
NaN trong PyTorch: "Kẻ sát nhân thầm lặng" và cách tôi xây dựng công cụ bắt lỗi chỉ trong 3ms
NaN thường không gây crash quá trình huấn luyện mà âm thầm phá hủy mô hình. Bài viết này giới thiệu một công cụ phát hiện nhẹ nhàng sử dụng forward hooks trong PyTorch, giúp xác định chính xác lớp và batch xuất hiện lỗi với độ trễ chỉ khoảng 3ms, thay vì sử dụng phương pháp anomaly detection mặc định vốn quá chậm chạp.

NaN trong PyTorch: "Kẻ sát nhân thầm lặng" và cách tôi xây dựng công cụ bắt lỗi chỉ trong 3ms
Đó là batch thứ 47.000. Một biến thể của ResNet mà tôi đã huấn luyện trong sáu giờ trên một tập dữ liệu hình ảnh y tế tùy chỉnh. Hàm mất mát (loss) đang hội tụ đẹp mắt — 1.4, 1.1, 0.87, 0.73 — và rồi, không có gì cả. Không có lỗi. Không có crash. Chỉ là nan.
Tôi đã thêm torch.autograd.set_detect_anomaly(True) và khởi động lại. Quá trình huấn luyện chậm đi mức đáng báo động — khoảng 7–10 lần lâu hơn trên mỗi batch — và sau ba giờ, tôi cuối cùng cũng nhận được một stack trace chỉ vào một lớp mà nhìn thì có vẻ ổn. Kẻ thủ ác thực sự là bộ lập lịch tốc độ học (learning rate scheduler) tương tác kém với một lớp chuẩn hóa tùy chỉnh nằm ở hai lớp phía trước. set_detect_anomaly đã chỉ ra cho tôi triệu chứng, không phải nguyên nhân gốc rễ.
Phiên gỡ lỗi đó đã tốn của tôi gần cả ngày. Vì vậy, tôi đã xây dựng thứ gì đó tốt hơn.
NaN không làm crash mô hình của bạn — nó âm thầm làm hỏng nó. Đến khi bạn nhận ra, bạn đã đang gỡ lỗi sai lớp rồi.
Vấn đề với set_detect_anomaly
PyTorch cung cấp sẵn torch.autograd.set_detect_anomaly(True), đây là khuyến nghị tiêu chuẩn để gỡ lỗi các vấn đề về NaN. Nó hoạt động bằng cách giữ lại toàn bộ đồ thị tính toán và kiểm tra các bất thường trong quá trình lùi (backward pass). Điều này rất mạnh mẽ, nhưng nó đi kèm với chi phí nghiêm trọng khiến nó không phù hợp cho bất kỳ thứ gì ngoài việc kiểm tra nhanh cục bộ.
Vấn đề cốt lõi là nó buộc động cơ autograd của PyTorch vào chế độ đồng bộ, nơi nó lưu giữ các kích hoạt trung gian cho mọi thao tác. Trên GPU, điều này có nghĩa là phá vỡ quy trình thực thi không đồng bộ — mỗi lần khởi chạy kernel phải hoàn tất trước khi cái tiếp theo bắt đầu. Kết quả là độ trễ tăng từ 10–15 lần trên CPU lên đến 50–100 lần trên GPU cho các mô hình lớn hơn.
Có một vấn đề thứ hai: set_detect_anomaly chỉ ra nơi NaN lan truyền đến trong backward pass, không nhất thiết là nơi nó bắt đầu. Nếu một NaN đi vào mạng của bạn ở lớp 3 của một mô hình 50 lớp, backward pass sẽ báo lỗi ở đâu đó trong tính toán gradient cho một lớp sau đó, và bạn phải tự làm ngược từ đó.
