
Lập trình Ngẫu nhiên: Khi bảng tính của bạn nói dối về tương lai
Bài viết này giới thiệu về Lập trình Ngẫu nhiên (Stochastic Programming) - phương pháp giúp đưa sự không chắc chắn trực tiếp vào mô hình tối ưu hóa. Chúng ta sẽ khám phá bốn cách tiếp cận chính để xử lý dữ liệu biến động và các chỉ số đánh giá hiệu quả của mô hình.

Lập trình Ngẫu nhiên: Khi bảng tính của bạn nói dối về tương lai
Trong các bài viết trước, chúng ta đã thảo luận về cách chuyển đổi một vấn đề thực tế thành chương trình tuyến tính nguyên và cách làm cho chương trình đó trở nên mạnh mẽ trước sự không chắc chắn. Cả hai đều xoay quanh một ý tưởng: lấy một câu hỏi thực tế mơ hồ, nén nó vào một mô hình tuyến tính (LP), và để trình giải (solver) làm phần còn lại.
Tuy nhiên, có một khoảnh khắc trong cuộc đời của mọi người làm tối ưu hóa khi LP bắt đầu trở nên quá "gọn gàng". Nhu cầu là một con số. Thời gian di chuyển là một con số. Tốc độ gió là một con số. Mô hình chấp nhận đầu vào, trả về giải pháp tối ưu và tiếp tục công việc. Nhưng thực tế mà những con số đó mô tả — lộn xộn, rung rinh và thỉnh thoảng gây bất ngờ — thực sự không xuất hiện ở bất cứ đâu.
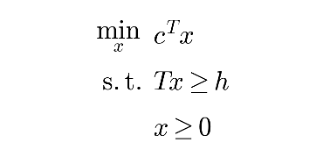 Mô hình tối ưu hóa
Mô hình tối ưu hóa
Lập trình ngẫu nhiên (Stochastic Programming) là lĩnh vực coi trọng sự khó chịu đó. Thay vì giả vờ rằng dữ liệu là chính xác, nó xây dựng sự không chắc chắn trực tiếp vào mô hình. Giá bạn phải trả là một chút ký hiệu phức tạp hơn; lợi ích thu được là những quyết định có thể đứng vững khi thế giới không hợp tác.
Bài viết này sẽ cung cấp một cái nhìn tổng quan nhẹ nhàng về những điều cơ bản. Chúng ta sẽ thấy tại sao cách tiếp cận hiển nhiên không hiệu quả, đi qua bốn cách tiêu chuẩn để xử lý sự không chắc chắn trong một chương trình tuyến tính, và kết thúc bằng một kiểm tra nhanh xem liệu tất cả những điều này có đáng để nỗ lực hay không.
Điểm khởi đầu: Một công ty thời trang với quả cầu pha lê kém
Để làm rõ vấn đề, hãy sử dụng ví dụ về một công ty thời trang bán quần áo mùa đông ở Đức. Sản xuất diễn ra tại Bangladesh, nơi rẻ nhưng chậm: hàng hóa mất vài tuần để đến nơi. Vì vậy, vào mùa thu, bạn phải quyết định sản xuất bao nhiêu cho mùa đông sắp tới.
Có hai cách mọi thứ có thể đi sai: sản xuất quá ít, bạn mất doanh số; sản xuất quá nhiều, bạn bị kẹt hàng tồn kho không bán được. Cả câu hỏi là sản xuất bao nhiêu ngay bây giờ, và câu trả lời phụ thuộc vào điều gì bạn chưa thực sự biết yet: nhu cầu mùa đông.
Nếu bạn bỏ qua sự không chắc chắn và giả vờ nhu cầu là một con số cố định, bạn có thể viết một LP đơn giản. Ở đây, x là lượng bạn sản xuất, c là chi phí sản xuất đơn vị, h là nhu cầu, và T là ma trận đơn vị. Ràng buộc nói rằng: sản xuất ít nhất bằng nhu cầu.
Điều này ổn nếu h thực sự được biết. Vấn đề là nhu cầu không phải là một con số, nó là một biến ngẫu nhiên. Hãy gọi nó là $\xi$. Phiên bản trung thực của mô hình sẽ trông như sau:
$$T x \ge h(\xi)$$
Và ở đây chúng ta gặp bế tắc. Điều gì có nghĩa là x thỏa mãn một ràng buộc phụ thuộc vào biến ngẫu nhiên? x = 100 có khả thi nếu nhu cầu có thể là 80, có thể là 120, và có thể là bất kỳ giá trị nào ở giữa? Vấn đề không phải là khó giải; nó là không xác định rõ. Trình giải thậm chí không biết vấn đề nào bạn đang yêu cầu nó giải quyết.
