
Granite 4.1: Mô hình 8B của IBM đạt hiệu năng ngang ngửa các đối thủ gấp 4 lần kích thước
IBM vừa ra mắt dòng mô hình ngôn ngữ mã nguồn mở Granite 4.1 với ba kích thước 3B, 8B và 30B. Điểm nổi bật là phiên bản 8B sử dụng kiến trúc Dense nhưng đạt hiệu năng tương đương hoặc vượt qua các mô hình MoE 32B thế hệ trước nhờ chất lượng dữ liệu và quy trình huấn luyện tối ưu. Dòng sản phẩm này được cấp phép Apache 2.0, hướng tới nhu cầu doanh nghiệp với khả năng gọi công cụ và độ trễ ổn định.

IBM vừa chính thức công bố gia đình mô hình ngôn ngữ mã nguồn mở Granite 4.1, được xây dựng đặc biệt cho mục đích sử dụng trong doanh nghiệp. Dòng sản phẩm này bao gồm ba kích thước mô hình, đều được cấp phép Apache 2.0 và được huấn luyện trên 15 nghìn tỷ token. Tuy nhiên, điều thực sự gây ấn tượng mạnh mẽ không phải là số lượng token, mà là hiệu suất của phiên bản 8B.
Có một kết quả cụ thể trong các bài kiểm tra benchmark khiến nhiều người phải ngạc nhiên: Mô hình Granite 4.1 với 8 tỷ tham số (8B) đang cạnh tranh sòng phẳng hoặc thậm chí vượt qua các mô hình có kích thước gấp 4 lần.
Granite 4.1 của IBM
Hiệu suất bất ngờ của mô hình 8B
Trên ArenaHard, một tiêu chuẩn đo lường chất lượng chat thực tế thông qua việc GPT-4 đánh giá khả năng xử lý 500 câu hỏi khó, phiên bản 8B của Granite 4.1 đạt điểm 69.0. Điều đáng nói là thế hệ trước Granite 4.0-H-Small, một mô hình MoE (Mixture of Experts) 32B với 9B tham số hoạt động, lại có điểm số thấp hơn.
Tương tự cũng diễn ra trên BFCL V3 (tiêu chuẩn đo lường khả năng gọi công cụ), nơi Granite 4.1 8B đạt 68.3 điểm, vượt xa 64.7 điểm của mô hình 32B MoE cũ. Kết quả này lặp lại trên nhiều bài kiểm tra khác như GSM8K (toán học), MMLU-Pro, BBH và EvalPlus.
Một mô hình nhỏ hơn, đơn giản hơn và sử dụng kiến trúc Dense (dày đặc) thay vì MoE phức tạp lại đang chiến thắng một cách nhất quán. Điều này chứng minh rằng IBM đã cải thiện đáng kể kỹ thuật huấn luyện giữa các thế hệ, chuyển sự tập trung từ việc chỉ tăng quy mô tham số sang việc ám ảnh về chất lượng dữ liệu.
Ba kích thước, một triết lý xây dựng
Granite 4.1 có sẵn trong các phiên bản 3B, 8B và 30B. Cả ba đều sử dụng thiết kế transformer decoder-only Dense giống nhau, cùng một pipeline huấn luyện và chiến lược dữ liệu. Sự khác biệt duy nhất nằm ở kích thước. Không có định tuyến MoE, không có các lớp thưa thớt (sparse layers) hay chuỗi lý luận kéo dài làm phình chi phí token.
IBM đã thực hiện năm giai đoạn huấn luyện riêng biệt với các hỗn hợp dữ liệu, lịch trình tốc độ học và mục tiêu khác nhau.
- Giai đoạn 1: Phổ rộng với CommonCrawl (59%), mã nguồn (20%) và toán học (7%).
- Giai đoạn 2: Tăng tỷ lệ toán học lên 35% và mã nguồn lên 30%.
- Giai đoạn 3 & 4: Kết hợp các chuỗi lý luận chain-of-thought và dữ liệu hướng dẫn (instruction data).
- Giai đoạn 5: Mở rộng cửa sổ ngữ cảnh, đạt tối đa 512K token cho bản 8B và 30B.
Bộ lọc dữ liệu "không khoan nhượng"
IBM đã dành rất nhiều thời gian cho pipeline chất lượng dữ liệu của mình. Sau khi tiền huấn luyện (pre-training), họ cần biến mô hình cơ bản thành một phiên bản có thể tuân thủ hướng dẫn một cách đáng tin cậy. Tuy nhiên, dữ liệu xấu trong tập tinh chỉnh (fine-tuning) không bị bỏ qua mà sẽ được mô hình "học" theo.
Do đó, IBM đã xây dựng một hệ thống lọc trước khi bất kỳ mẫu tinh chỉnh nào chạm vào mô hình. Một LLM đóng vai trò giám khảo đã đánh giá mọi phản hồi của trợ lý dựa trên sáu chiều: tuân thủ hướng dẫn, tính chính xác, tính đầy đủ, sự ngắn gọn, tự nhiên và hiệu chuẩn. Các mẫu dưới ngưỡng điểm bị cắt bỏ. Đặc biệt, các ảo giác (hallucinations), tiền đề sai hoặc tính toán sai sẽ bị từ chối tự động.
