
Giới thiệu về các phương pháp giải pháp xấp xỉ trong Học tăng cường (Reinforcement Learning)
Bài viết khám phá sự chuyển dịch từ các phương pháp bảng sang xấp xỉ hàm trong Học tăng cường, giải thích lý do tại sao khái quát hóa là cần thiết cho các vấn đề quy mô lớn và cách sử dụng Giảm độ dốc ngẫu nhiên (SGD) để tối ưu hóa.

Chào mừng bạn quay trở lại với series bài viết về Học tăng cường (Reinforcement Learning - RL), dựa trên cuốn sách nổi tiếng của Sutton và Barto. Trong các bài viết trước, chúng ta đã hoàn thành phần đầu của cuốn sách, nơi giới thiệu các kỹ thuật giải pháp cơ bản như Lập trình động (Dynamic Programming), phương pháp Monte Carlo (MC) và Học chênh lệch thời gian (Temporal Difference Learning - TD).
Điểm mấu chốt phân biệt phần I và phần II của cuốn sách nằm ở ràng buộc về quy mô của vấn đề. Nếu phần I tập trung vào các phương pháp dạng bảng (tabular), thì phần II này chúng ta sẽ đi sâu hơn vào chủ đề thú vị đó là xấp xỉ hàm (function approximation).
Cụ thể, trong phần I, chúng ta giả định không gian trạng thái đủ nhỏ để có thể biểu diễn nó và các giải pháp tìm được thông qua một bảng đơn giản. Tuy nhiên, giờ đây chúng ta sẽ bỏ qua giả định đó để có thể giải quyết các vấn đề phức tạp hơn trong thực tế.
Sự thay đổi này là hoàn toàn cần thiết. Chúng ta đã từng học cách chơi Cờ caro (Tic Tac Toe), nhưng đã thất bại với trò Connect Four – đơn giản vì số lượng trạng thái ở đây lên tới cấp độ 10²⁰. Hoặc hãy tưởng tượng một bài toán RL học nhiệm vụ dựa trên hình ảnh từ camera: số lượng hình ảnh có thể còn lớn hơn số nguyên tử trong vũ trụ đã biết.
Những con số này chứng minh rằng các phương pháp giải pháp xấp xỉ là tuyệt đối cần thiết. Không chỉ cho phép giải quyết các bài toán lớn, chúng còn mang lại khả năng khái quát hóa (generalization): với các phương pháp bảng, hai trạng thái gần nhau nhưng khác biệt vẫn bị xử lý tách biệt, trong khi xấp xỉ hàm giúp chúng ta nhận diện và khái quát hóa các trạng thái tương tự.
Bây giờ, hãy cùng bắt đầu tìm hiểu về xấp xỉ hàm, các phương pháp giải pháp và những lựa chọn hàm xấp xỉ khác nhau.
Giới thiệu về Xấp xỉ Hàm
Thay vì sử dụng bảng để biểu diễn các hàm giá trị như trước đây, chúng ta sẽ sử dụng một hàm có tham số với vector trọng số w. Hàm này có thể là bất kỳ thứ gì, từ một hàm tuyến tính của các giá trị đầu vào cho đến một mạng nơ-ron sâu (deep neural network).
Thông thường, số lượng trọng số sẽ nhỏ hơn nhiều so với số lượng trạng thái, tạo ra khả năng khái quát hóa. Khi chúng ta cập nhật hàm bằng cách điều chỉnh các trọng số, nó không chỉ ảnh hưởng đến một mục nhập duy nhất trong bảng mà tác động đến tất cả các ước tính khác.
Hãy cùng ôn lại các quy tắc cập nhật từ các phương pháp trước đây:
- Phương pháp MC gán lợi nhuận quan sát được G làm ước tính giá trị cho một trạng thái.
- TD(0) sử dụng ước tính giá trị của trạng thái tiếp theo để tự khởi tạo (bootstrap).
- DP sử dụng giá trị thực tế.
Từ giờ, chúng ta sẽ coi các cập nhật dạng s -> u là các cặp đầu vào/đầu ra của một hàm cần xấp xỉ. Chúng ta sẽ áp dụng các kỹ thuật từ học máy, cụ thể là học có giám sát (supervised learning) hay còn gọi là hồi quy (regression).
Tuy nhiên, các phương pháp này trong RL cần đáp ứng một số yêu cầu khắt khe: chúng phải xử lý được các thay đổi tăng dần và tập dữ liệu không cố định (non-stationary targets), khác với học có giám sát cổ điển.
Mục tiêu Dự đoán (Prediction Objective)
Trong phần I, chúng ta không cần một mục tiêu dự đoán cụ thể vì luôn có thể hội tụ về hàm tối ưu. Nhưng với các bài toán lớn phức tạp hiện nay, điều này không còn khả thi. Chúng ta cần định nghĩa một hàm mục tiêu (cost function) để tối ưu hóa.