Lập trình ngẫu nhiên, về bản chất, là một tập hợp các câu trả lời có nguyên tắc cho câu hỏi đó. Chúng ta sẽ xem xét bốn cách phổ biến nhất.
Bốn cách để xử lý sự không chắc chắn
Mỗi cách tiếp cận trong số bốn cách tiếp nhận LP không xác định ở trên và biến nó thành một vấn đề tối ưu hóa xác định rõ. Chúng khác nhau về những gì chúng giả sử bạn biết về sự không chắc chắn và mức độ thận trọng của chúng đối với các kết quả xấu.
1. Tối ưu hóa mạnh (Robust optimization): Chuẩn bị cho trường hợp tồi tệ nhất
Cách tiếp cận thận trọng nhất. Bạn không cần biết toàn bộ phân phối xác suất của $\xi$, chỉ cần hỗ trợ của nó, tức là tập hợp các giá trị mà nó có thể nhận. Chúng ta gọi tập hợp này là tập hợp không chắc chắn, viết là U. Sau đó bạn hỏi: quyết định tốt nhất là gì để vẫn khả thi bất kể $\xi \in U$ nào thực sự xuất hiện?
Ràng buộc giờ phải giữ cho mọi $\xi$ trong tập hợp không chắc chắn. Trong ví dụ thời trang của chúng ta với U = [0, 10], bạn sẽ lập kế hoạch cho nhu cầu là 10, trường hợp tồi tệ nhất, mỗi lần.
Đó là điểm mạnh và điểm yếu của tối ưu hóa mạnh trong một câu. Giải pháp là "chống đạn", nhưng nó cũng bảo thủ: bạn thường sẽ ngồi trên hàng tồn kho không cần thiết, vì bạn lập kế hoạch như thể trường hợp xấu nhất ít xảy ra là được đảm bảo.
2. Ràng buộc cơ hội (Chance constraints): Thả lỏng trường hợp tồi tệ nhất
Tối ưu hóa mạnh lập kế hoạch cho bất kỳ kết quả nào có thể xảy ra. Ràng buộc cơ hội thả lỏng điều đó thành: lập kế hoạch cho đa số chúng. Bạn chọn mức xác suất $\alpha$, nói là 95%, và yêu cầu ràng buộc phải giữ với xác suất ít nhất là đó:
$$P(T x \ge h(\xi)) \ge \alpha$$
Điều này được gọi là ràng buộc cơ hội chung: tất cả các mục của vectơ ràng buộc phải được thỏa mãn đồng thời, với xác suất chung $\ge \alpha$. Một biến thể yếu hơn xử lý từng hàng riêng lẻ:
Đây là ràng buộc cơ chance riêng lẻ: mỗi ràng buộc i phải giữ với xác suất ít nhất là $\alpha_i$, nhưng bạn không quan tâm đến sự kiện chung. Dù bằng cách nào, ràng buộc cơ hội cho bạn một núm vặn, $\alpha$, để điều chỉnh mức độ thận trọng bạn muốn. Vặn nó lên 1, bạn quay lại (gần như) tối ưu hóa mạnh. Thả nó xuống 0.5, bạn cơ bản đang tung đồng xu về tính khả thi. Hầu hết các ứng dụng thực tế nằm ở đâu đó trong phạm vi 0,9–0,99.
Tuy nhiên, có một vấn đề cần lưu ý: ràng buộc cơ hội khó nói chung. Thuật ngữ xác suất bên trong ràng buộc là một hàm phi tuyến, thường không lồi của x, vì vậy bạn thường không thể đưa công thức trực tiếp cho trình giải LP tiêu chuẩn.
3. Mô hình khắc phục hai giai đoạn (Two-stage recourse models): Quyết định, quan sát, sửa chữa
Hai cách tiếp cận đầu tiên coi việc vi phạm ràng buộc là điều cần tránh, luôn luôn (mạnh) hoặc với xác suất cao (chance). Đôi khi đó là khung sai lầm. Trong ví dụ thời trang của chúng ta, không đáp ứng đủ nhu cầu không phải là thảm họa. Nó gây khó chịu. Bạn thường có thể sửa chữa nó: sản xuất một lô khẩn cấp nhỏ ở Đức với chi phí cao hơn, hoặc chuyển hàng bằng đường hàng không, hoặc chỉ chấp nhận mất doanh số và tiếp tục.