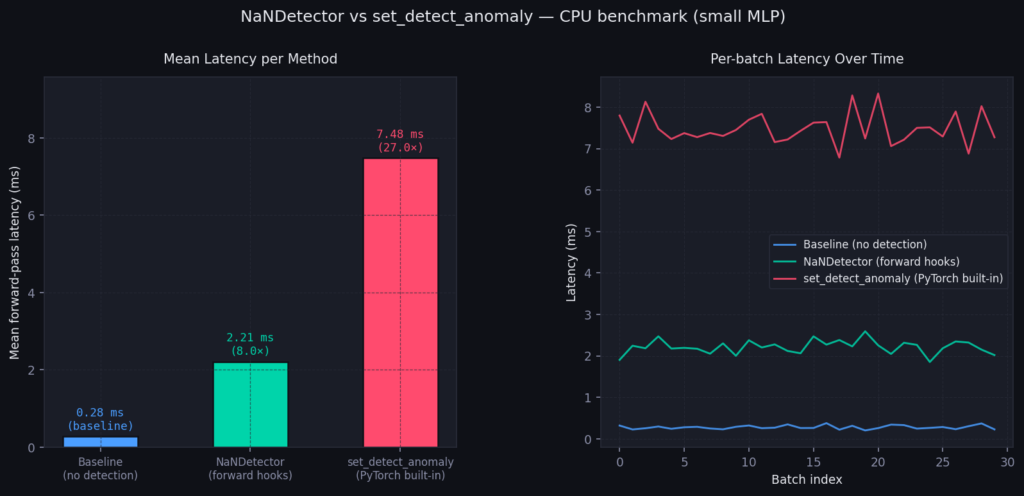 So sánh hiệu năng giữa các phương pháp phát hiện NaN
So sánh hiệu năng giữa các phương pháp phát hiện NaN
Trong điểm chuẩn của tôi trên một MLP CPU nhỏ (64→256→256→10), kết quả cho thấy:
- Không phát hiện: ~0.60 ms (cơ sở)
- NaNDetector (forward hooks): ~3–4 ms (~5–6×)
set_detect_anomaly: ~7–8 ms (~12–13×)
Việc phát hiện NaN dựa trên forward hook thêm ~3 ms mỗi lượt, trong khi set_detect_anomaly thêm ~7 ms — một khoảng cách nhỏ ở đây, nhưng là sự chậm lại lớn ở quy mô, đặc biệt là trên GPU.
Cách tiếp cận: Forward Hooks
PyTorch API register_forward_hook cho phép bạn đính kèm một lệnh gọi lại (callback) vào bất kỳ nn.Module nào kích hoạt mỗi lần mô hình đó hoàn thành một lượt tiến (forward pass). Lệnh gọi lại nhận được mô hình, đầu vào và đầu ra của nó. Điều này có nghĩa là bạn có thể kiểm tra mọi tensor chảy qua mọi lớp theo thời gian thực — mà không ảnh hưởng đến đồ thị tính toán, không ép buộc đồng bộ hóa và không giữ lại kích hoạt.
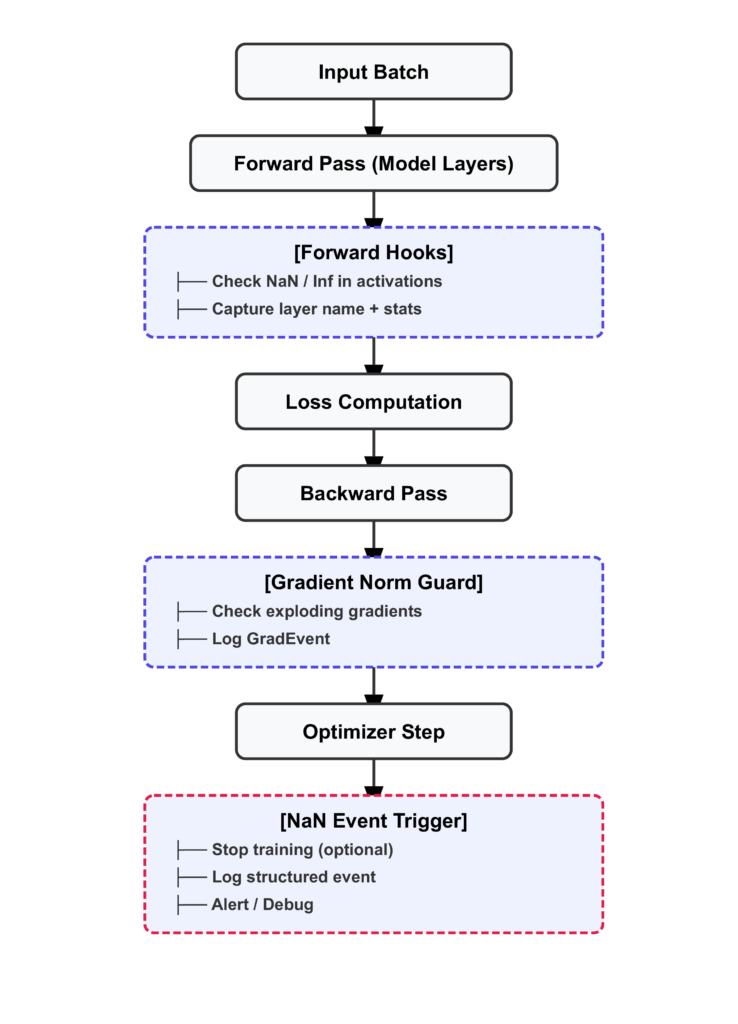 Quy trình phát hiện NaN từ đầu đến cuối
Quy trình phát hiện NaN từ đầu đến cuối
Thông tin chìa khóa là bạn chỉ cần thực hiện kiểm tra NaN, không cần phát lại tính toán. Một kiểm tra torch.isnan() và torch.isinf() trên tensor đầu ra là một lần gọi kernel CUDA duy nhất và hoàn thành trong vài micro giây.
def hook(module, inputs, output):
if torch.isnan(output).any():
print(f"NaN detected in {layer_name}")
