
Dữ liệu Synthetic vượt mọi bài kiểm tra nhưng vẫn làm hỏng mô hình: Những lỗ hổng thầm lặng
Dữ liệu tổng hợp thường vượt qua các bài kiểm tra chuẩn như độ lệch KL hay TSTR, nhưng vẫn thất bại trong môi trường thực tế. Bài viết chỉ ra ba lỗ hổng chính trong đánh giá dữ liệu: thiếu tương quan giữa các đặc trưng, bỏ qua các trường hợp hiếm (tail behavior), và đánh giá sai rủi ro riêng tư.

Dữ liệu Synthetic vượt mọi bài kiểm tra nhưng vẫn làm hỏng mô hình: Những lỗ hổng thầm lặng
Quy trình xử lý dữ liệu trông có vẻ vững chắc. Độ lệch KL (KL divergence) nằm trong phạm vi chấp nhận được. Trong bài kiểm tra "Huấn luyện trên Synthetic, Kiểm tra trên Real" (TSTR), mô hình đạt độ chính xác 91% khi được huấn luyện trên dữ liệu tổng hợp và kiểm tra trên dữ liệu thực, thấp hơn một chút so với 93% khi sử dụng dữ liệu thật — một sự chênh lệch nằm trong giới hạn cho phép mà nhóm đã thiết lập. Ngoài ra, rủi ro suy luận thành viên (membership inference) cũng tương đối thấp. Bộ dữ liệu tổng hợp được chứng nhận là an toàn để huấn luyện mô hình máy học; dữ liệu thực được lưu trữ an toàn; và mô hình đã được huấn luyện.
Tuy nhiên, ba tháng sau, mô hình phát hiện gian lận bắt đầu thất bại trong việc phát hiện các lớp giao dịch mà trước đây nó phát hiện không sót, không chỉ là giảm hiệu suất mà là hoàn toàn không thể phát hiện. Một nhóm toàn bộ các hành vi trường hợp ngoại lệ (edge-case) đã bị loại bỏ khỏi thực tế của mô hình.
Khi điều tra vấn đề, nhóm không tìm thấy lỗi kỹ thuật nào với dữ liệu tổng hợp. Tất cả các chỉ số mà nhóm chạy vẫn tiếp tục vượt qua.
Nhưng vấn đề là không một chỉ số nào trong số đó thực sự đo lường những gì thực sự quan trọng.
Khung Three Metric Framework và Tại sao Nó Gây Nhầm Lẫn cho Người Thực Thi
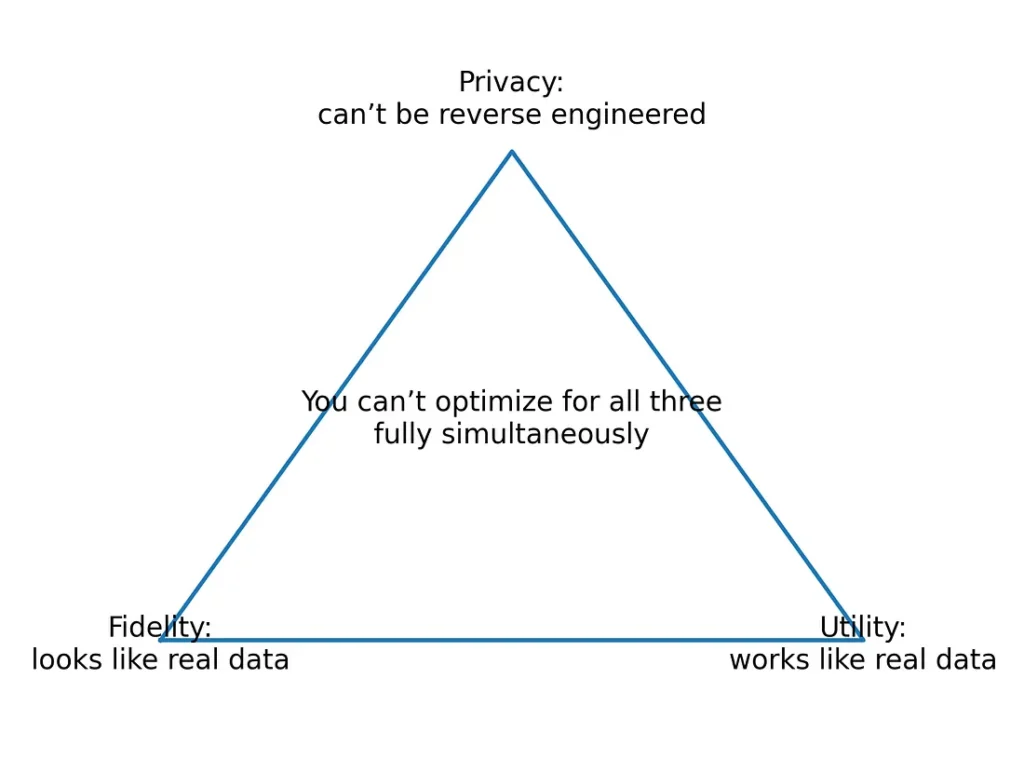
Tam giác tính trung thực - tính hữu dụng - quyền riêng tư (fidelity-utility-privacy) đã trở thành từ vựng chuẩn để đánh giá chất lượng dữ liệu tổng hợp và có lý do chính đáng cho điều đó. Nó nắm bắt ba khía cạnh của chất lượng mà bạn thực sự muốn đạt được: liệu dữ liệu tổng hợp có giống dữ liệu thật không (fidelity); liệu dữ liệu tổng hợp có huấn luyện các mô hình hoạt động tương tự như các mô hình được huấn luyện trên dữ liệu thật không (utility); và liệu dữ liệu tổng hợp có bảo vệ danh tính của những người mà dữ liệu gốc xuất phát từ đó không (privacy)?
