
Apache Flink: Khi xử lý luồng dữ liệu trở thành xương sống của hệ thống gợi ý thời gian thực
Apache Flink đang thay đổi cách các ông lớn như Netflix hay Alibaba xử lý dữ liệu. Bài viết này sẽ đi sâu vào kiến trúc của Flink, lý do tại sao nó thống nhất xử lý theo lô và theo luồng, cũng như cách xây dựng một hệ thống gợi ý thời gian thực hiệu quả.

Apache Flink đã từ lâu nằm trong danh sách những công nghệ mà tôi thực sự cần phải hiểu rõ. Tôi thường thấy cái tên này xuất hiện cùng với Kafka, được nhắc đến trong các cuộc thảo luận về pipeline dữ liệu thời gian thực, và đại khái hiểu được use case của nó. Nhưng tôi chưa bao giờ thực sự ngồi xuống để học nó một cách bài bản.
Nếu bạn cũng cảm thấy giống như vậy, bạn không đơn độc. Có rất nhiều lý do để tìm hiểu về Flink — đây là một trong những công cụ phổ biến nhất trong kỹ thuật phần mềm hiện nay. Netflix sử dụng nó để phát hiện bất thường gần như thời gian thực trong cơ sở hạ tầng streaming. Alibaba reportedly vận hành một trong các hệ thống Flink lớn nhất thế giới — xử lý hàng trăm tỷ sự kiện mỗi ngày trên hàng chục nghìn máy chủ. Uber xây dựng nền tảng phân tích của họ dựa trên nó. Flink đã trở thành xương sống cho cách các công ty dữ liệu lớn nhất thế giới xử lý thông tin ngay khi nó diễn ra.
 Minh họa người dùng công nghệ
Minh họa người dùng công nghệ
Vì vậy, tôi đã quyết định tìm hiểu sâu hơn. Và tôi thực sự ngạc nhiên không chỉ bởi Flink là gì, mà còn bởi lý do tồn tại và cách nó được xây dựng. Câu chuyện của Flink thực chất là câu chuyện về một ý tưởng sâu sắc hơn nhiều: ý tưởng về cách hiểu dữ liệu luồng liên tục ở quy mô lớn. Vấn đề đặt ra khá đơn giản: làm thế nào để xây dựng các câu trả lời thực tế và hữu ích từ một dòng dữ liệu khổng lồ và liên tục. Bài viết này là nỗ lực của tôi để giải thích ý tưởng đó từ đầu, và cho bạn thấy Flink phù hợp vào đâu trong bức tranh đó.
Hãy cùng bắt đầu nào.
Luồng (Stream) và Xử lý theo lô (Batch Processing)
Trước khi đi sâu, chúng ta cần thống nhất hai khái niệm cốt lõi này.
Luồng (Stream) là gì? Một luồng là một chuỗi các bản ghi liên tục, có thể không bao giờ kết thúc, đến theo thời gian. Hãy tưởng tượng một người dùng đang duyệt web — mỗi lần xem trang, mỗi lần nhấp chuột, mỗi lần cuộn trang là một sự kiện được tạo ra. Lần lượt nối tiếp nhau, theo thời gian thực. Không có điểm "kết thúc" tự nhiên nào ở đây — miễn là người dùng còn hoạt động, sự kiện vẫn tiếp tục đến. Đó là một luồng.
Xử lý theo lô (Batch Processing) là gì? Xử lý theo lô có nghĩa là lấy một tập hợp dữ liệu hữu hạn, có giới hạn và xử lý tất cả cùng một lúc. Thay vì phản ứng với từng sự kiện khi nó đến, bạn thu thập sự kiện trong một khoảng thời gian — ví dụ, một giờ — và sau đó chạy tính toán trên tất cả chúng cùng lúc. Tính toán có điểm bắt đầu rõ ràng và điểm kết thúc rõ ràng.
 Minh họa khái niệm dữ liệu
Minh họa khái niệm dữ liệu
Cả hai đều là những cách hợp lệ để xử lý dữ liệu. Sự căng thẳng giữa chúng là điều mà Flink được xây dựng để giải quyết — và chúng ta sẽ đến với điều đó.
Vấn đề: Chúng ta thực sự tạo ra dữ liệu như thế nào?
Hãy làm rõ vấn đề này với một ví dụ mà chúng ta sẽ sử dụng xuyên suốt bài viết.
