
CSPNet: Kiến trúc mạng nơ-ron tích chập nhẹ hơn mà không cần đánh đổi độ chính xác
CSPNet (Cross Stage Partial Network) là một giải pháp hiệu quả giúp giảm độ phức tạp tính toán cho các mô hình CNN như DenseNet mà vẫn duy trì hoặc cải thiện độ chính xác. Bài viết này sẽ phân tích chi tiết kiến trúc CSPNet và hướng dẫn quy trình triển khai mô hình từ đầu bằng PyTorch.

Làm thế nào để biến một mô hình dựa trên CNN (Mạng nơ-ron tích chập) trở nên "nhẹ hơn" (lightweight)? Cách phổ biến nhất là sử dụng phiên bản nhỏ hơn của mô hình đó. Ví dụ, nếu ResNet-152 quá nặng, hãy dùng ResNet-101. Hoặc với DenseNet, hãy chọn DenseNet-121 thay vì DenseNet-169.
Điều này hoàn toàn đúng, nhưng cái giá phải trả là sự hy sinh về độ chính xác. Về cơ bản, nếu bạn muốn một mô hình nhẹ hơn, bạn phải chấp nhận rằng độ chính xác sẽ giảm đi.
Vậy nếu tôi nói với bạn về một mô hình nhẹ hơn bản gốc nhưng vẫn cạnh tranh được về độ chính xác thì sao? Hãy cùng tìm hiểu về CSPNet (Cross Stage Partial Network). Bạn sẽ ngạc nhiên khi biết rằng nó có thể giảm thiểu độ phức tạp tính toán hiệu quả mà vẫn duy trì độ chính xác cao — hoàn toàn không cần đánh đổi!
Lịch sử và Vấn đề của DenseNet
CSPNet được giới thiệu lần đầu tiên trong bài báo "CSPNet: A New Backbone That Can Enhance Learning Capability of CNN" của Wang và cộng sự vào tháng 11 năm 2019. Ban đầu, CSPNet được đề xuất để giải quyết các hạn chế của DenseNet. Mặc dù đã rẻ hơn ResNet về mặt tính toán, các tác giả cho rằng chi phí tính toán của DenseNet bản thân vẫn còn khá đắt đỏ.
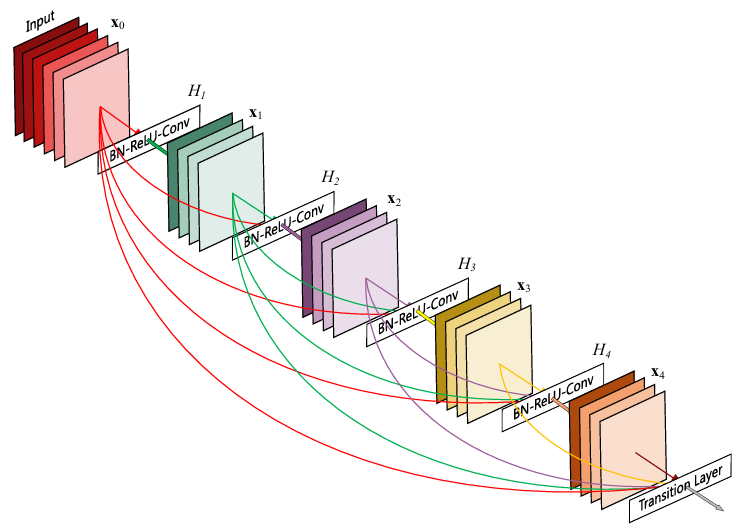 Khối xây dựng chính của DenseNet
Khối xây dựng chính của DenseNet
Trong một khối xây dựng DenseNet — gọi là dense block — mỗi lớp tích chập (convolution layer) nhận thông tin từ tất cả các lớp trước đó. Điều này gây ra một lượng lớn thông tin gradient dư thừa, khiến việc huấn luyện trở nên kém hiệu quả. Chúng ta có thể hình dung như một học sinh được dạy bởi 5 giáo viên khác nhau cho cùng một tài liệu. Ban đầu thì tốt vì học sinh nhận được nhiều góc nhìn, nhưng đến một lúc nào đó nó trở nên dư thừa và kém hiệu quả.
