
Tinh chỉnh mô hình RAG có thể âm thầm làm giảm độ chính xác truy xuất tới 40%
Nghiên cứu mới từ Redis cảnh báo rằng việc tinh chỉnh mô hình nhúng (embedding model) trong RAG để tăng độ chính xác có thể vô tình làm giảm chất lượng truy xuất dữ liệu. Hiệu suất có thể giảm tới 40% trên các mô hình kích thước vừa, gây ra những sai lầm nghiêm trọng trong chuỗi suy luận của các tác nhân AI (agentic AI).
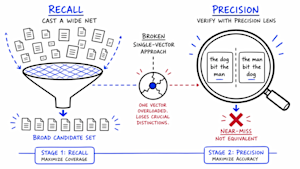
Các đội ngũ kỹ thuật tại doanh nghiệp thường cố gắng tinh chỉnh (fine-tune) các mô hình nhúng (embedding model) trong hệ thống RAG (Retrieval-Augmented Generation) để đạt độ chính xác cao hơn. Tuy nhiên, nghiên cứu mới từ Redis chỉ ra rằng hành động này có thể vô tình làm giảm chất lượng truy xuất mà các pipeline này phụ thuộc vào.
Bài báo khoa học mang tên "Training for Compositional Sensitivity Reduces Dense Retrieval Generalization" đã kiểm tra những gì xảy ra khi các đội ngũ đào tạo mô hình nhúng để có độ nhạy về cấu trúc (compositional sensitivity) — tức là khả năng nhận diện các câu có vẻ giống hệt nhau nhưng mang ý nghĩa khác nhau (ví dụ: "con chó cắn người" so với "người cắn con chó", hoặc sự đảo ngược phủ định làm thay đổi hoàn toàn ý nghĩa).
Kết quả cho thấy việc đào tạo này liên tục làm phá vỡ khả năng khái quát hóa truy xuất dày đặc (dense retrieval generalization) — khả năng truy xuất chính xác của mô hình trên các chủ đề và lĩnh vực rộng lớn mà nó chưa được đào tạo cụ thể. Hiệu suất đã giảm từ 8 đến 9 phần trăm trên các mô hình nhỏ và giảm tới 40 phần trăm trên một mô hình nhúng kích thước vừa hiện đang được nhiều đội ngũ sử dụng trong môi trường sản xuất.
Tác động đối với các pipeline AI tác nhân
Phát hiện này có ý nghĩa trực tiếp đối với các đội ngũ doanh nghiệp đang xây dựng các pipeline AI tác nhân (agentic AI pipelines), nơi chất lượng truy xuất quyết định ngữ cảnh nào sẽ chảy vào chuỗi suy luận của tác nhân. Một lỗi truy xuất trong pipeline đơn giai đoạn chỉ trả về một câu trả lời sai. Nhưng cùng một lỗi đó trong một pipeline AI tác nhân có thể kích hoạt một chuỗi các hành động sai lầm liên tiếp xuống phía dưới.
Srijith Rajamohan, Trưởng bộ phận Nghiên cứu AI tại Redis và là đồng tác giả của bài báo, cho biết phát hiện này thách thức một giả định phổ biến về cách thức hoạt động của truy xuất dựa trên nhúng.
"Có một quan niệm chung rằng khi chúng ta sử dụng tìm kiếm ngữ nghĩa hoặc sự tương đồng ngữ nghĩa, chúng ta sẽ nhận được đúng ý định. Điều đó không nhất thiết là đúng", Rajamohan chia sẻ. "Một sự tương đồng ngữ nghĩa gần hoặc cao không thực sự có nghĩa là ý định chính xác."
Đánh đổi về mặt hình học trong truy xuất
Các mô hình nhúng hoạt động bằng cách nén toàn bộ một câu thành một điểm duy nhất trong không gian nhiều chiều, sau đó tìm các điểm gần nhất với một truy vấn tại thời điểm truy xuất. Cách này hoạt động tốt để khớp các chủ đề chung — các tài liệu về các chủ đề tương tự sẽ nằm gần nhau. Vấn đề là hai câu có từ gần giống nhau nhưng ý nghĩa trái ngược nhau cũng nằm gần nhau, vì mô hình hoạt động dựa trên nội dung từ ngữ chứ không phải cấu trúc.
Đây là điều mà nghiên cứu đã định lượng hóa. Khi các đội ngũ tinh chỉnh mô hình nhúng để đẩy các câu có cấu trúc khác nhau xa nhau — dạy nó rằng sự đảo ngược phủ định làm thay đổi ý nghĩa câu không giống với bản gốc — mô hình sẽ sử dụng không gian biểu diễn mà nó trước đây dùng cho việc ghi nhớ chủ đề rộng. Hai mục tiêu này cạnh tranh cùng một vector.
