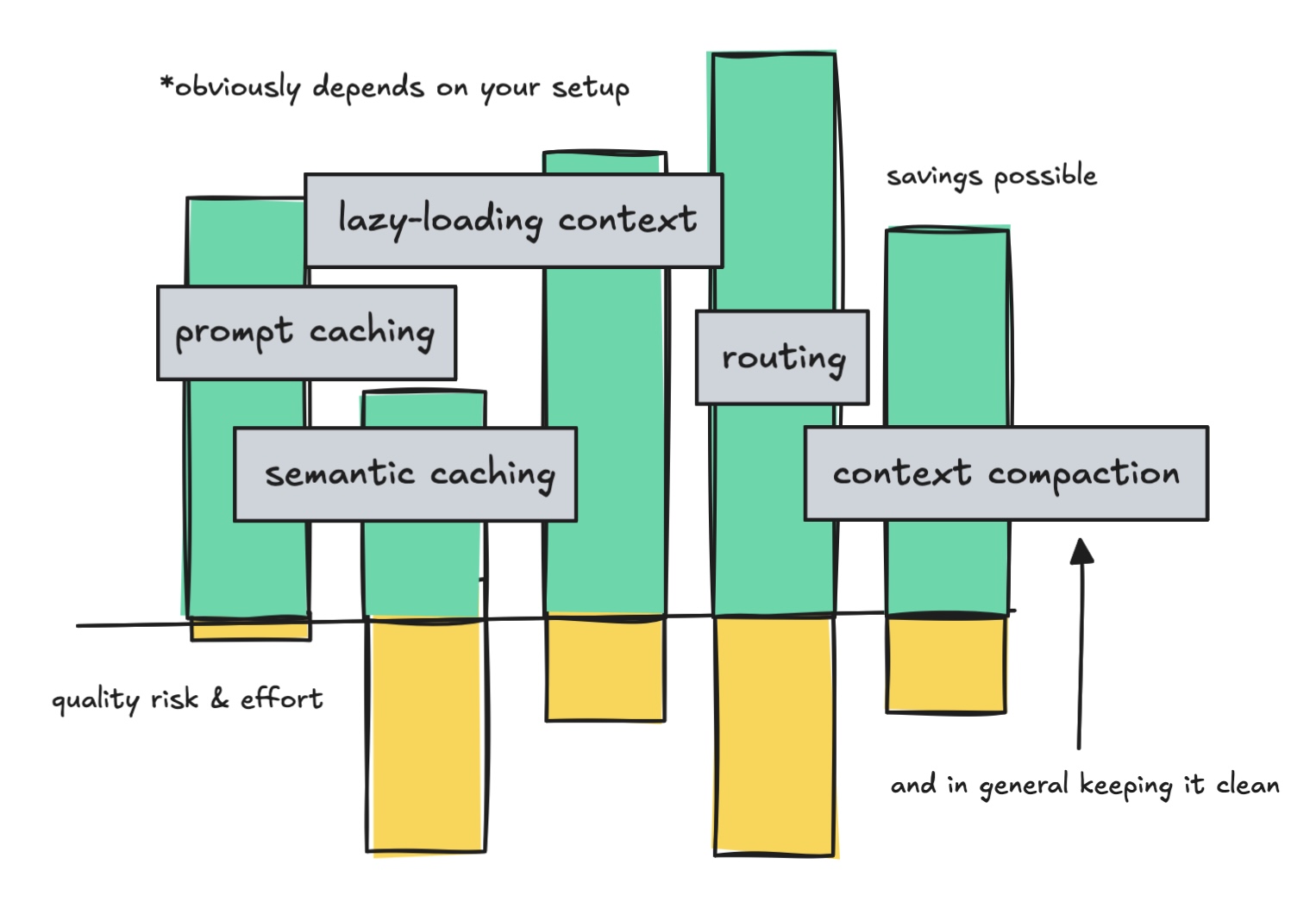
Nếu không tối ưu hóa, việc gửi 166.000 token đầu vào mỗi ngày có thể tốn khoảng 996 USD/tháng với Gemini 3.1 Pro và lên tới 2.490 USD với Claude Opus 4.6. Dưới đây là bốn nguyên tắc thiết kế chính để giải quyết vấn đề này.