Mục tiêu và Kiến trúc của CSPNet
Mục tiêu của CSPNet là cho phép một mạng có độ phức tạp tính toán rẻ hơn và kết hợp gradient tốt hơn. Lý do là hầu hết thông tin gradient trong DenseNet bao gồm các bản sao trùng lặp của nhau. Quan trọng cần lưu ý, CSPNet không phải là một mạng độc lập, mà là một mô hình mới (paradigm) chúng ta áp dụng lên DenseNet.
 So sánh DenseNet và CSPNet
So sánh DenseNet và CSPNet
Bằng cách áp dụng cơ chế Cross Stage Partial, chúng ta có thể làm cho tính toán của DenseNet rẻ hơn rất nhiều. Nhìn vào hình minh họa bên phải, chúng ta thấy có một nhánh phụ thêm ra từ x₀ đi thẳng đến lớp được gọi là Partial Transition Layer.
Cơ chế này mang lại hai lợi ích chính:
- Tiết kiệm tính toán: Số lượng feature maps được xử lý bởi dense block chỉ bằng một nửa so với bản gốc.
- Gradient đa dạng hơn: Chúng ta có thêm một đường dẫn với các feature maps chưa được xử lý, giúp tránh được thông tin gradient dư thừa.
Tóm lại, ý tưởng của CSPNet là loại bỏ sự dư thừa tính toán của DenseNet (thông qua skip-path) nhưng vẫn giữ lại thuộc tính tái sử dụng đặc trưng (thông qua dense block).
Các phương pháp kết hợp đặc trưng
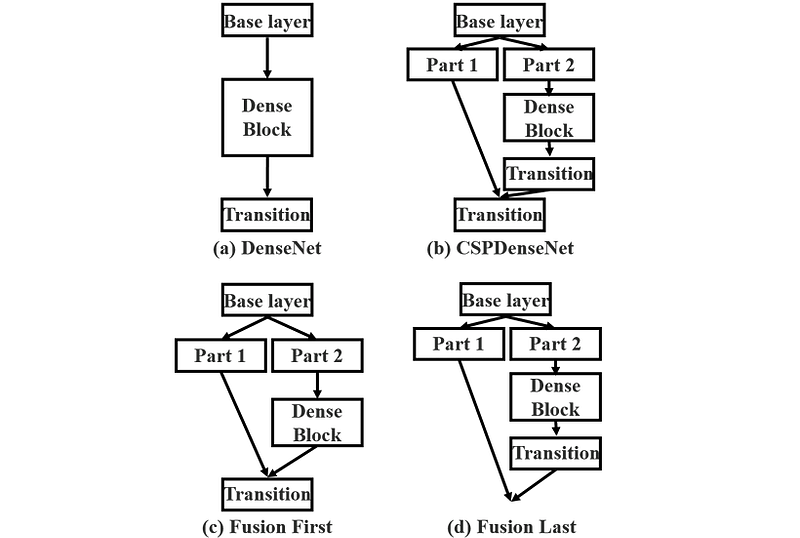
Khi áp dụng CSPNet, việc chia tách feature map khá đơn giản (chia theo kênh), nhưng bước hợp nhất (merging) lại phức tạp hơn. Có ba cơ chế chính để thực hiện việc này:
- Fusion First (c): Nối phần tensor 1 với phần tensor 2 (đã qua dense block) trước khi đưa qua transition layer.
- Fusion Last (d): Nối hai phần tensor sau khi tensor phần 2 đã đi qua transition layer. Do transition layer làm giảm kích thước không gian, ta cần áp dụng pooling hoặc bỏ qua bước downsampling ở phần tensor 1 để chúng có thể ghép được.
- CSPDenseNet (b): Sử dụng hai transition layer, một trước và một sau khi nối tensor. Đây là phương pháp kết hợp cả hai cách trên.
Kết quả thực nghiệm
Theo bài báo, phương pháp Fusion Last (d) tốt hơn Fusion First (c), giúp giảm đáng kể độ phức tạp tính toán với chỉ một sự sụt giảm rất nhỏ về độ chính xác. Tuy nhiên, biến thể (b) — CSPPeleeNet — mang lại kết quả ấn tượng nhất.