Nghiên cứu cũng phát hiện ra rằng sự suy giảm không đồng nhất trên các loại lỗi. Lỗi phủ định và đảo ngược không gian được cải thiện đáng kể với đào tạo có cấu trúc. Tuy nhiên, lỗi ràng buộc (binding errors) — nơi mô hình nhầm lẫn bổ ngữ áp dụng cho từ nào — hầu như không thay đổi. Đối với các đội ngũ doanh nghiệp, điều này có nghĩa là vấn đề độ chính xác khó khắc phục hơn đúng trong những trường hợp sai lầm gây ra hậu quả nghiêm trọng nhất.
Lý do hầu hết các đội ngũ không phát hiện ra điều này là vì các chỉ số tinh chỉnh chỉ đo lường nhiệm vụ đang được đào tạo, chứ không đo lường những gì xảy ra với việc truy xuất chung trên các chủ đề không liên quan. Một mô hình có thể cho thấy sự cải thiện mạnh mẽ trong việc từ chối các trường hợp gần đúng trong quá trình đào tạo, trong khi âm thầm suy giảm trên công việc truy xuất rộng hơn mà nó được thuê để làm. Sự suy giảm này chỉ bộc lộ khi đưa vào môi trường sản xuất.
Rajamohan cho rằng bản năng của hầu hết các đội ngũ là chuyển sang mô hình nhúng lớn hơn không giải quyết được vấn đề kiến trúc cơ bản.
"Bạn không thể giải quyết vấn đề này bằng cách mở rộng quy mô", ông nói. "Đây không phải là vấn đề bạn có thể giải quyết bằng nhiều chiều và nhiều tham số hơn."
Tại sao các giải pháp thay thế tiêu chuẩn đều thất bại
Bản năng tự nhiên khi độ chính xác truy xuất thất bại là thêm vào các phương pháp tiếp cận khác. Nghiên cứu đã kiểm tra một số phương pháp này và thấy mỗi phương pháp đều thất bại theo một cách khác.
- Tìm kiếm kết hợp (Hybrid search): Kết hợp truy xuất dựa trên nhúng với tìm kiếm từ khóa là thực tế tiêu chuẩn để lấp đầy khoảng trống độ chính xác. Tuy nhiên, Rajamohan cho biết tìm kiếm từ khóa không thể bắt được chế độ thất bại mà nghiên cứu này xác định, vì vấn đề không phải là thiếu từ — mà là đọc sai cấu trúc.
- Tái xếp hạng MaxSim: Một số đội ngũ thêm lớp chấm điểm thứ hai so sánh các từ truy vấn riêng lẻ với các từ tài liệu riêng lẻ thay vì dựa vào vector nén duy nhất. Cách tiếp cận này, được gọi là MaxSim hoặc tương tác muộn (late interaction) và được sử dụng trong các hệ thống như ColBERT, đã cải thiện điểm số chuẩn mực về mức độ liên quan trong nghiên cứu. Nhưng nó hoàn toàn thất bại trong việc từ chối các trường hợp gần đúng về cấu trúc, gán cho chúng điểm số tương đồng gần như giống hệt nhau.
- Cross-encoders: Các mô hình này hoạt động bằng cách đưa truy vấn và tài liệu ứng viên vào mô hình cùng lúc, cho phép nó so sánh từng từ với từng từ trước khi đưa ra quyết định. Việc so sánh đầy đủ này chính là điều khiến chúng chính xác — và cũng là điều khiến chúng quá đắt đỏ để chạy ở quy mô sản xuất.
- Bộ nhớ ngữ cảnh (Contextual memory): Đôi khi được gọi là bộ nhớ tác nhân, các hệ thống này ngày càng được coi là con đường vượt qua RAG, nhưng Rajamohan cho rằng chuyển sang loại kiến trúc này không loại bỏ vấn đề truy xuất cấu trúc. Các hệ thống này vẫn phụ thuộc vào truy xuất tại thời điểm truy vấn, điều này có nghĩa là cùng một chế độ thất bại vẫn áp dụng.
Giải pháp hai giai đoạn được nghiên cứu xác thực
Điểm chung của mọi phương pháp thất bại là giống nhau: một cơ chế chấm điểm duy nhất cố gắng xử lý cả việc ghi nhớ (recall) và độ chính xác (precision) cùng một lúc. Nghiên cứu đã xác thực một kiến trúc khác: ngừng cố gắng thực hiện cả hai công việc với một vector, và giao mỗi công việc cho một giai đoạn chuyên biệt.