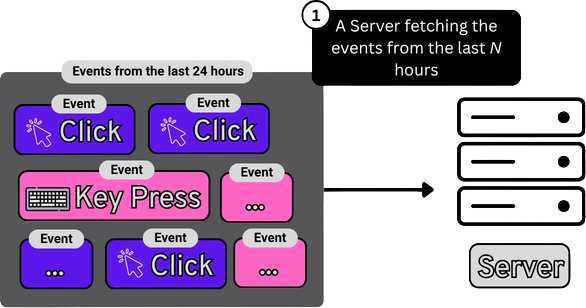
Hãy tưởng tượng bạn đang xây dựng một hệ thống gợi ý (recommendation engine) — loại hệ thống hiển thị cho người dùng "có thể bạn cũng thích những thứ này" dựa trên những gì họ đã xem. Để làm tốt điều này, hệ thống của bạn cần biết những thứ như: Người dùng này đã nhấp vào gì trong vài phút qua? Những mặt hàng nào đang thịnh hành ngay bây giờ trên tất cả người dùng? Người dùng đã xem nhưng không mua sản phẩm nào trong phiên gần nhất?
Dữ liệu đó đến từ đâu? Mỗi khi người dùng mở trang sản phẩm, bạn ghi lại một sự kiện. Mỗi lần nhấp chuột, mỗi lần mua hàng, mỗi lần tìm kiếm — ứng dụng của bạn liên tục ghi các bản ghi trông giống như sau:
{ "user_id": "u-8821", "item_id": "p-443", "event_type": "view", "timestamp": "2024–03–10T14:32:01Z" }
{ "user_id": "u-1042", "item_id": "p-117", "event_type": "purchase", "timestamp": "2024–03–10T14:32:03Z" }
Một bản ghi mỗi vài giây cho mỗi người dùng, trên hàng triệu người dùng đồng thời, liên tục. Đó là dữ liệu của bạn. Không phải là một tệp tin. Không phải là một bảng cập nhật một lần một ngày. Đó là một luồng — một chuỗi sự kiện không bao giờ kết thúc mô tả những gì người dùng của bạn đang làm ngay lúc này.
Tuy nhiên, mô hình chiếm ưu trị trong nhiều năm là lấy luồng đó và... bỏ qua thực tế rằng nó là một luồng. Đổ sự kiện vào các tệp mỗi giờ. Chờ công việc theo lô chạy. Sau đó phục vụ các gợi ý dựa trên những gì người dùng làm vào giờ trước.
Tại sao? Vì xử lý theo lô về mặt khái niệm thì đơn giản. Bạn biết chính xác mình có dữ liệu gì. Bạn có thể lý luận rõ ràng về tính toán — nó bắt đầu, chạy và kết thúc. Các hệ thống như Hadoop và MapReduce được xây dựng xung quanh mô hình này và mở rộng quy mô lên kích thước dữ liệu khổng lồ. Chúng hoạt động tốt.
Nhưng có một chi phí cơ bản: độ trễ (latency). Nếu công việc theo lô của bạn chạy mỗi giờ, thì trong trường hợp xấu nhất, hành vi của người dùng ngay lúc này sẽ không ảnh hưởng đến gợi ý của họ cho đến một giờ sau. Đối với hệ thống gợi ý, điều này có nghĩa là một người dùng vừa thể hiện sự quan tâm mạnh mẽ đến đồ đi bộ đường dài lại được hiển thị phụ kiện máy tính xách tay — vì hệ thống chưa kịp cập nhật. Người dùng tìm kiếm ba lô đi bộ đường dài, và bạn cần hiển thị cho họ lều và gậy đi bộ đường dài ở lần tải trang tiếp theo, chứ không phải một giờ sau.
Đối với phát hiện gian lận, độ trễ một giờ có nghĩa là các giao dịch gian lận không được phát hiện trong một giờ. Đối với bảng điều khiển trực tiếp, điều này có nghĩa là số liệu "thời gian thực" của bạn có thể bị cũ đến 59 phút. Chi phí của xử lý theo lô là sự kiện xảy ra theo thời gian thực, nhưng hệ thống của bạn chỉ biết về chúng theo lịch trình.
Khi khối lượng dữ liệu tăng lên và yêu cầu về độ trễ trở nên khắt khe hơn, các kỹ sư bắt đầu xây dựng các hệ thống xử lý luồng song song với các hệ thống theo lô của họ — các hệ thống có thể xử lý từng sự kiện khi nó đến, trong vài mili-giây. Apache Storm là người tiên phong ở đây. Amazon Kinesis. LinkedIn’s Samza.