Bản thân khung này là vững chắc. Tuy nhiên, việc thực hiện khung này là nơi phát sinh các vấn đề.
 Hình ảnh minh họa về khung đánh giá dữ liệu
Hình ảnh minh họa về khung đánh giá dữ liệu
Hầu hết các chuyên gia đánh giá ba chỉ số chất lượng một cách tuần tự, coi việc hoàn thành thành công mỗi chỉ số là đủ để triển khai. Cách tiếp cận này có khiếm khuyết vì ba lý do liên quan đan xen nhau đòi hỏi giải thích chi tiết:
Vấn đề #1: Các Chỉ số Fidelity Đánh giá Phân phối Biên, Không Phải Tương tác Giữa Các Đặc trưng
Các chỉ số fidelity được sử dụng thường xuyên nhất như Độ lệch KL, Kiểm tra Kolmogorov-Smirnov, Khoảng cách Biến thiên Tổng thể, Khoảng cách Wasserstein đều đo lường mức độ mà phân phối đặc trưng riêng lẻ trong bộ dữ liệu tổng hợp so sánh với bản gốc. Không một trong số các phép đo này đánh giá cách các đặc trưng tương quan với nhau.
Đây là một sự khác biệt tinh tế nhưng mang tính quyết định. Ví dụ, hãy xem xét một bộ dữ liệu y tế nơi phiên bản tổng hợp tái tạo chính xác phân phối biên của độ tuổi bệnh nhân và mức độ nghiêm trọng của bệnh — các phân phối biên xuất hiện gần như không thể phân biệt được. Nhưng có một sự khác biệt nhỏ trong mối tương quan giữa hai đặc trưng này trong dữ liệu tổng hợp. Kết quả là, khi một mô hình được huấn luyện trên nó, mô hình xác định các tín hiệu phù hợp riêng lẻ, nhưng lại có sự tương tác sai giữa các tín hiệu.
Vào năm 2025, một nghiên cứu được đánh giá ngang cấp về dữ liệu bệnh nhân tổng hợp đã đánh giá năm mô hình tạo sinh trên ba bộ dữ liệu lâm sàng. Kết quả cho thấy rằng mặc dù các phân phối biên hầu như luôn rất giống nhau, nhưng điểm tương quan chênh lệch tới 20 điểm hoặc hơn. Các tác động hạ nguồn là rất lớn: trên một bộ dữ liệu, các mô hình được huấn luyện trên dữ liệu tổng hợp cho giá trị diện tích dưới đường cong (AUC) khoảng 0,80, trong khi giá trị AUC khoảng 0,88 đạt được khi sử dụng dữ liệu thật. Biến số quyết định kết quả là việc bảo toàn tương quan thay vì độ trung thực của phân phối biên.