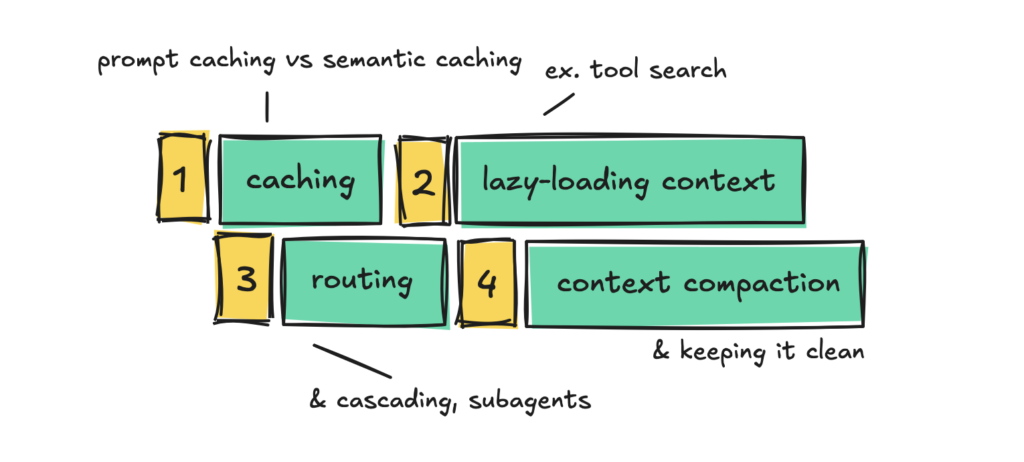
Tái sử dụng token khi có thể
Chi phí LLM không chỉ đến từ việc gọi mô hình quá thường xuyên, mà còn từ việc phải trả tiền để xử lý cùng một token lặp đi lặp lại.
Prompt Caching (Bộ nhớ đệm Prompt)
