
Cách chọn biến số bền vững trong Mô hình Chấm điểm (Scoring Model)
Hầu hết các mô hình chấm điểm thất bại do việc lựa chọn biến số kém chất lượng khi áp dụng trên dữ liệu mới. Bài viết này sẽ hướng dẫn bạn phương pháp chọn biến số ổn định, dễ giải thích và mạnh mẽ dựa trên kiểm định chéo để đảm bảo hiệu quả thực tế.

Hầu hết các mô hình chấm điểm (scoring model) thất bại vì một lý do chính: việc lựa chọn biến số kém. Chúng ta thường chọn các biến số hoạt động tốt trên dữ liệu huấn luyện (training data), nhưng chúng lại sụp đổ khi gặp dữ liệu mới. Mô hình trông có vẻ tuyệt vời trong giai đoạn phát triển nhưng lại gặp lỗi khi đưa vào sản xuất thực tế.
Tuy nhiên, có một cách tiếp cận tốt hơn. Bài viết này sẽ chỉ cho bạn cách chọn các biến số ổn định, có thể giải thích được và mạnh mẽ (robust), bất kể bạn chia dữ liệu như thế nào.
 Mô hình hóa dữ liệu và lựa chọn biến số
Mô hình hóa dữ liệu và lựa chọn biến số
Ý tưởng cốt lõi: Ổn định hơn Hiệu suất
Một biến số được coi là mạnh mẽ (robust) nếu nó có ý nghĩa quan trọng trên mọi tập con của dữ liệu, không chỉ trên toàn bộ tập dữ liệu.
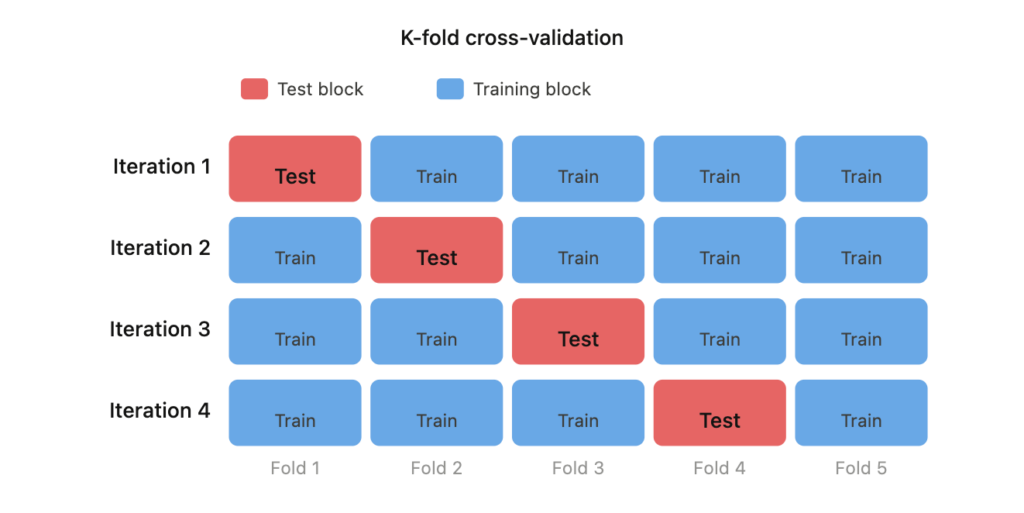
Để kiểm tra điều này, chúng ta chia dữ liệu huấn luyện thành 4 phần (folds) sử dụng phương pháp kiểm định chéo phân tầng (stratified cross-validation). Chúng ta phân tầng theo biến mục tiêu mặc định và năm để đảm bảo mỗi phần đều đại diện cho tổng thể dân số.
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=4, shuffle=True, random_state=42)
train_imputed["fold"] = -1
for fold, (_, test_idx) in enumerate(skf.split(train_imputed, train_imputed["def_year"])):
train_imputed.loc[test_idx, "fold"] = fold
Sau đó, chúng ta xây dựng bốn cặp (huấn luyện, kiểm tra). Mỗi cặp sử dụng ba phần để huấn luyện và một phần để kiểm tra. Chúng ta áp dụng mọi quy tắc lựa chọn chỉ trên tập huấn luyện, không bao giờ trên tập kiểm tra. Điều này ngăn chặn rò rỉ dữ liệu (data leakage).
