
Bài học thực tế: Xây dựng bộ chuẩn hóa OpenTelemetry cho Generative AI
Bài viết chia sẻ hành trình kỹ thuật của groundcover khi xây dựng giải pháp giám sát AI (AI Observability) độc lập với SDK và nhà cung cấp. Mặc dù OpenTelemetry (OTel) được coi là tiêu chuẩn chung, thực tế lại tồn tại sự hỗn loạn trong dữ liệu từ các SDK, framework và LLM khác nhau, đòi hỏi một bộ chuẩn hóa phức tạp để thống nhất telemetry.
Mọi người đều nói rằng họ hỗ trợ OpenTelemetry. Tuy nhiên, thực tế là không ai phát ra các thuộc tính (attributes) dữ liệu theo một cách giống hệt nhau.
Bài đăng trên blog này sẽ chia sẻ những gì các kỹ sư tại groundcover đã học được trong quá trình chúng tôi xây dựng một giải pháp AI Observability (giám sát AI) không phụ thuộc vào SDK, Framework hay Nhà cung cấp GenAI cụ thể nào.
Xây dựng giải pháp quan sát cho GenAI
Một trong những giá trị cốt lõi của groundcover là việc thu thập dữ liệu quan sát (o11y data) cần phải đơn giản và không bị giới hạn. Chúng tôi tin rằng các kỹ sư SRE nên tập trung vào việc xử lý sự cố và phân tích nguyên nhân gốc rễ (root cause analysis), thay vì lo lắng về việc instrumentation, xử lý dữ liệu hay các khoảng trống dữ liệu.
Chúng tôi aimed để làm cho việc giám sát AI với OTel trở nên đơn giản như việc thu thập dữ liệu Infra, APM và RUM bằng cảm biến eBPF của chúng tôi hiện nay. Quá trình này đã giúp chúng tôi nhận ra rằng có rất nhiều rào cản liên quan đến instrumentation truyền thống.
Tiêu chuẩn OTel trong GenAI thực tế như thế nào?
Có một câu chuyện an ủi trong lĩnh vực giám sát AI rằng: "OpenTelemetry đã có các quy ước ngữ nghĩa (semantic conventions) cho GenAI, các SDK đang áp dụng chúng, và sớm thôi mọi cuộc gọi LLM sẽ phát ra cùng một tiêu chuẩn telemetry. Chỉ cần cắm bất kỳ backend nào, bạn sẽ có được khả năng quan sát thống nhất."
Chúng tôi cũng từng tin vào câu chuyện này. Sau đó, chúng tôi thử thực sự xây dựng nó cho tính năng AI Observability và Agent Mode của mình — một trợ lý quan sát dạng tác nhân (agentic observability) giúp bạn xử lý sự cố bằng cách thực hiện phân tích nguyên nhân gốc rễ ngay trong đám mây của riêng bạn.
Chúng tôi đã dành nhiều tuần để xây dựng một bộ normalizer (chuẩn hóa) tiêu thụ các span GenAI từ mọi SDK instrumentation lớn và tạo ra một chế độ xem chuẩn (canonical view) duy nhất cho bất kỳ dữ liệu GenAI nào — bao gồm model, tokens, chi phí, tin nhắn và lệnh gọi công cụ — bất kể SDK nào đã phát ra span hoặc nhà cung cấp LLM nào được gọi.
Những gì chúng tôi tìm thấy là "tiêu chuẩn" thực chất chỉ giống như một "gợi ý", và thế giới thực là một mê cung của các xung đột đặt tên, sự không khớp về cấu trúc và các đặc thù riêng của từng nhà cung cấp mà việc đọc spec không thể chuẩn bị cho bạn được.
Ba trục của sự phức tạp
Sự phức tạp không chỉ là một chiều. Có ba vectơ độc lập kết hợp lại để tạo ra dữ liệu telemetry mà chúng tôi cần chuẩn hóa:
- Instrumentation SDKs: Cách telemetry được phát ra. Traceloop, LangSmith, các instrumentation OTel chính thức, hoặc các thuộc tính
gen_ai.*thủ công. Mỗi SDK phát ra các tên thuộc tính khác nhau, định dạng tin nhắn khác nhau và cách đặt tên trường token khác nhau. - Orchestration frameworks: Cách quy trình làm việc của tác nhân (agent workflow) được cấu trúc. LangGraph, CrewAI, Pydantic AI, AutoGen, Semantic Kernel, hoặc các cuộc gọi SDK thô không có framework. Framework xác định hình dạng cây span (các cuộc gọi LLM phẳng so với phân cấp tác nhân sâu → nhiệm vụ → công cụ).