Ý tưởng rằng việc vi phạm ràng buộc không phải là tận thế, bạn có thể thực hiện một hành động khắc phục sau này, là trái tim của mô hình khắc phục. Trong phiên bản hai giai đoạn, dòng thời gian trông như sau:
- Giai đoạn 1 (bây giờ): bạn đưa ra quyết định giai đoạn 1 là x trong khi $\xi$ vẫn chưa chắc chắn.
- Sau đó: $\xi$ được hiện thực hóa, tức là biến ngẫu nhiên trở thành một con số đã biết.
- Giai đoạn 2 (sau này): bạn đưa ra quyết định giai đoạn 2 là y, biết $\xi$.
Về mặt toán học, giai đoạn 1 trông gần giống như một LP đơn giản, ngoại trừ mục tiêu giờ chứa chi phí tương lai mong đợi:
 Cây kịch bản
Cây kịch bản
Hàm $v(\xi, x)$ là giá trị tối ưu của vấn đề giai đoạn 2, cho rằng bạn đã chọn x trong giai đoạn 1 và $\xi$ trở thành giá trị hiện thực. Cấu trúc là: trả chi phí trước $c^T x$, và trên đó trả chi phí mong đợi để dọn dẹp sau khi biến ngẫu nhiên làm việc của nó.
Đó là toàn bộ ý tưởng. Mô hình khắc phục hai giai đoạn là công thức phổ biến nhất trong thực tế, một phần vì chúng nắm bắt được trình tự thời gian thực tế của các quyết định trong nhiều vấn đề thực (lập kế hoạch sản xuất, hàng tồn kho, phân phối năng lượng, lập lịch trình), và một phần vì chúng tương đối ổn định về mặt toán học.
4. Mô hình khắc phục đa giai đoạn (Multi-stage recourse models): Tiếp tục đi
Đôi khi cuộc sống không chỉ có hai giai đoạn. Bạn không chỉ quyết định-quan sát-sửa chữa một lần và về nhà; bạn quyết định, quan sát, quyết định, quan sát, quyết định... Mô hình khắc phục đa giai đoạn là sự mở rộng tự nhiên.
Trong ví dụ thời trang, giả sử chúng ta không còn chọn một lần vào mùa thu, mà ba lần: vào mùa thu (rẻ, ở Bangladesh), đầu mùa đông (đắt hơn, ở Romania), và cuối mùa đông (đắt nhất, ở Đức). Nhu cầu dần dần được tiết lộ trong suốt mùa, và tại mỗi giai đoạn chúng ta quyết định dựa trên những gì chúng ta đã quan sát cho đến nay.
Cách tự nhiên để hình dung điều này là như một cây kịch bản (scenario tree): mỗi nút là một trạng thái của thế giới, mỗi nhánh là một hiện thực hóa có thể của biến ngẫu nhiên tiếp theo, và một kịch bản là một đường dẫn hoàn chỉnh từ gốc đến lá.
Một sự tinh tế. Một kịch bản là toàn bộ quỹ đạo của $\xi$, không chỉ một hiện thực hóa. Biết rằng $\xi_2 = 10$ không cho bạn biết bạn đang ở kịch bản nào, vì $\xi_3$ chưa xảy ra. Điều này quan trọng khi bạn bắt đầu viết tương đương xác định, vì bạn phải cẩn thận rằng các quyết định của bạn chỉ phụ thuộc vào thông tin thực sự đã được quan sát vào thời điểm quyết định được đưa ra. Tính chất đó được gọi là không dự đoán trước (non-anticipativity): bạn không thể dự đoán tương lai.
Làm thế nào để chúng ta thực sự giải quyết một mô hình khắc phục?
Cho đến nay chúng ta đang viết mô hình. Để giải chúng, chúng ta thường chuyển đổi chúng thành một cái gì đó mà trình giải LP tiêu chuẩn có thể xử lý. Thủ thuật là công thức tương đương xác định (deterministic equivalent formulation).
Giả sử biến ngẫu nhiên $\xi$ có phân phối rời rạc: nó nhận hữu hạn nhiều giá trị $\xi^1, \xi^2, ..., \xi^S$ (được gọi là kịch bản), mỗi cái với xác suất $p_s$. Sau đó chi phí giai đoạn 2 mong đợi chỉ là một tổng hữu hạn, và chúng ta có thể viết toàn bộ vấn đề hai giai đoạn như một LP lớn bằng cách giới thiệu một bản sao của y cho mỗi kịch bản.