Để giải quyết vấn đề này: Chạy các bài kiểm tra KS và KL như đường cơ sở để xác nhận sự tương đồng của các phân phối biên. Luôn bao gồm sự so sánh các ma trận tương quan. Tính toán chuẩn Frobenius của sự khác biệt để nhận được một giá trị duy nhất đại diện cho lượng cấu trúc tương quan đã bị mất. Thiết lập ngưỡng cho mất mát cấu trúc tương quan trước khi tổng hợp dữ liệu, không phải sau đó.
import numpy as np
import pandas as pd
def correlation_drift_score(real_df: pd.DataFrame, synthetic_df: pd.DataFrame) -> float:
"""
Tính toán chuẩn Frobenius của sự khác biệt giữa
ma trận tương quan thật và tổng hợp.
Giá trị càng thấp càng tốt. Điểm số trên 0.5 đáng để điều tra.
"""
real_corr = real_df.corr().fillna(0).values
synth_corr = synthetic_df.corr().fillna(0).values
return np.linalg.norm(real_corr - synth_corr, 'fro')
score = correlation_drift_score(real_df, synthetic_df)
print(f"Correlation Drift Score: {score:.4f}")
Một con số. Hãy chạy nó mỗi lần. Nếu nó vượt quá ngưỡng của bạn, hãy quay lại bộ tạo trước khi làm bất cứ điều gì khác.
Vấn đề #2: Điểm TSTR Utility Che giấu Hành vi Đuôi Khi Chúng Chỉ Đại diện cho Hiệu suất Trung bình
Huấn luyện trên Dữ liệu Tổng hợp, Kiểm tra trên Dữ liệu Thật là một trong những chỉ số utility "tiêu chuẩn vàng", và nó xứng đáng với danh tiếng mà nó đã đạt được. Huấn luyện một mô hình trên dữ liệu tổng hợp và để nó hoạt động tốt trên dữ liệu thực chắc chắn là bằng chứng có ý nghĩa về tính hữu dụng.
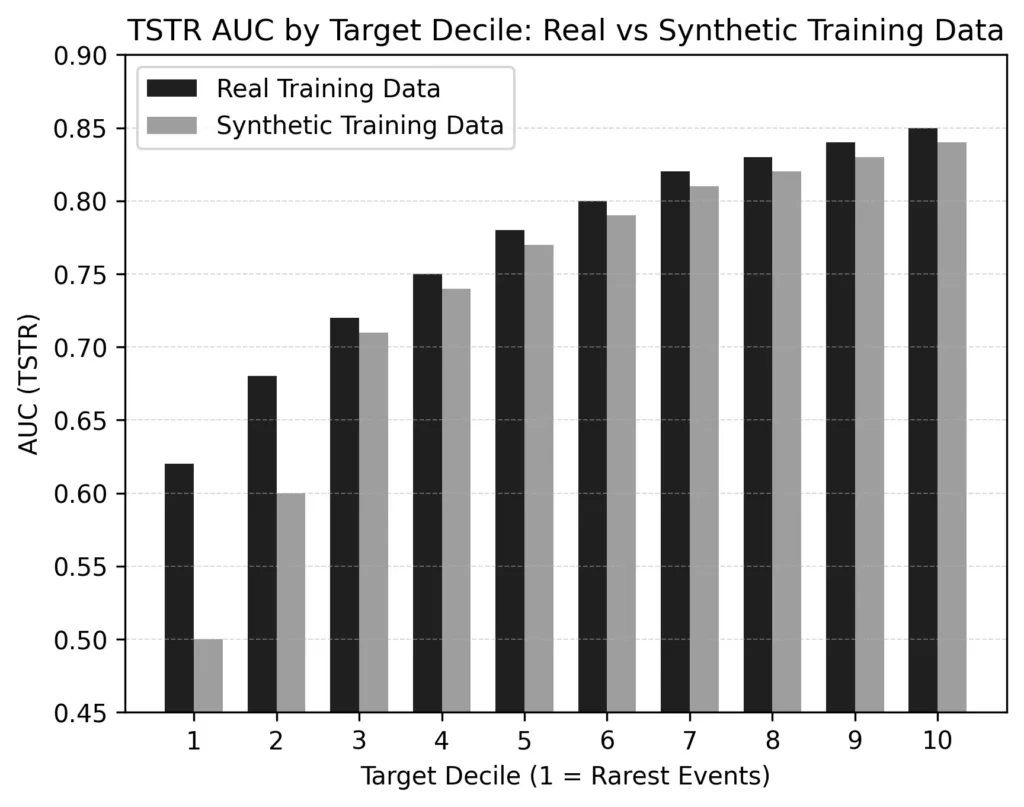
Tuy nhiên, điểm TSTR dựa trên mức trung bình. Do đó, chúng che giấu chính xác những gì sẽ bị phá vỡ trong môi trường sản xuất. Trong ví dụ phát hiện gian lận ở đầu bài viết, TSTR AUC tổng thể là 91%, nhưng khi hiệu suất được phân tích theo phân vị (decile) khối lượng giao dịch, phân vị hoạt động kém nhất (các giao dịch hiếm nhất, có giá trị cao nhất) giảm xuống 67% (dữ liệu tổng hợp tạo ra các giao dịch phổ biến rất chính xác; tuy nhiên, dữ liệu tổng hợp không đại diện cho các kịch bản hiếm nhất hoặc bất thường nhất một cách chính xác). Do đó, mô hình được huấn luyện trên dữ liệu tổng hợp đã học các hành vi phổ biến với độ chính xác cực cao và học hành vi ít phổ biến nhất với độ chính xác rất thấp.