Đó là cốt lõi của ý tưởng. Phần sau là phiên bản được "cứng hóa" cho môi trường sản xuất.
Chi tiết triển khai
Mã nguồn đầy đủ có sẵn tại: https://github.com/Emmimal/pytorch-nan-detector/
Dưới đây là bốn thành phần chính của công cụ này:
1. Dataclass NaNEvent
Khi phát hiện NaN, bạn cần nhiều hơn một câu lệnh in. Bạn cần một bản ghi có cấu trúc để kiểm tra sau, ghi vào đĩa hoặc gửi đến hệ thống cảnh báo. NaNEvent lưu trữ chỉ số batch, tên lớp, loại mô-đun, hình dạng đầu ra và thống kê (min, max, mean) của các giá trị hữu hạn.
2. Đăng ký hook an toàn luồng (Thread-safe)
Đây là cân nhắc quan trọng nhất cho môi trường sản xuất. DataLoader của PyTorch chạy các quy trình worker có thể kích hoạt forward hooks từ các luồng nền. Nếu bạn thay đổi trạng thái được chia sẻ mà không có khóa (lock), bạn sẽ gặp điều kiện tranh chấp (race conditions) trong các thiết lập multi-worker.
3. Bộ nhớ có giới hạn (Bounded memory)
Một vấn đề tinh tế trong các lần chạy huấn luyện dài: nếu bạn tích lũy thời gian chi phí trong một danh sách không giới hạn, bạn cuối cùng sẽ hết bộ nhớ. Giải pháp là một giới hạn đơn giản cho danh sách chi phí, chỉ giữ lại 1000 bản ghi gần nhất.
4. Gradient Norm Guard
Gradient explosion (nổ gradient) là nguyên nhân gốc rễ thực sự trong hầu hết các trường hợp — bắt nó sớm sẽ ngăn chặn NaN hoàn toàn. Phương pháp này kiểm tra chuẩn của gradient cho từng tham số và ghi lại sự kiện nếu nó vượt quá ngưỡng hoặc là vô hạn.