Một biến số chỉ được giữ lại nếu nó vượt qua các tiêu chí trên cả bốn phần. Chỉ cần một phần yếu là đủ để loại bỏ nó.
Bộ dữ liệu
Chúng ta sử dụng Bộ dữ liệu Chấm điểm Tín dụng (Credit Scoring Dataset) từ Kaggle. Nó chứa 32.581 khoản vay được cấp cho các cá nhân vay.
Các khoản vay này bao gồm nhu cầu y tế, cá nhân, giáo dục và chuyên nghiệp, cũng như hợp nhất nợ. Số tiền vay dao động từ 500 USD đến 35.000 USD.
Bộ dữ liệu có hai loại biến số:
- Đặc điểm hợp đồng: số tiền vay, lãi suất, mục đích vay, xếp hạng tín dụng, thời gian kể từ khi phát hành.
- Đặc điểm người vay: tuổi, thu nhập, năm kinh nghiệm, tình trạng nhà ở.
Chúng ta xác định 7 biến liên tục và 4 biến phân loại. Mục tiêu là biến default (vỡ nợ): 1 nếu người vay vỡ nợ, 0 nếu ngược lại. Trong bài viết trước, chúng ta đã xử lý các giá trị thiếu và ngoại lệ. Ở đây, chúng ta tập trung vào việc lựa chọn biến số.
Phương pháp lọc: Bốn quy tắc
Phương pháp lọc sử dụng các thước đo thống kê về sự liên kết. Nó không cần một mô hình dự đoán. Nó nhanh, có thể kiểm toán và dễ giải thích cho các bên liên quan không chuyên về kỹ thuật.
Chúng ta áp dụng bốn quy tắc theo trình tự. Mỗi quy tắc lấy đầu ra của quy tắc trước làm đầu vào.
Quy tắc 1: Loại bỏ biến liên tục không liên quan đến vỡ nợ
Chúng ta chạy kiểm định Kruskal-Wallis giữa mỗi biến liên tục và mục tiêu vỡ nợ. Nếu giá trị p vượt quá 5% trên ít nhất một phần, chúng ta loại bỏ biến đó. Nó không được liên kết một cách đáng tin cậy với việc vỡ nợ.
Kết quả: Tất cả các biến liên tục đều vượt qua Quy tắc 1. Mọi biến liên tục đều cho thấy sự liên kết đáng kể với vỡ nợ ở cả bốn phần.
Quy tắc 2: Loại bỏ biến phân loại liên kết yếu với vỡ nợ
Chúng ta tính toán hệ số Cramér’s V giữa mỗi biến phân loại và mục tiêu vỡ nợ. Cramér’s V đo lường sự liên kết giữa hai biến phân loại. Nó dao động từ 0 (không có liên kết) đến 1 (liên kết hoàn hảo).
Chúng ta loại bỏ một biến nếu Cramér’s V của nó giảm xuống dưới 10% trên ít nhất một phần. Một liên kết mạnh yêu cầu giá trị V trên 50%.
Kết quả: Chúng ta giữ lại 3 trong số 4 biến phân loại. Biến loan_int bị loại bỏ; liên kết vỡ nợ của nó quá yếu trong ít nhất một phần.
Quy tắc 3: Loại bỏ biến liên tục dư thừa
Hai biến liên tục mang cùng một thông tin sẽ làm hại mô hình. Chúng tạo ra hiện tượng đa cộng tuyến (multicollinearity).
Chúng ta tính toán hệ số tương quan Spearman giữa mọi cặp biến liên tục. Nếu tương quan đạt 60% hoặc cao hơn trên ít nhất một phần, chúng ta loại bỏ một biến trong cặp đó. Chúng ta giữ lại biến có liên kết mạnh hơn với vỡ nợ, được đo bằng giá trị p Kruskal-Wallis thấp nhất.
Kết quả: Chúng ta giữ lại 5 biến liên tục. Chúng ta loại bỏ loan_amnt và cb_person_cred_hist_length vì cả hai đều có tương quan mạnh với các biến được giữ lại khác.