Giai đoạn 1: Ghi nhớ (Recall). Giai đoạn đầu tiên hoạt động chính xác như truy xuất dày đặc tiêu chuẩn hiện nay — mô hình nhúng nén tài liệu thành các vector và truy xuất các kết quả phù hợp nhất với một truy vấn. Không có gì thay đổi ở đây. Mục tiêu là tung một lưới rộng và mang lại một tập hợp các ứng viên mạnh một cách nhanh chóng. Tốc độ và phạm vi là điều quan trọng ở giai đoạn này, không phải độ chính xác hoàn hảo.
Giai đoạn 2: Độ chính xác (Precision). Giai đoạn thứ hai là nơi chứa giải pháp. Thay vì chấm điểm các ứng viên với một số tương đồng duy nhất, một mô hình Transformer nhỏ đã được học sẽ kiểm tra truy vấn và từng ứng viên ở cấp độ token — so sánh từng từ với từng từ để phát hiện các sự không khớp về cấu trúc như sự đảo ngược phủ định hoặc thay đổi vai trò. Đây là bước xác minh mà cách tiếp cận vector đơn không thể thực hiện.
Kết quả. Dưới đào tạo end-to-end, bộ xác minh Transformer đã vượt trội hơn mọi phương pháp tiếp cận khác mà nghiên cứu kiểm tra về việc từ chối các trường hợp gần đúng về cấu trúc. Nó là phương pháp tiếp cận duy nhất bắt được một cách đáng tin cậy các chế độ thất bại mà hệ thống vector đơn đã bỏ sót.
Sự đánh đổi. Thêm một giai đoạn xác minh sẽ tốn chi phí về độ trễ (latency). Chi phí độ trễ phụ thuộc vào mức độ xác minh mà một đội ngũ chạy. Đối với khối lượng công việc nhạy cảm về độ chính xác như ứng dụng pháp lý hoặc kế toán, việc xác minh đầy đủ tại mọi truy vấn là đáng lẽ ra nên làm. Đối với tìm kiếm mục đích chung, xác minh nhẹ hơn có thể đủ.
Điều này có nghĩa là gì cho các đội ngũ doanh nghiệp
Nghiên cứu không yêu cầu các đội ngũ doanh nghiệp xây dựng lại pipeline truy xuất của họ từ đầu. Nhưng nó yêu cầu họ kiểm tra áp lực các giả định mà hầu hết các đội ngũ chưa từng xem xét — về việc mô hình nhúng của họ thực sự đang làm gì, chỉ số nào đáng tin cậy và khoảng trống độ chính xác thực sự nằm ở đâu trong môi trường sản xuất.
Nhận biết sự đánh đổi trước khi tinh chỉnh. Rajamohan cho rằng bước thực tế đầu tiên là hiểu sự suy giảm này tồn tại. Ông đánh giá bất kỳ hệ thống truy xuất dựa trên LLM nào dựa trên ba tiêu chí: tính chính xác, tính đầy đủ và tính hữu ích. Các thất bại về tính chính xác sẽ lan truyền trực tiếp sang hai tiêu chí còn lại, điều này có nghĩa là một hệ thống truy xuất đạt điểm cao về các chuẩn mực liên quan nhưng thất bại trong các trường hợp gần đúng về cấu trúc đang tạo ra một cảm giác sai lầm về sự sẵn sàng đưa vào sản xuất.
RAG không bị lỗi thời — nhưng hãy biết những gì nó không thể làm. Rajamohan phản đối mạnh mẽ các tuyên bố cho rằng RAG đã bị thay thế. "Đó là một sự đơn giản hóa quá mức", ông nói. "RAG là một pipeline rất đơn giản mà gần như bất kỳ ai cũng có thể đưa vào sản xuất với rất ít nỗ lực." Nghiên cứu không phản đối RAG như một kiến trúc. Nó phản đối việc giả định rằng một pipeline RAG đơn giai đoạn với mô hình nhúng đã tinh chỉnh đã sẵn sàng cho sản xuất đối với các khối lượng công việc nhạy cảm về độ chính xác.
Giải pháp là có thật nhưng không miễn phí. Đối với các đội ngũ thực sự cần độ chính xác cao hơn, Rajamohan cho biết kiến trúc hai giai đoạn không phải là một rào cản triển khai quá lớn, nhưng việc thêm giai đoạn xác minh sẽ tốn độ trễ. "Đó là một vấn đề giảm thiểu", ông nói. "Không phải là điều chúng ta thực sự có thể giải quyết hoàn toàn."
Bài viết liên quan

Công nghệ
Anthropic và OpenAI mang cuộc chiến công nghệ sang chính trường Mỹ
20 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026
AI & ML
MFA chỉ là bước khởi đầu: Tại sao xác thực thành công vẫn không ngăn chặn được tin tặc?
21 tháng 5, 2026