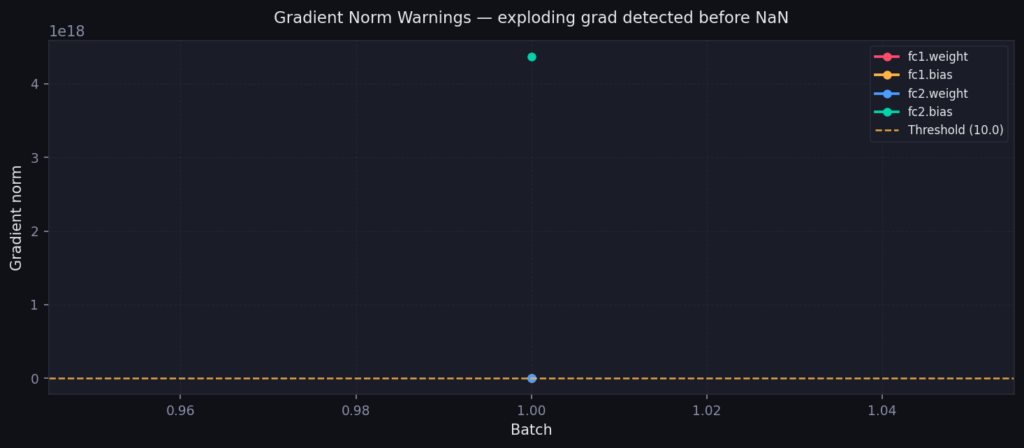 Gradient norms bùng nổ tại batch 1
Gradient norms bùng nổ tại batch 1
Trong bản demo, phương pháp này bắt được gradient explosion tại batch 1 — một bước huấn luyện đầy đủ trước khi NaN xuất hiện trong forward pass.
Cách sử dụng
Cơ bản: Context Manager
from nan_detector import NaNDetector
with NaNDetector(model) as det:
for batch_idx, (x, y) in enumerate(loader):
det.set_batch(batch_idx)
loss = criterion(model(x), y)
loss.backward()
det.check_grad_norms()
optimizer.step()
if det.triggered:
print(det.event)
break
Sản xuất: Vòng lặp huấn luyện tích hợp sẵn
Công cụ cũng cung cấp một hàm train_with_nan_guard để tích hợp nhanh vào các quy trình hiện có mà không cần viết lại nhiều mã lệnh.
Nâng cao: Backward hooks
Để bắt gradient NaN trực tiếp (không chỉ cảnh báo chuẩn), hãy bật check_backward=True. Sử dụng OrderedDict khi xây dựng các mô hình Sequential để có tên lớp dễ đọc trong nhật ký.
Các hạn chế đã biết
Forward hooks nhìn thấy các kích hoạt, không phải tất cả các tính toán. Nếu NaN bắt nguồn bên trong phương thức backward() tùy chỉnh hoặc phần mở rộng C++/CUDA không hiển thị qua các mô-đun con nn.Module, forward hook sẽ không bắt được nó. Bạn nên sử dụng check_backward=True để bao phủ phía gradient và grad_norm_warn để cảnh báo sớm.
Chi phí tính toán tăng theo độ sâu của mô hình. Điểm chuẩn được chạy trên MLP 5 lớp. Một transformer 200 lớp sẽ có 200 callback hook kích hoạt mỗi lượt tiến. Mặc dù chi phí mỗi hook vẫn dưới một mili giây, nhưng nó sẽ tích tụ lại.
Kết luận
Đây là một công cụ gỡ lỗi và giám sát, không phải thay thế cho các thực hành huấn luyện tốt. Các khuyến nghị tiêu chuẩn vẫn được áp dụng: cắt gradient (gradient clipping), lập lịch tốc độ học cẩn thận, chuẩn hóa đầu vào và khởi tạo trọng số. NaNDetector cho bạn biết vấn đề xảy ra ở đâu và khi nào — nó không nói cho bạn biết tại sao, và việc sửa nguyên nhân gốc rễ vẫn cần phán đoán kỹ thuật.
Nếu bạn gặp NaN trong huấn luyện độ chính xác hỗn hợp (fp16/bf16), những thủ phạm phổ biến nhất là tràn loss scaling và sự bất ổn của layer norm.
Bài viết liên quan

Phần mềm
Tấn công Cache Poisoning biến các gói npm TanStack thành mối đe dọa nguy hiểm
12 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026

Phần mềm
Shii haa: Ứng dụng biến micro điện thoại thành cảm biến phát hiện nhịp thở
02 tháng 6, 2026