Nhưng việc xây dựng một hệ thống xử lý luồng mới, trong khi duy trì hệ thống theo lô hiện có, không hề đơn giản. Bây giờ bạn có hai hệ thống để bảo trì. Pipeline luồng của bạn tính toán kết quả gần đúng, thời gian thực. Pipeline theo lô của bạn chạy qua đêm và tạo ra kết quả chính xác, hoàn chỉnh. Bạn phải viết cùng một logic kinh doanh hai lần — một lần cho mỗi hệ thống, trong các khung công việc khác nhau, bằng các ngôn ngữ khác nhau, và giữ đồng bộ hóa thủ công. Khi công việc theo lô và công việc luồng không đồng nhất về một con số (và chúng luôn không đồng nhất vào một lúc nào đó), bạn phải tìm ra cái nào sai.
Hệ thống gợi ý của bạn trong thế giới mới này bây giờ trông như thế này: một thành phần luồng cập nhật gợi ý gần như thời gian thực dựa trên các sự kiện gần đây, và một thành phần theo lô xây dựng lại mô hình gợi ý đầy đủ mỗi đêm dựa trên dữ liệu lịch sử.
Hai cơ sở mã. Hai pipeline triển khai. Hai tập hợp lỗi. Một lớp phục vụ cố gắng hòa giải chúng.
Sự thấu hiểu then chốt: Batch chỉ là một trường hợp đặc biệt của Streaming
Đây là ý tưởng nằm ở trái tim của Flink, và nó khá đơn giản:
Một tập dữ liệu có giới hạn chỉ là một trường hợp đặc biệt của một luồng dữ liệu không giới hạn tình cờ kết thúc.
Cơ sở dữ liệu lịch sử 5 năm về sự kiện của người dùng — đó là một luồng bắt đầu 5 năm trước và dừng lại hôm nay. Các tệp nhật ký của tháng trước — đó là một luồng có điểm bắt đầu và điểm kết thúc. Sự khác biệt giữa "dữ liệu theo lô" và "dữ liệu luồng" không phải là một sự phân biệt cơ bản về bản chất của dữ liệu. Cuối cùng, nó chỉ là các sự kiện JSON về những gì người dùng đã tìm kiếm và nhấp vào. Câu hỏi là liệu luồng đó vẫn đang chảy hay đã dừng lại.
Quay lại hệ thống gợi ý của chúng ta: "dữ liệu lịch sử" mà bạn xử lý trong công việc theo lô hàng đêm và "sự kiện thời gian thực" mà bạn xử lý trong pipeline luồng đều chỉ là các bản ghi trong cùng một chuỗi sự kiện của người dùng. Sự khác biệt duy nhất là khi bạn đọc chúng. Công việc theo lô hàng đêm đọc các bản ghi từ 6 tháng trước. Pipeline luồng đọc các bản ghi từ 6 giây trước. Cùng dữ liệu, cửa sổ thời gian khác.
Nếu bạn xây dựng một hệ thống xử lý luồng một cách tự nhiên — và xử lý cả luồng vô hạn và luồng hữu hạn — bạn không cần các hệ thống riêng biệt. Bạn không cần duy trì hai cơ sở mã. Bạn có một động cơ, một tập hợp logic, và bạn trỏ nó vào bất kỳ phần nào của luồng mà bạn cần.
Đó chính là những gì Flink cố gắng làm.
Vậy Apache Flink là gì?
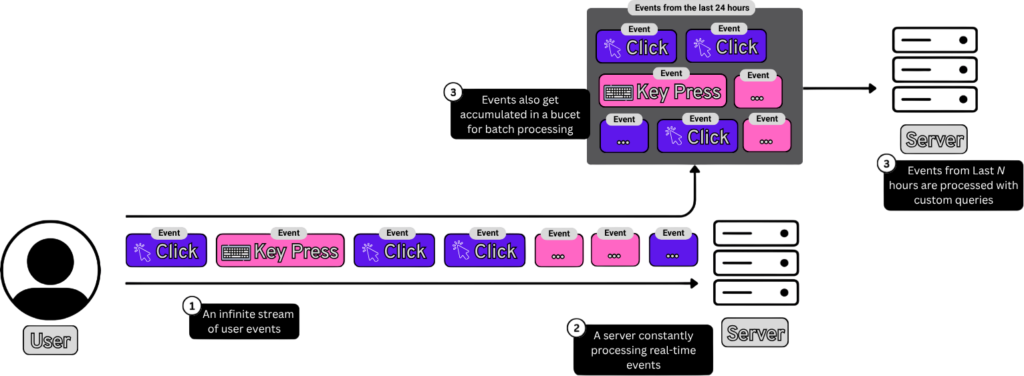
Apache Flink là một khung xử lý luồng phân tán (distributed stream processing framework). Nó nhận một luồng dữ liệu có khả năng không giới hạn (hoặc một lô dữ liệu có giới hạn — cùng một thứ), xử lý song song trên một cụm máy, và tạo ra kết quả liên tục khi dữ liệu chảy qua.