Quy tắc 4: Loại bỏ biến phân loại dư thừa
Chúng ta áp dụng logic tương tự cho các biến phân loại. Chúng ta tính toán Cramér’s V giữa mọi cặp biến phân loại được giữ lại sau Quy tắc 2. Nếu V đạt 50% hoặc cao hơn trên ít nhất một phần, chúng ta loại bỏ biến có liên kết yếu nhất với vỡ nợ.
Kết quả: Chúng ta giữ lại 2 biến phân loại. Chúng ta loại bỏ loan_grade, biến này có tương quan mạnh với một biến được giữ lại khác và có liên kết yếu hơn với vỡ nợ.
Lựa chọn cuối cùng: 7 Biến số
Phương pháp lọc chọn ra tổng cộng 7 biến số, bao gồm 5 biến liên tục và 2 biến phân loại. Mỗi biến số đều có liên kết đáng kể với vỡ nợ. Không biến nào trong số chúng là dư thừa. Và tất cả đều đứng vững trên mọi phần dữ liệu.
Lựa chọn này có thể kiểm toán được. Bạn có thể chỉ ra mọi quyết định cho cơ quan quản lý hoặc các bên liên quan kinh doanh. Bạn có thể giải thích lý do tại sao mỗi biến được giữ lại hoặc loại bỏ. Điều này rất quan trọng trong chấm điểm tín dụng.
Mỗi quy tắc chạy trên tập huấn luyện của mỗi phần. Một biến số bị loại nếu nó thất bại ở bất kỳ phần đơn lẻ nào. Đây chính là điều làm cho việc lựa chọn trở nên mạnh mẽ.
Trong bài viết tiếp theo, chúng ta sẽ nghiên cứu tính đơn điệu (monotonicity) và sự ổn định theo thời gian của 7 biến số này. Một biến số có thể đáng kể ngày hôm nay nhưng không ổn định theo thời gian. Cả hai thuộc tính này đều quan trọng trong các mô hình chấm điểm sản xuất.
Tóm tắt các điểm chính:
- Hầu hết các nhà khoa học dữ liệu chọn biến số dựa trên dữ liệu huấn luyện. Chúng bị lỗi trên dữ liệu mới. Quy tắc 1 khắc phục điều này: chúng ta chạy kiểm định Kruskal-Wallis trên từng phần riêng biệt. Sự tương quan giữa biến liên tục và vỡ nợ phải đáng kể ở cả bốn phần.
- Biến phân loại là "kẻ giết người thầm lặng" của các mô hình chấm điểm. Chúng trông có vẻ tương quan với vỡ nợ trên toàn bộ tập dữ liệu nhưng lại sụp đổ trên một tập con. Quy tắc 2 phát hiện ra chúng: chúng ta tính toán Cramér’s V trên từng phần độc lập. Dưới 10% ở bất kỳ phần nào, biến đó bị loại.
- Hai biến liên tục nói cùng một điều không làm tăng tín hiệu của bạn. Chúng phá hủy mô hình của bạn. Quy tắc 3 phát hiện mọi cặp tương quan (Spearman ≥ 60%) trên tất cả các phần. Khi hai biến "đấu nhau", biến có liên kết yếu nhất với vỡ nợ sẽ thua.
- Sự dư thừa của biến phân loại vô hình cho đến khi mô hình của bạn không vượt qua được kiểm toán. Quy tắc 4 làm rõ điều này: chúng ta tính toán Cramér’s V giữa mọi cặp biến phân loại. Trên 50% ở bất kỳ phần nào, một biến sẽ bị loại. Chúng ta giữ lại biến có tương quan cao nhất với biến mục tiêu vỡ nợ.
Bài viết liên quan

Công nghệ
Fosi Audio C3: Card âm thanh gaming tích hợp AI giúp game thủ "nghe thấy" đối thủ
28 tháng 5, 2026

Công nghệ
Founders Fund ra mắt gameshow với sự tham gia của Sam Altman, Palmer Luckey và các nhân vật công nghệ hàng đầu
05 tháng 6, 2026

Công nghệ
Tấn công mạng làm tê liệt nhà máy đường lớn tại Australia, nông dân không thể thu hoạch
17 tháng 6, 2026