Đây là vấn đề mất mát đuôi (tail loss problem). Nó được giải quyết chính thức trong tài liệu về sự sụp đổ của mô hình (Alemohammad et al., 2024, ICLR), và có thể được áp dụng cho bất kỳ quy trình tạo dữ liệu tổng hợp nào: Các mô hình tạo sinh được tối ưu hóa để tạo ra các vùng xác suất cao của phân phối dần dần đại diện không đầy đủ các sự kiện hiếm. Bộ tạo dữ liệu tổng hợp không cố ý đại diện không đầy đủ các sự kiện hiếm — nó đơn giản là đại diện cho toán học về cách các mô hình này học.
Khắc phục: Không báo cáo TSTR trên cơ sở tổng hợp. Hãy báo cáo TSTR riêng biệt cho từng phân vị mà bạn đã phân chia biến mục tiêu của mình. Các phân vị mà hiệu suất được huấn luyện bằng synthetic giảm mạnh nhất so với hiệu suất được huấn luyện bằng real sẽ chỉ cho bạn chính xác những phân vị nào mà dữ liệu tổng hợp của bạn không đại diện chính xác.
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
import pandas as pd
import numpy as np
def tstr_by_decile(
real_train: pd.DataFrame,
synthetic_train: pd.DataFrame,
real_test: pd.DataFrame,
target_col: str,
n_deciles: int = 10
) -> pd.DataFrame:
"""
Chạy đánh giá TSTR được phân tầng theo các phân vị của biến mục tiêu.
Trả về dataframe so sánh hiệu suất huấn luyện thật vs tổng hợp.
"""
results = []
real_test = real_test.copy()
real_test['decile'] = pd.qcut(
real_test[target_col], q=n_deciles, labels=False, duplicates='drop'
)
feature_cols = [c for c in real_train.columns if c != target_col]
for label, train_df in [("Real", real_train), ("Synthetic", synthetic_train)]:
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(train_df[feature_cols], train_df[target_col])
for decile_id, group in real_test.groupby('decile'):
if len(group[target_col].unique()) < 2:
continue
preds = clf.predict_proba(group[feature_cols])[:, 1]
auc = roc_auc_score(group[target_col], preds)
results.append({"dataset": label, "decile": decile_id, "auc": auc})
return pd.DataFrame(results)
Vấn đề #3: Điểm Rủi ro Quyền riêng tư MIS Không Đo lường Được Sự Rò rỉ Thuộc tính
Điểm rủi ro suy luận thành viên (Membership Inference Score - MIS) đo lường khả năng kẻ tấn công xác định xem một điểm dữ liệu cụ thể có nằm trong bộ dữ liệu huấn luyện hay không. Tuy nhiên, trong bối cảnh dữ liệu tổng hợp, mối đe dọa lớn hơn thường là suy luận thuộc tính (attribute inference).
Nếu dữ liệu tổng hợp bảo toàn quá tốt các mối quan hệ giữa các định danh giả (quasi-identifiers) như tuổi, khu vực, tình trạng việc làm và một thuộc tính nhạy cảm như thu nhập, thì kẻ tấn công có thể sử dụng dữ liệu tổng hợp để dự đoán thuộc tính nhạy cảm của người dùng trong dữ liệu thật.