 Minh họa kiến trúc hệ thống
Minh họa kiến trúc hệ thống
Bên trong, các công việc Flink được viết bằng mã và được chuyển đổi thành một đồ thị có hướng không chu trình (DAG). Ví dụ, đối với hệ thống gợi ý của chúng ta, mã sẽ bao gồm các bước như đọc từ Kafka, tổng hợp hoạt động người dùng theo cửa sổ thời gian, gọi mô hình AI để tạo embedding, tìm kiếm ứng viên, xếp hạng và ghi kết quả vào Redis.
Flink chia nhỏ mã này thành một đồ thị các tác vụ vật lý để thực hiện và chia các tác vụ này thành tập hợp các "tác vụ con" song song nhỏ hơn. Flink đẩy các tác vụ này đến các nút worker. Mỗi worker chạy các tác vụ được giao liên tục, gửi các heartbeat định kỳ lại cho Flink và báo cáo nếu một tác vụ thất bại để Flink có thể khởi động lại nó.
Các khái niệm cốt lõi của Flink
Luồng và Toán tử (Streams and Operators)
Mọi chương trình Flink đều là một đồ thị luồng dữ liệu: một tập hợp các toán tử được kết nối bởi các luồng dữ liệu.
- Nguồn (Sources) tạo ra dữ liệu (đọc từ Kafka, tệp, cơ sở dữ liệu).
- Toán tử (Operators) chuyển đổi nó.
- Đích (Sinks) tiêu thụ đầu ra (ghi vào cơ sở dữ liệu, chủ đề Kafka khác, bảng điều khiển).
Đối với hệ thống gợi ý của chúng ta, một toán tử có thể lọc lưu lượng bot, hoặc làm phong phú một sự kiện với siêu dữ liệu sản phẩm, hoặc đếm số lần mỗi sản phẩm được xem.
Tính song song (Parallelism)
Một máy đơn có thể xử lý sự kiện nhanh — nhưng nếu bạn xử lý hàng triệu người dùng, một máy là không đủ. Flink giải quyết điều này bằng cách chạy mọi toán tử song song: mỗi toán tử được chia thành nhiều tác vụ con chạy đồng thời trên các máy khác nhau trong cụm của bạn.
Nếu bạn có một Toán tử Lọc với tính song song là 4, sẽ có 4 phiên bản chạy đồng thời, mỗi phiên xử lý một phần khác nhau của luồng. Thêm máy chủ, nhận thêm tác vụ con, xử lý khối lượng lớn hơn. Đó là cách Flink mở rộng quy mô lên hàng tỷ sự kiện mỗi ngày.
Trạng thái (State)
Quay lại hệ thống gợi ý của chúng ta: khi người dùng xem một sản phẩm, sự kiện đơn lẻ đó tự nó hầu như không nói lên gì. Bạn cần ngữ cảnh. Người dùng đó còn xem gì trong vài phút qua? Họ có đang xem các sản phẩm cùng danh mục không? Họ đã gần mua thứ gì tương tự trong phiên trước không? Để trả lời những câu hỏi này, hệ thống của bạn cần bộ nhớ — nó cần nhớ những gì đã xảy ra trước đó.
Flink biến trạng thái thành một khái niệm hạng nhất. Một toán tử có thể khai báo trạng thái một cách rõ ràng — một bộ đếm, một bản đồ băm được khóa theo ID người dùng, một danh sách được sắp xếp các sự kiện gần đây. Flink cung cấp cho bạn trạng thái đó như một đối tượng được quản lý mà bạn có thể đọc và ghi trong quá trình xử lý.