Đó là một LP thông thường. Lớn, có thể rất lớn, nếu bạn có S kịch bản, bạn về cơ bản đã sao chép giai đoạn 2 S lần, nhưng nó là một LP. Bạn có thể đưa nó thẳng cho bất kỳ trình giải nào bạn thích, và nó sẽ giải quyết nó.
Nếu phân phối của $\xi$ không rời rạc? Trong trường hợp đó, tương đương xác định có vô số kịch bản và không hữu hạn chiều. Sửa chữa tiêu chuẩn là xấp xỉ trung bình mẫu (sample average approximation): rút một mẫu kích thước S từ phân phối thực, giải tương đương xác định mẫu, và để S tăng cho đến khi giải pháp của bạn ổn định về mặt thống kê.
Điều này có thực sự đáng để làm phiền không?
Câu hỏi trung thực. Các chương trình ngẫu nhiên lộn xộn hơn để xây dựng, khó giải hơn và chạy chậm hơn so với anh em xác định của chúng. Nếu vấn đề thực tế của bạn không quá nhạy cảm với sự không chắc chắn, bạn có thể tốt hơn nếu chỉ cần cắm nhu cầu trung bình vào một LP thông thường và gọi đó là một ngày.
Tin tốt là bạn có thể định lượng chính xác bao nhiêu công thức ngẫu nhiên mua được cho bạn. Có hai chỉ số cổ điển, và cả hai đều đáng biết.
VSS (Giá trị của Giải pháp Ngẫu nhiên): Bạn sẽ tệ hơn bao nhiêu nếu bạn chỉ giải quyết vấn đề xác định với các giá trị trung bình và triển khai giải pháp của nó. Nếu VSS nhỏ, chương trình ngẫu nhiên không mua được nhiều; phím tắt xác định là ổn.
EVPI (Giá trị Mong đợi của Thông tin Hoàn hảo): Bạn sẽ thu được bao nhiêu nếu một tiên tri nhân từ trao cho bạn $\xi$ hiện thực trước khi bạn phải quyết định. Nếu EVPI nhỏ, dự báo của bạn đã chứa hầu hết thông tin bạn cần; đầu tư vào các dự báo tốt hơn có thể sẽ không thay đổi được tình thế. Nếu EVPI lớn, dữ liệu tốt hơn có giá trị thực.
 Các chỉ số đánh giá
Các chỉ số đánh giá
Hầu hết các vấn đề thực không phải là xác định. Tin tốt là bộ công cụ mô hình hóa của bạn không nhất thiết phải như vậy.
Tóm tắt
Nếu bạn đang sử dụng LP trong bất kỳ bối cảnh nào mà dữ liệu đầu vào thực sự không chắc chắn do nhu cầu dự báo, thời tiết, giá cả, thời gian di chuyển hoặc bất cứ điều gì khác, thì mô hình của bạn đang đưa ra một lựa chọn ngầm định về cách xử lý sự không chắc chắn đó. "Chỉ cần dùng giá trị trung bình" là một lựa chọn. Cũng như "lập kế hoạch cho trường hợp tồi tệ nhất". Lập trình ngẫu nhiên cung cấp cho bạn từ vựng để làm cho lựa chọn đó rõ ràng, và các công cụ để đánh giá xem lựa chọn của bạn có tốt hay không.
Bốn cách cơ bản để mô hình hóa sự không chắc chắn trong một LP:
- Tối ưu hóa mạnh — lập kế hoạch cho trường hợp tồi tệ nhất trong một tập hợp không chắc chắn nhất định.
- Ràng buộc cơ hội — yêu cầu tính khả thi với xác suất ít nhất là $\alpha$.
- Khắc phục hai giai đoạn — quyết định, quan sát, sửa chữa; trả chi phí khắc phục mong đợi.
- Khắc phục đa giai đoạn — ý tưởng tương tự, lặp lại theo thời gian trên một cây kịch bản.
Và hai chỉ số đáng giữ trong túi sau của bạn: VSS (mô hình ngẫu nhiên có giúp không?) và EVPI (dự báo tốt hơn có giúp không?).
Bài viết liên quan

Công nghệ
Vượt xa Prompt Engineering: Kiến tạo Hệ thống AI có Nhận thức Ngữ cảnh và Quản lý Bộ nhớ ở Quy mô lớn
10 tháng 6, 2026

Công nghệ
Anthropic và OpenAI mang cuộc chiến công nghệ sang chính trường Mỹ
20 tháng 5, 2026

Công nghệ
Threads cán mốc 500 triệu người dùng, ra mắt tính năng cá nhân hóa thuật toán mới
16 tháng 6, 2026