Khắc phục: Thay vì chỉ dựa vào MIS, hãy chạy bài kiểm tra "Attribute Inference Lift". Huấn luyện một mô hình trên dữ liệu tổng hợp để dự đoán thuộc tính nhạy cảm từ các định danh giả, sau đó kiểm tra xem mô hình đó hoạt động tốt như thế nào trên dữ liệu thật. Nếu nó hoạt động tốt hơn đáng kể so với việc đoán ngẫu nhiên (hoặc so với tỷ lệ lớp đa số), dữ liệu tổng hợp của bạn đang rò rỉ thông tin nhạy cảm.
from sklearn.ensemble import GradientBoostingClassifier
def attribute_inference_risk(
synthetic_df: pd.DataFrame,
real_test_df: pd.DataFrame,
quasi_identifiers: list,
sensitive_feature: str
) -> dict:
"""
Ước tính rủi ro suy luận thuộc tính bằng cách kiểm tra mức độ tốt
của một mô hình được huấn luyện trên dữ liệu tổng hợp dự đoán một đặc trưng nhạy cảm
chỉ sử dụng các định danh giả.
Độ chính xác cao trên dữ liệu kiểm tra thật = dữ liệu tổng hợp đang rò rỉ
thông tin về thuộc tính nhạy cảm.
"""
clf = GradientBoostingClassifier(random_state=42)
clf.fit(synthetic_df[quasi_identifiers], synthetic_df[sensitive_feature])
real_accuracy = clf.score(
real_test_df[quasi_identifiers],
real_test_df[sensitive_feature]
)
majority_class_accuracy = (
real_test_df[sensitive_feature].value_counts(normalize=True).max()
)
lift = real_accuracy - majority_class_accuracy
return {
"inference_accuracy_on_real": round(real_accuracy, 4),
"baseline_accuracy": round(majority_class_accuracy, 4),
"inference_lift": round(lift, 4),
"risk_level": "HIGH" if lift > 0.10 else "MODERATE" if lift > 0.05 else "LOW"
}
risk = attribute_inference_risk(
synthetic_df, real_test_df,
quasi_identifiers=['age_band', 'region', 'employment_status'],
sensitive_feature='income_bracket'
)
print(risk)
Khi bạn thấy một giá trị "trên 0.10" (hoặc bất kỳ con số nào) cho lift, điều này có nghĩa là bộ dữ liệu tổng hợp của bạn là một người giáo viên tốt hơn trong việc xác định các thuộc tính nhạy cảm của người dùng của bạn so với sự ngẫu nhiên. Không quan trọng nếu Điểm Suy luận Thành viên (MIS) của bạn dưới 0.10 hoặc bất kỳ ngưỡng nào có thể là; điều đó không liên quan.
Khung Đánh giá Thống nhất
Như đã nêu trước đó, ba thách thức này về cơ bản là một thách thức: mỗi thách thức đều bắt nguồn từ việc sử dụng các chỉ số nhằm đánh giá các đặc điểm của một bộ dữ liệu và sau đó sử dụng các chỉ số đó làm cơ sở để chứng nhận một bộ dữ liệu cho triển khai sản xuất. Đây là hai nhiệm vụ hoàn toàn khác nhau.
Dưới đây là danh sách kiểm tra đầy đủ các đánh giá giải quyết từng khoảng trống trong đánh giá:
| Chiều | Chỉ số Chuẩn | Những gì Nó Bỏ lỡ | Kiểm tra Bổ sung |
|---|---|---|---|
| Fidelity | KL Divergence, KS Test | Cấu trúc tương quan giữa các đặc trưng | Correlation Drift Score (Chuẩn Frobenius) |
| Utility | TSTR AUC trung bình | Hiệu suất đuôi trên các sự kiện hiếm | TSTR được phân tầng theo phân vị mục tiêu |
| Privacy | Rủi ro Suy luận Thành viên | Suy luận thuộc tính qua định danh giả | Bài kiểm tra Attribute Inference Lift |
 Bảng tổng hợp khung đánh giá thống nhất
Bảng tổng hợp khung đánh giá thống nhất
Ngưỡng Đúng Phụ thuộc vào Trường hợp Sử dụng của Bạn
Khía cạnh bị bỏ qua nhất của buổi thảo luận tròn của FCA-ICO-Alan Turing Institute về xác thực dữ liệu tổng hợp là: "Rủi ro bằng không = Tiện ích bằng không". Dữ liệu tổng hợp không thể hoàn toàn riêng tư và hữu ích cùng một lúc. Câu hỏi không còn là "Dữ liệu có vượt qua không?" mà là "Các sự đánh đổi có đáp ứng nhu cầu của các trường hợp sử dụng không?"