Nhưng quản lý trạng thái trong một hệ thống phân tán thực sự khó khăn. Điều gì xảy ra khi máy chạy toán tử của bạn bị sập? Bản đồ băm trong bộ nhớ đó sẽ biến mất. Flink xử lý việc này: nó định kỳ chụp nhanh tất cả trạng thái toán tử vào lưu trữ bền vững, vì vậy khi khôi phục, nó có thể khôi phục mọi thứ về trạng thái trước khi thất bại. Và nó đảm bảo các cập nhật trạng thái được áp dụng chính xác một lần — ngay cả khi máy bị sập và cùng một sự kiện được phát lại trong quá trình khôi phục, số lượng của bạn sẽ không bị nhân đôi.
Cửa sổ (Windows)
Chúng ta có một luồng sự kiện người dùng, các toán tử chạy song song và trạng thái tích lũy theo từng người dùng. Bây giờ đây là một vấn đề phát sinh gần như ngay lập tức trong bất kỳ tổng hợp thực tế nào.
Giả sử bạn muốn tính toán "10 sản phẩm được xem nhiều nhất trong 5 phút qua" — để cung cấp năng lượng cho phần "đang thịnh hành" của trang web. Bạn có một toán tử đếm lượt xem theo sản phẩm. Nhưng luồng của bạn là vô hạn. Khi nào bạn phát ra kết quả? Bạn không thể đợi cho đến khi "tất cả các sự kiện" đến — chúng không bao giờ ngừng đến.
Bạn cần một cách để cắt luồng vô hạn thành các mảnh hữu hạn và tính toán trên từng mảnh. Đó chính là cửa sổ (window).
Một cửa sổ là một mảnh có giới hạn của luồng của bạn. Bạn xác định nó, Flink nhóm các sự kiện vào mảnh đó, và khi mảnh đó "hoàn thành", nó chạy tổng hợp của bạn và phát ra kết quả. Flink có một số loại cửa sổ như Cửa sổ lăn (Tumbling), Cửa sổ trượt (Sliding), Cửa sổ phiên (Session), v.v.
Khả năng chịu lỗi và Đảm bảo Exactly-Once
Một trong những điểm mạnh nhất của Flink là khả năng chịu lỗi. Bài báo gốc năm 2015 về Flink mô tả ngữ nghĩa chính xác một lần (exactly-once semantics) như sau: "Flink cung cấp các đảm bảo tính nhất quán xử lý chính xác một lần nghiêm ngặt cho các toán tử có trạng thái thông qua sự kết hợp của các ảnh chụp nhanh phân tán và thực thi lại một phần khi khôi phục."
Cơ chế giúp việc này hoạt động mà không cần tạm dừng tính toán được gọi là Chụp nhanh rào cản không đồng bộ (Asynchronous Barrier Snapshotting - ABS). Flink đưa các đánh dấu "rào cản" đặc biệt vào luồng dữ liệu, chúng chảy qua các toán tử giống như các bản ghi thông thường. Khi toán tử nhận được rào cản, nó chụp nhanh trạng thái của mình vào lưu trữ bền vững và chuyển tiếp rào cản xuống dòng — tất cả trong khi tiếp tục xử lý các bản ghi. Không tạm dừng, không đóng băng, không sự kiện nào bị bỏ lỡ.
Kết luận
Hãy tóm tắt lại ngắn gọn:
- Dữ liệu được tạo ra dưới dạng các luồng liên tục, nhưng chúng ta đã historically ép buộc nó vào các lô — tạo ra độ trễ và nỗi đau vận hành của việc duy trì hai hệ thống.
- Flink được xây dựng dựa trên sự thấu hiểu rằng xử lý theo lô chỉ là một trường hợp đặc biệt của xử lý luồng — và thống nhất cả hai trong một động cơ duy nhất.
- Các khối xây dựng cốt lõi bao gồm: toán tử (logic xử lý), luồng (dữ liệu đang chuyển động), trạng thái (bộ nhớ tồn tại qua các bản ghi), và cửa sổ (các lát cắt có giới hạn của luồng để tính toán).
- Khả năng chịu lỗi với các đảm bảo chính xác một lần được tích hợp sẵn sẵn.
Với Flink, kiến trúc Lambda phức tạp — với hai hệ thống và hai cơ sở mã — đơn giản là không còn cần thiết nữa. Bạn có một động cơ để xử lý tất cả dữ liệu của mình, dù đó là lịch sử hay thời gian thực.