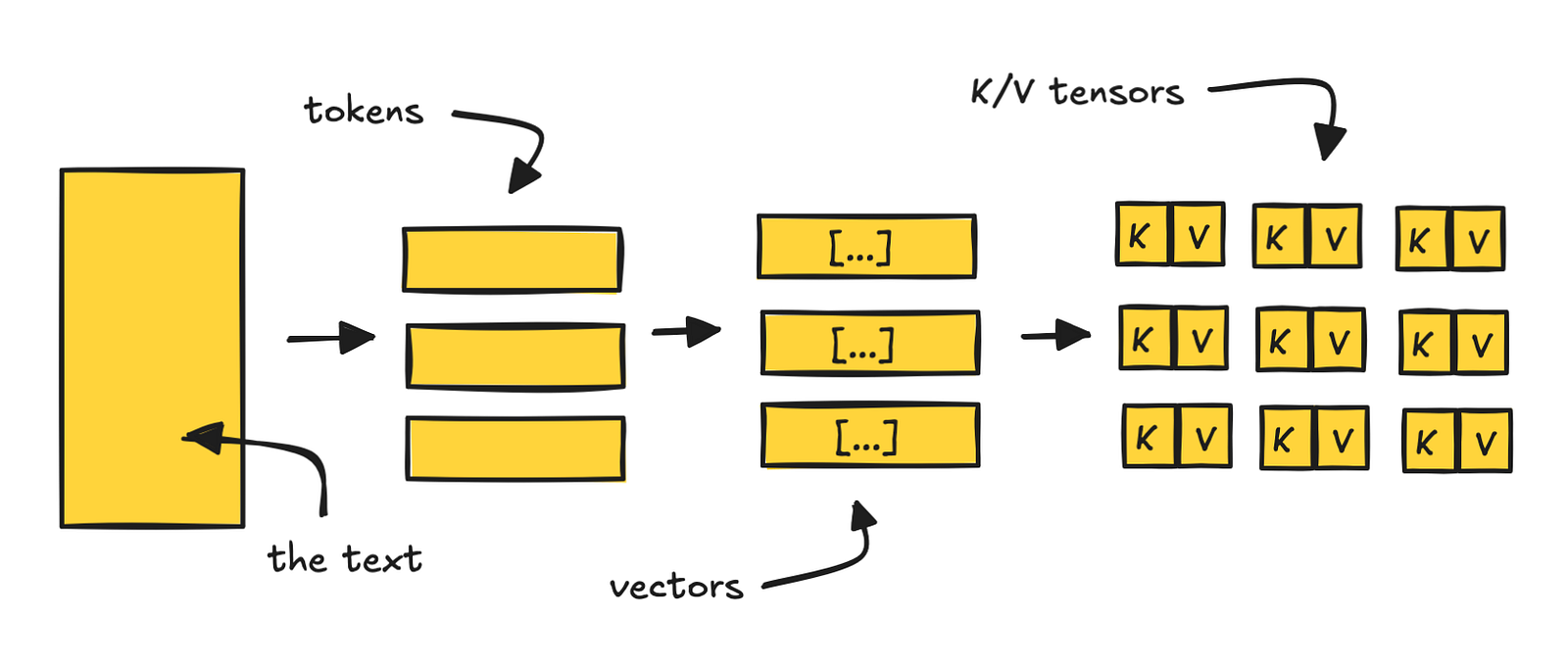
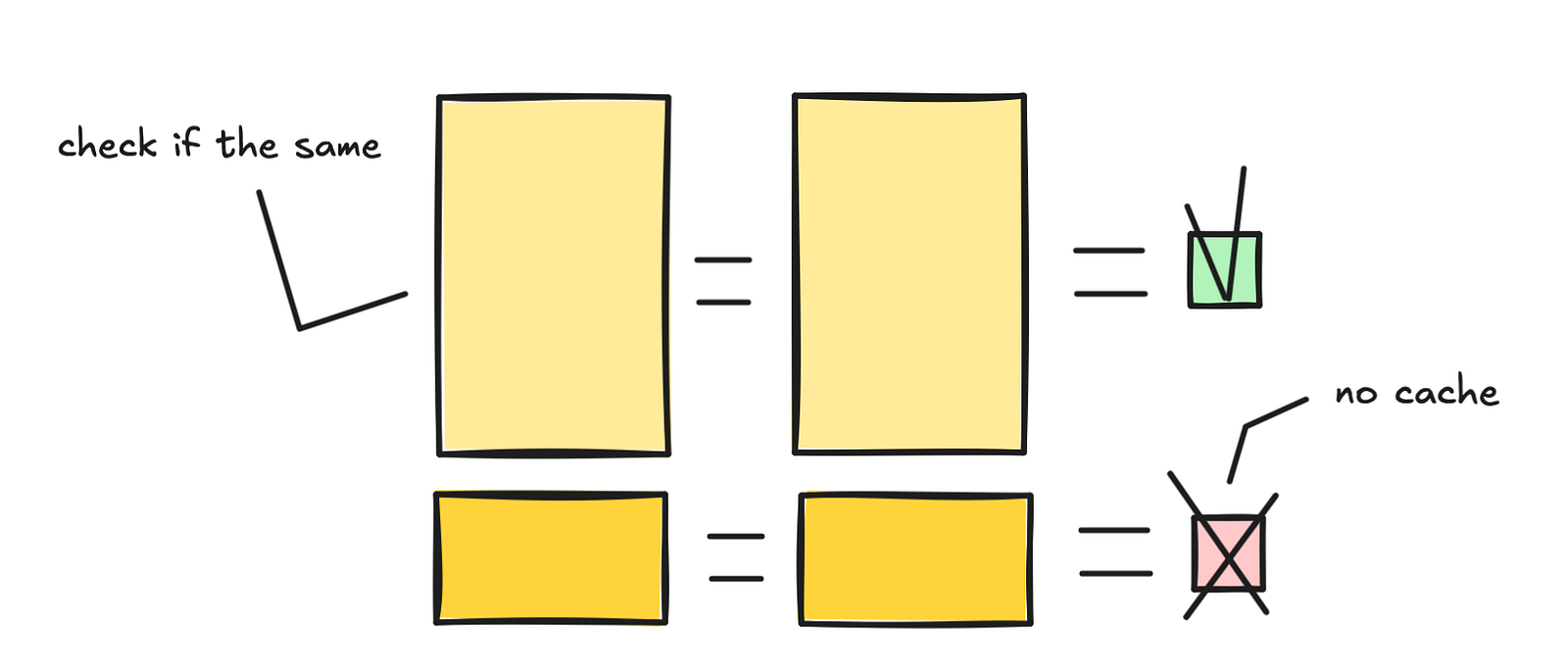
Đây là giải pháp "thắng nhanh" cho các hệ thống prompt dài. Trước khi mô hình tạo ra văn bản, nó phải xử lý prompt (bước prefill). Bước này tốn tính toán, đồng nghĩa với độ trễ và tiền bạc.