 So sánh hiệu suất các biến thể CSPNet
So sánh hiệu suất các biến thể CSPNet
Dựa trên kết quả thực nghiệm, cấu trúc CSP fusion last (màu xanh lá) giảm 21% độ phức tạp tính toán với độ chính xác chỉ giảm 0,1% so với mô hình gốc. Tuy nhiên, ngôi sao là biến thể CSPPeleeNet (màu xanh dương): mặc dù độ phức tạp tính toán giảm 13%, độ chính xác của mô hình thực sự tăng lên 0,2% — một kết quả "không cần đánh đổi" thực sự!
Các tác giả cũng áp dụng CSPNet lên các mô hình xương sống (backbone) khác như DenseNet-201-Elastic và ResNeXt-50, đều thu được kết quả khả quan: giảm tính toán nhưng vẫn giữ hoặc cải thiện độ chính xác.
Triển khai CSPDenseNet với PyTorch
Để hiểu rõ hơn, chúng ta sẽ xem xét cách triển khai kiến trúc này từ đầu bằng PyTorch. Quy trình chính bao gồm việc chia tensor đầu vào thành hai phần, xử lý chúng song song và sau đó hợp nhất lại.
1. Khối Bottleneck
Khối này là thành phần cơ bản trong DenseBlock, bao gồm một lớp tích chập 1x1 theo sau là lớp 3x3. Trong CSPNet, khối này hoạt động trên phần tensor được chọn để xử lý.
2. Dense Block
DenseBlock là một chuỗi các khối Bottleneck được xếp chồng lên nhau. Trong CSPNet, khối này chỉ xử lý một nửa số lượng kênh đầu vào (phần 2).
3. First Transition Layer
Lớp chuyển tiếp đầu tiên này xử lý tensor phần 2 sau khi thoát khỏi DenseBlock. Điểm đặc biệt là nó thực hiện cross-channel pooling (giảm số lượng kênh) nhưng không thực hiện downsampling (giảm kích thước không gian). Điều này thường được thực hiện bằng lớp tích chập 1x1.
4. Second Transition Layer
Lớp này nhận đầu vào là kết quả của việc nối (concatenate) phần 1 (bỏ qua xử lý) và phần 2 (đã qua First Transition). Nhiệm vụ của nó là giảm cả số lượng kênh và kích thước không gian (thông qua Average Pooling với stride=2).
5. Lớp CSPDenseNet hoàn chỉnh
Mô hình cuối cùng kết hợp tất cả các thành phần trên. Quy trình forward diễn ra như sau:
- Tensor đi qua lớp tích chập đầu tiên và Max Pooling.
- Tại mỗi Stage, tensor được chia làm hai (part 1 và part 2).
- Part 2 đi qua DenseBlock và First Transition.
- Part 1 và Part 2 được nối lại (concatenate).
- Kết quả đi qua Second Transition để chuẩn bị cho Stage tiếp theo.
- Ở Stage cuối cùng, kết quả được nối lại và đưa trực tiếp vào lớp Global Average Pooling và lớp phân loại (Fully Connected).
Kết luận
CSPNet là một kiến trúc thông minh giải quyết bài toán tối ưu hóa mô hình CNN. Bằng cách chia nhỏ luồng dữ liệu và xử lý chúng một cách chiến lược, CSPNet loại bỏ sự dư thừa tính toán của DenseNet mà vẫn giữ được khả năng học tập đặc trưng mạnh mẽ.
Kết quả là một mô hình nhẹ hơn, nhanh hơn nhưng không hề thua kém về độ chính xác — thậm chí còn tốt hơn. Đây là một công cụ tuyệt vời cho các ứng dụng yêu cầu hiệu suất cao trên thiết bị có tài nguyên hạn chế (như thiết bi di động hoặc hệ thống nhúng). Bạn có thể thử áp dụng ý tưởng này cho các backbone khác như ResNet để thấy hiệu quả của nó.
Bài viết liên quan

Phần mềm
Lỗ hổng kernel Linux mới "Fragnesia" cho phép leo quyền root nguy hiểm
14 tháng 5, 2026

Phần mềm
Chính phủ Mỹ yêu cầu Instructure giải trình về sự cố tấn công mạng và lộ dữ liệu Canvas
13 tháng 5, 2026

Phần mềm
Tấn công Cache Poisoning biến các gói npm TanStack thành mối đe dọa nguy hiểm
12 tháng 5, 2026