Dữ liệu tổng hợp được sử dụng để kiểm tra QA nội bộ cho một ứng dụng yêu cầu độ trung thực và độ chính xác cấu trúc cao. Tuy nhiên, vì quyền truy cập vào dữ liệu được kiểm soát, nên có ít nhấn mạnh hơn vào quyền riêng tư.
Mặt khác, dữ liệu bạn phát hành cho người dùng bên ngoài, giữa các tổ chức, cho các cơ quan quản lý hoặc cho mục đích nghiên cứu phải có các đảm bảo quyền riêng tư cao hơn. Trong những trường hợp như vậy, bạn có thể chấp nhận độ trung thực thống kê thấp hơn trong dữ liệu tổng hợp.
Do đó, khi phát triển khung đánh giá của mình, hãy xác định trường hợp sử dụng trước khi bạn đánh giá dữ liệu tổng hợp của mình. Trả lời các câu hỏi sau trước khi bạn tạo dữ liệu tổng hợp:
- Ai sẽ có quyền truy cập vào bộ dữ liệu tổng hợp này và trong điều kiện nào? Điều này thiết lập ngưỡng quyền riêng tư của bạn.
- Nhiệm vụ hạ nguồn nào sẽ dữ liệu này huấn luyện hoặc kiểm tra? Điều này xác định các chỉ số utility nào là chịu tải trọng (load-bearing) so với nhiễu.
- Có bất kỳ đặc trưng nào được yêu cầu cho nhiệm vụ hạ nguồn không? Nếu có, điều này xác định nơi bạn phải bảo toàn độ trung thực và nơi bạn có thể dung nạp sự thay đổi.
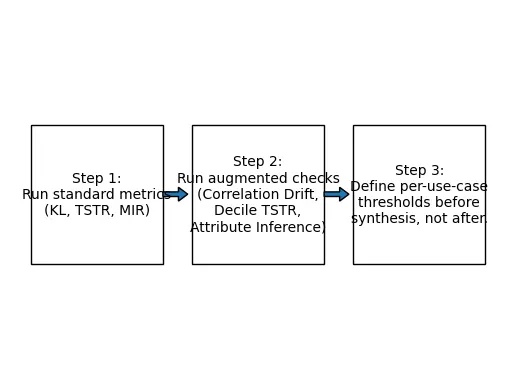
Thiết lập các ngưỡng này dựa trên câu trả lời của bạn cho các câu hỏi trên trước khi chạy tổng hợp. Chạy các đánh giá của bạn đối với các ngưỡng đã thiết lập (không phải các ngưỡng được báo cáo bởi công cụ theo mặc định).
Kết luận: Khoảng cách Chất lượng Là Khoảng cách Đo lường
Mô hình phát hiện gian lận không thất bại do dữ liệu tổng hợp kém. Mô hình thất bại vì nhóm đã đánh giá các đặc điểm sai và đưa ra kết luận sai dựa trên các phép đo chính xác của họ. Fidelity, utility và privacy là các chiều phù hợp.
Các chỉ số chuẩn trong mỗi chiều là những điểm khởi đầu tốt. Tuy nhiên, chúng được phát triển để đo lường và mô tả dữ liệu và không được phát triển để chứng nhận dữ liệu cho sử dụng sản xuất. Để đóng khoảng cách đo lường này yêu cầu ba đánh giá bổ sung xác định các khoảng trống trong các chỉ số chuẩn; trôi dạt tương quan (correlation drift), tiện ích đuôi theo phân vị, và rủi ro suy luận thuộc tính.
Ba đánh giá này không yêu cầu các công cụ chuyên biệt. Ba triển khai được mô tả trong bài viết này chạy trong scikit-learn và NumPy tiêu chuẩn. Công việc khó khăn không phải là viết mã, mà là đặt đúng câu hỏi trước khi đưa mô hình của bạn vào sản xuất.
 Hình ảnh minh họa về việc xác định ngưỡng phù hợp
Hình ảnh minh họa về việc xác định ngưỡng phù hợp
Bài viết liên quan

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026
AI & ML
MFA chỉ là bước khởi đầu: Tại sao xác thực thành công vẫn không ngăn chặn được tin tặc?
21 tháng 5, 2026

Phần cứng
Tổng quan tình hình trung tâm dữ liệu AI: Cuộc đua năng lượng, tranh cãi pháp lý và những bước đột phá phần cứng
08 tháng 5, 2026