Cơ chế K/V caching (Key/Value caching) cho phép lưu trữ các tensor K/V sau khi xử lý lần đầu. Lần sau khi có yêu cầu giống hệt, hệ thống sẽ tải các tensor này thay vì tính toán lại.
- Với tự host (Self-hosted): Sử dụng các framework như vLLM với cờ
--enable-prefix-caching. vLLM sẽ chia nhỏ prompt thành các khối, băm (hash) chúng và lưu trữ tensor K/V tương ứng. - Với nhà cung cấp API: OpenAI yêu cầu khớp tiền tố chính xác (exact prefix match). Các hướng dẫn tĩnh nên đặt ở đầu prompt. Anthropic sử dụng tham số
cache-controlvà cho phép lưu cache lên đến một giờ với mức giá cao hơn.
Nếu 90% prompt của bạn là tĩnh, bạn có thể tiết kiệm tới 80% chi phí cho các lệnh gọi "ấm" (warm calls).
 Cơ chế caching trong AI
Cơ chế caching trong AI
Semantic Caching (Bộ nhớ đệm ngữ nghĩa)
Khác với prompt caching, semantic caching khớp dựa trên ý nghĩa. Nếu câu hỏi "Thủ đô của Pháp là gì?" và "Nói cho tôi biết thủ đô của Pháp" có ý nghĩa tương tự, chúng sẽ được định hướng đến cùng một câu trả lời đã có sẵn.
Cơ chế này sử dụng embeddings (vector hóa) và độ tương đồng cosine. Tuy nhiên, nó đi kèm nhiều rủi ro và thách thức:
- Xác định ngưỡng tương đồng (threshold).
- Xử lý thông tin lỗi thời (TTL - Time to Live).
- Phân tách người dùng và ngữ cảnh phiên làm việc.
Semantic caching phù hợp với các bot Q/A có nhiều câu hỏi lặp lại, nhưng ít hiệu quả với các bot coding có các yêu cầu độc nhất.
Không tải trước các token "ngủ đông"
Khi hệ thống prompt phát triển do quá nhiều công cụ hoặc bộ nhớ phình to, việc giữ cho lớp luôn được tải (always-loaded layer) nhỏ gọn là rất quan trọng.
Lazy-loading Tools và MCP
Thay vì đổ mọi định nghĩa công cụ vào prompt ngay từ đầu, hãy chỉ tải chúng khi cần thiết. Anthropic có tính năng "Advanced Tool Search" cho phép mô hình tìm kiếm công cụ thay vì định nghĩa tất cả lên front.
Ví dụ, bạn có thể định nghĩa một công cụ tìm kiếm tool_search và trì hoãn việc tải các công cụ cụ thể (defer_loading) cho đến khi chúng thực sự được gọi. Điều này giúp giữ cho ngữ cảnh ban đầu gọn nhẹ, cải thiện hiệu suất và giảm chi phí.
Sử dụng mô hình rẻ cho công việc rẻ
Nguyên tắc này liên quan đến việc định tuyến prompt đến các mô hình khác nhau dựa trên độ khó của nhiệm vụ.