Chúng ta sử dụng kỳ vọng của hiệu số bình phương giữa giá trị dự đoán và giá trị thực tế. Điều này đòi hỏi phải định nghĩa một phân phối µ, xác định mức độ quan tâm của chúng ta đối với các trạng thái cụ thể. Thường thì đây là phân phối on-policy (tỷ lệ thuận với tần suất trạng thái được ghé thăm).
Tuy nhiên, việc tối ưu hóa mục tiêu này không đảm bảo sẽ tìm ra chính sách tốt nhất nếu chính sách dành quá nhiều thời gian cho các trạng thái không mong muốn. Dù vậy, đây vẫn là mục tiêu khả thi nhất hiện tại.
Tối thiểu hóa Mục tiêu Dự đoán
Công cụ chúng ta sử dụng là Giảm độ dốc ngẫu nhiên (Stochastic Gradient Descent - SGD). Nguyên tắc của SGD là sử dụng các lô (batch) để tính gradient của mục tiêu và cập nhật trọng số theo hướng giảm thiểu mục tiêu đó.
Điều thú vị là nếu U_t là một ước tính không thiên kiến (unbiased) của v_π, thì giải pháp thu được qua SGD sẽ hội tụ về điểm tối ưu cục bộ. Chúng ta có thể sử dụng lợi nhuận MC làm U_t để có phương pháp RL gradient đầu tiên.
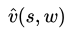 Phương pháp Gradient sử dụng lợi nhuận MC
Phương pháp Gradient sử dụng lợi nhuận MC
Ngoài ra, chúng ta cũng có thể sử dụng bootstrapping (sử dụng các ước tính trước đó làm mục tiêu). Khi làm điều này, chúng ta mất đi sự đảm bảo hội tụ nhưng về mặt thực nghiệm, nó vẫn hoạt động tốt. Các phương pháp này được gọi là phương pháp bán gradient (semi-gradient methods).
Dựa trên cơ sở này, chúng ta có thể giới thiệu TD(0) với xấp xỉ hàm:
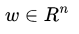 TD(0) với xấp xỉ hàm
TD(0) với xấp xỉ hàm
Một mở rộng tự nhiên là phương pháp TD bán gradient n-bước:
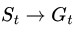 TD bán gradient n-bước
TD bán gradient n-bước
Các phương pháp Xấp xỉ Hàm
Sutton mô tả nhiều cách để biểu diễn hàm xấp xỉ, bao gồm xấp xỉ hàm tuyến tính và các mạng nơ-ron nhân tạo cho hàm phi tuyến. Vì chúng ta thường làm việc với mạng nơ-ron sâu, nên chúng ta sẽ chỉ đi qua nhanh các khái niệm cơ bản.
Xấp xỉ Hàm Tuyến tính
Trong xấp xỉ tuyến tính, hàm giá trị trạng thái được xấp xỉ bằng tích trong của vector trọng số và vector đặc trưng của trạng thái. Do sự đơn giản, phương pháp này mang lại các công thức giải pháp thanh lịch và một số đảm bảo về sự hội tụ.
Xây dựng Đặc trưng cho Phương pháp Tuyến tính
Một hạn chế của xấp xỉ tuyến tính đơn giản là mỗi đặc trưng được sử dụng riêng lẻ. Sutton lấy ví dụ về bài toán xe-cart (cart pole): vận tốc góc cao có thể tốt hoặc xấu tùy thuộc vào ngữ cảnh (cây cọc đang ở giữa hay sắp ngã).
Do đó, việc thiết kế các biểu diễn đặc trưng hiệu quả là rất quan trọng. Một trong số đó là cơ sở đa thức (polynomial basis). Ví dụ, nếu vector trạng thái có s1 và s2, ta có thể định nghĩa không gian đặc trưng bao gồm s1, s2, s1*s2, v.v. Sau đó ta vẫn có thể dùng xấp xỉ tuyến tính trên các đặc trưng mới này.
Các cơ sở phổ biến khác bao gồm cơ sở Fourier, tile coding và các hàm cơ sở bán kính (radial basis functions).
Kết luận
Trong bài viết này, chúng ta đã thực hiện một bước quan trọng đưa các thuật toán RL từ lý thuyết đến ứng dụng thực tế ("trong hoang dã"). Chúng ta nhận thấy rằng các phương pháp bảng nhanh chóng đạt đến giới hạn với các bài toán lớn, do đó các phương pháp giải pháp xấp xỉ là vô cùng cần thiết.
Chúng ta đã tìm hiểu về mục tiêu dự đoán, cách tối ưu hóa nó bằng SGD, và các thuật toán gradient/bán gradient đầu tiên. Cuối cùng, chúng ta đã thảo luận về các cách xây dựng hàm xấp xỉ, từ tuyến tính đến phi tuyến.
Cảm ơn bạn đã đọc! Hãy theo dõi bài viết tiếp theo để cùng đi sâu vào vấn đề điều khiển (control problem) tương ứng.
Bài viết liên quan

Công nghệ
Fosi Audio C3: Card âm thanh gaming tích hợp AI giúp game thủ "nghe thấy" đối thủ
28 tháng 5, 2026

Công nghệ
Founders Fund ra mắt gameshow với sự tham gia của Sam Altman, Palmer Luckey và các nhân vật công nghệ hàng đầu
05 tháng 6, 2026

Công nghệ
Tấn công mạng làm tê liệt nhà máy đường lớn tại Australia, nông dân không thể thu hoạch
17 tháng 6, 2026