- LLM providers: Ai đang được gọi. OpenAI, Anthropic, Bedrock, Gemini, Groq, Mistral. Mỗi nhà cung cấp có định dạng API riêng, ngữ nghĩa token riêng (ví dụ: "input tokens" có bao gồm cache không?), cấu trúc tin nhắn riêng và định dạng lệnh gọi công cụ riêng.
Nói cách khác, sự kết hợp LangGraph + Traceloop + Anthropic tạo ra telemetry khác với LangGraph + Traceloop + OpenAI (trục nhà cung cấp), lại khác với telemetry của CrewAI + Traceloop + OpenAI (trục framework), và cũng khác với CrewAI + LangSmith + OpenAI (trục SDK). Ma trận đầy đủ là SDK × Framework × Provider.
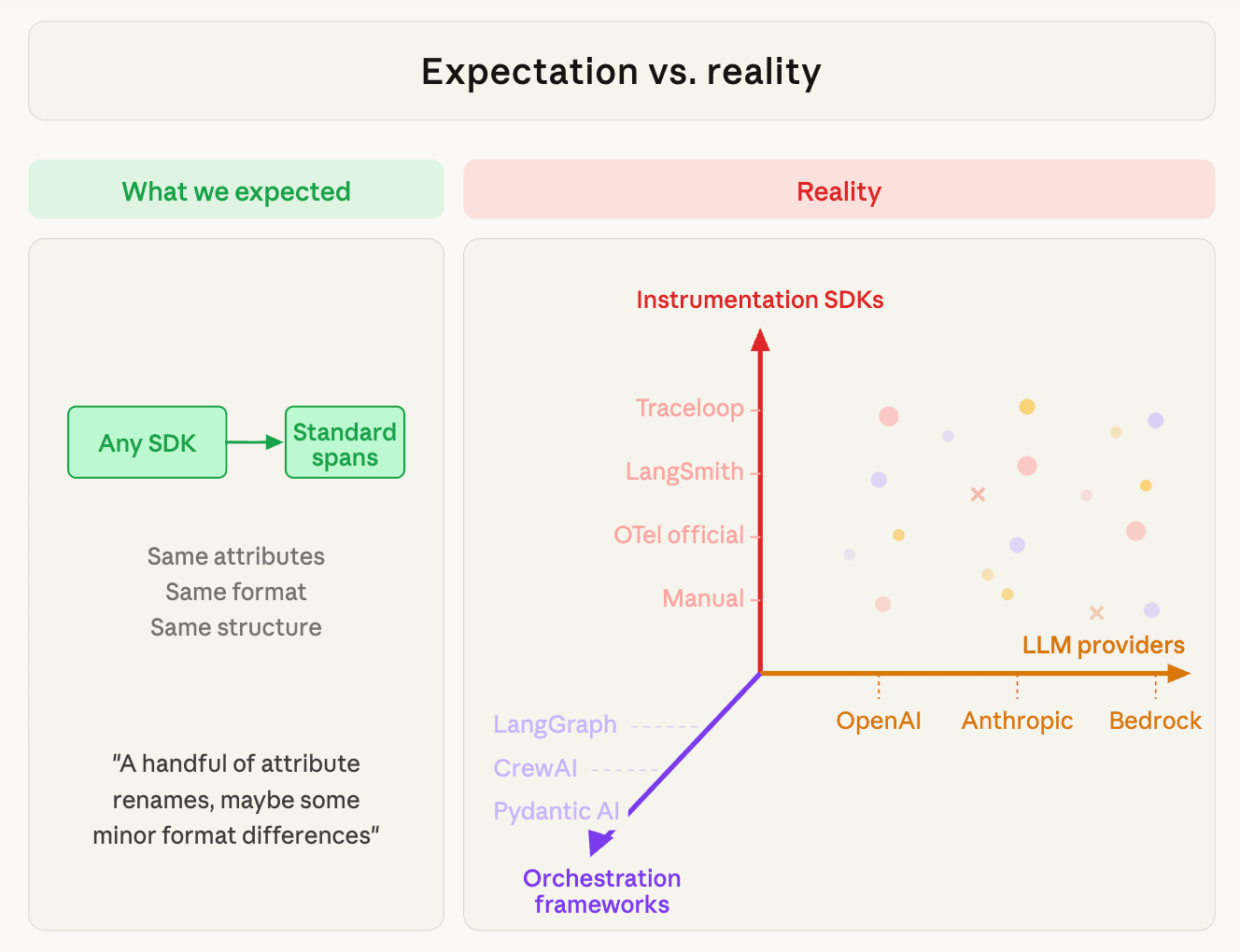 Ba trục của sự phức tạp trong GenAI telemetry
Ba trục của sự phức tạp trong GenAI telemetry
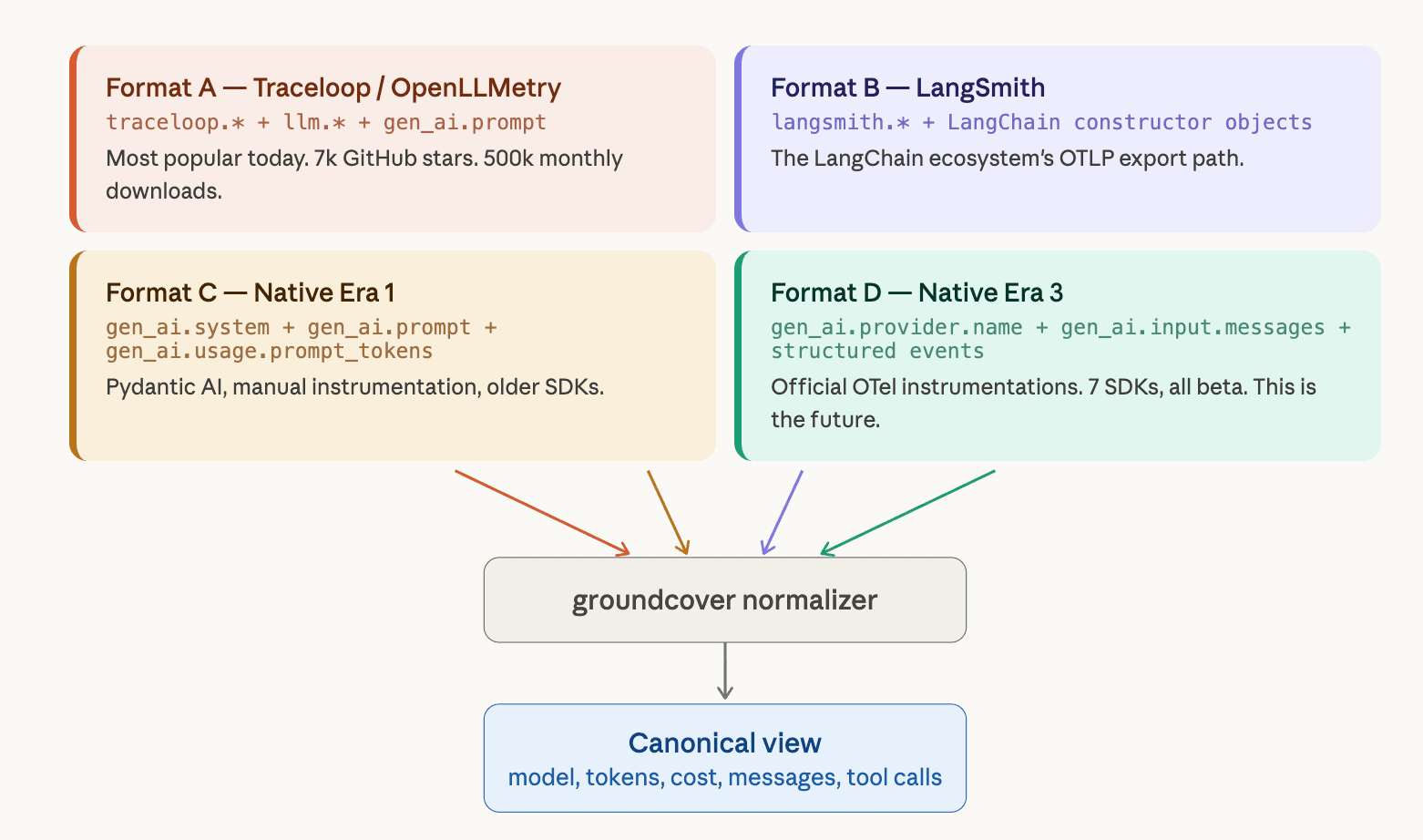
Bốn định dạng dữ liệu (Wire Formats)
Mọi span GenAI đi vào đường ống của chúng tôi đều đến từ một trong bốn định dạng:
Việc phát hiện xem một span sử dụng định dạng nào là bước đầu tiên. Chúng tôi quét các tiền tố khóa thuộc tính. Ví dụ, langsmith.* là xác định cho Định dạng B. Trong khi traceloop.* hoặc llm.* là xác định cho Định dạng A.