Định tuyến (Routing)
Nhiều người cho rằng hơn 60% câu hỏi đến là các tác vụ đơn giản và không cần đến mô hình mạnh nhất (như các mô hình "thinking"). Các giải pháp như RouteLLM sử dụng một router nhỏ để quyết định xem nên gửi yêu cầu đến mô hình nào.
Tuy nhiên, việc xây dựng một router chất lượng cao là khó khăn. Nhiều router phức tạp không tốt hơn nhiều so với các phương pháp cơ bản như heuristic hoặc keyword matching.
Xếp tầng (Cascading)
Thay vì đoán độ khó từ prompt, hãy để mô hình rẻ thử trả lời trước. Sau đó, một bộ kiểm tra nhẹ (checker) sẽ đánh giá độ tin cậy của câu trả lời dựa trên logprobs hoặc entropy. Nếu độ tin cậy thấp, hệ thống sẽ chuyển yêu cầu lên mô hình lớn hơn và đắt tiền hơn.
Phương pháp này có thể cắt giảm 50% chi phí nếu phần lớn câu hỏi có thể được xử lý bởi mô hình nhỏ.
 Định tuyến và xếp tầng mô hình
Định tuyến và xếp tầng mô hình
Ủy quyền cho Subagents
Subagents (tác nhân con) giúp cô lập các nhiệm vụ. Ví dụ, Claude Code sử dụng tác nhân con "Explore" chạy trên mô hình Haiku rẻ tiền để tìm kiếm codebase. Mặc dù tiết kiệm được chi phí, lợi ích lớn nhất của subagents là giữ cho ngữ cảnh chính sạch sẽ và tập trung.
Giữ cho ngữ cảnh sạch sẽ
Kỹ thuật ngữ cảnh tốt không chỉ giúp cải thiện hiệu suất mà còn tiết kiệm chi phí. Các tác nhân AI thường có xu hướng tích lũy "rác": đầu ra của công cụ, nhật ký, quan sát lặp lại và các lý luận cũ.
Nén ngữ cảnh (Context Compaction)
Thay vì giữ mọi thứ trong ngữ cảnh hoạt động, bạn cần xây dựng một quy trình trạng thái (state pipeline) để lưu trữ dữ liệu thô vào kho lưu trữ (archive) và chỉ giữ những gì thực sự cần thiết trong ngữ cảnh hoạt động.
Ví dụ, thay vì đổ toàn bộ kết quả test log vào prompt, hãy chỉ tóm tắt các bài test thất bại và các tệp liên quan. Các nghiên cứu cho thấy việc nén ngữ cảnh có thể giảm 51,8–71,3% ngân sách token đồng thời cải thiện tỷ lệ giải quyết vấn đề.
Kết luận
Xây dựng tác nhân AI hiệu quả về chi phí đòi hỏi sự kết hợp của nhiều chiến lược:
- Sử dụng Prompt caching cho các hệ thống prompt lớn và tĩnh.
- Áp dụng Semantic caching cho các bot Q/A phổ thông.
- Thử nghiệm Routing và Cascading để phân bổ tác vụ phù hợp với mô hình.
- Luôn giữ ngữ cảnh sạch sẽ bằng cách loại bỏ các dữ liệu thừa.
Tùy thuộc vào trường hợp sử dụng của bạn, việc áp dụng đúng một hoặc kết hợp các nguyên tắc này sẽ mang lại lợi ích kinh tế đáng kể cho dự án của bạn.
Bài viết liên quan

Công nghệ
Vượt xa Prompt Engineering: Kiến tạo Hệ thống AI có Nhận thức Ngữ cảnh và Quản lý Bộ nhớ ở Quy mô lớn
10 tháng 6, 2026

Công nghệ
Tổng hợp thị trường M&A an ninh mạng: 33 thương vụ được công bố trong tháng 4/2026
04 tháng 5, 2026

Công nghệ
Anthropic và OpenAI mang cuộc chiến công nghệ sang chính trường Mỹ
20 tháng 5, 2026