Sau đó, mỗi định dạng có logic trích xuất riêng, trình phân tích cú pháp tin nhắn riêng và bước xử lý hậu kỳ riêng trước khi mọi thứ hội tụ vào một cấu trúc Field duy nhất.
Ví dụ thực tế về sự hỗn loạn dữ liệu
"Bạn đang dùng Model nào?" - Sáu cách để nói cùng một điều
Câu hỏi đơn giản nhất trong giám sát AI: Model nào đã xử lý yêu cầu này? Dưới đây là sáu nguồn khác nhau đặt câu trả lời ở đâu:
Bộ normalizer của chúng tôi giải quyết vấn đề này bằng một chuỗi ưu tiên:
gen_ai.request.modelđã có trên span chưa? Dùng nó.- Siêu dữ liệu chi phí được trích xuất từ tin nhắn JSON của LangChain? Dùng cái đó.
llm.request.modelcó hiện diện? Dùng làm dự phòng.traceloop.association.properties.ls_model_name? Đây là giải pháp cuối cùng.
"Bao nhiêu Tokens?" - Sự hỗn loạn trong đặt tên
Đếm token là nền tảng của việc theo dõi chi phí AI. Dưới đây là những gì hệ sinh thái thực sự phát ra:
Năm quy ước đặt tên cho cùng một chỉ số. Bộ normalizer của chúng tôi giải quyết chúng bằng chuỗi ưu tiên ba tầng: tên chuẩn thắng hơn siêu dữ liệu chi phí từ tin nhắn LangChain, cái này thắng hơn tên gọi prompt_tokens/completion_tokens cũ.
Chuẩn hóa chi phí - Khi các nhà cung cấp không đồng thuận về định nghĩa "Input Tokens"
Anthropic và OpenAI đều báo cáo việc sử dụng token. Họ không đồng ý về ý nghĩa của con số đó.
Nếu bạn không biết rằng các Nhà cung cấp đếm token khác nhau, công thức tính chi phí của bạn sẽ âm thầm undercount (đếm thiếu) mọi cuộc gọi đánh vào prompt cache.
Bộ normalizer của chúng tôi mang theo một tập hợp cacheAdditiveProviders:
var cacheAdditiveProviders = map[string]bool{
"anthropic": true,
"aws.bedrock": true,
}
Đối với các nhà cung cấp này, cache token được cộng lại vào input_tokens để tính toán chi phí hạ nguồn ((input - cache_read - cache_creation) * price) tạo ra kết quả chính xác. Đối với OpenAI, không cần điều chỉnh vì tổng số đã bao gồm cache token.
Các backend "OTel chung chung" không xử lý được phép tính token cụ thể theo nhà cung cấp. Bạn cần normalization để giám sát việc sử dụng token một cách đáng tin cậy.
"Ai là Nhà cung cấp?" - 26 cách viết của 15 cái tên
Các SDK khác nhau phát ra tên nhà cung cấp theo các cách khác nhau. Cùng một nhà cung cấp, các chuỗi khác nhau:
 Bản đồ ánh xạ nhà cung cấp
Bản đồ ánh xạ nhà cung cấp
Hai mươi sáu giá trị đầu vào, mười lăm đầu ra chuẩn. Phân biệt hoa thường, viết tắt, tên thay thế — thế giới thực không tôn trọng enums. Và danh sách này tiếp tục tăng khi các nhóm áp dụng các cổng AI và proxy (LiteLLM, Portkey, OpenRouter) thêm nhiều máy chủ để nhận diện trên top các điểm cuối của nhà cung cấp trực tiếp.
Kết luận
Có một sự khác biệt lớn giữa "chúng tôi hỗ trợ OTel" và "chúng tôi tạo ra telemetry chính xác, thống nhất". Bộ normalizer OTel cho GenAI của groundcover hấp thụ sự phức tạp của các quy ước đặt tên khác nhau, số đếm token, tải trọng tin nhắn, tên nhà cung cấp và nhiều thứ khác để các nhóm DevOps có thể tập trung vào phân tích nguyên nhân gốc rễ.
Giám sát AI nên đơn giản như việc cài đặt một cảm biến eBPF, bất kể bạn chọn các nhà cung cấp, framework hay SDK nào.