Kết quả đầu ra là 4,1 triệu mẫu dữ liệu đã được tuyển chọn kỹ lưỡng.
Bốn vòng Học tập tăng cường (RL) và bài học từ sự cố
Đây là phần thú vị nhất trong bài báo về Granite 4.1. Sau khi tinh chỉnh, IBM đã chạy quá trình học tập tăng cường (RL) trong bốn giai đoạn tuần tự.
Giai đoạn 1 huấn luyện mô hình chung trên chín lĩnh vực. Giai đoạn 2 là RLHF để cải thiện tính hữu ích trong chat, giúp điểm AlpacaEval tăng vọt. Tuy nhiên, một sự cố đã xảy ra: Giai đoạn RLHF này làm giảm điểm số các bài kiểm tra toán học (GSM8K và DeepMind-Math).
Để khắc phục, Giai đoạn 3 là một chạy ngắn để ổn định danh tính và kiến thức. Giai đoạn 4 là một đợt RL chuyên biệt cho toán học nhằm phục hồi những gì RLHF đã làm hỏng. Kết quả là điểm số toán học không chỉ phục hồi mà còn vượt qua mức cơ bản.
Bảng xếp hạng hiệu năng chi tiết
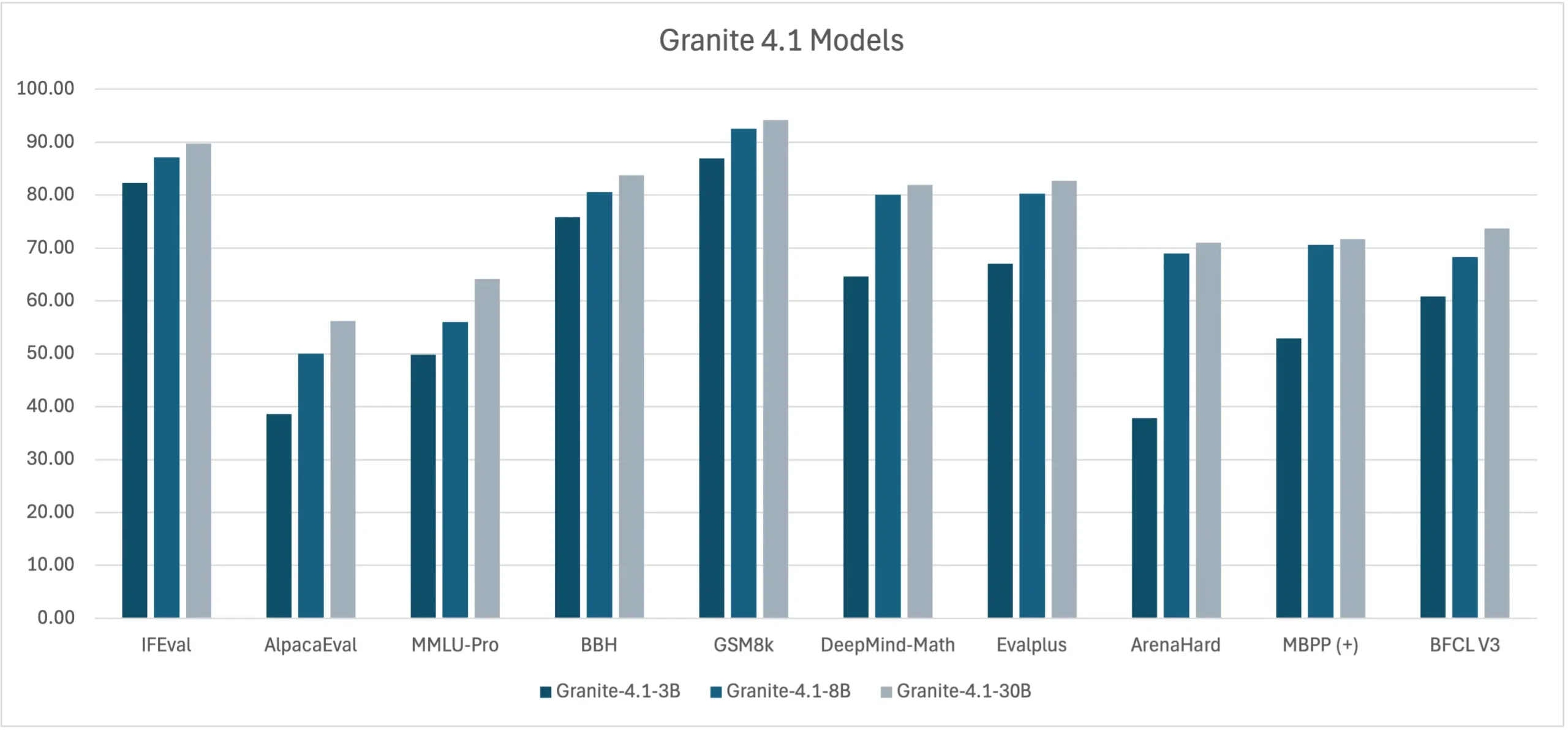 Bảng benchmark Granite 4.1
Bảng benchmark Granite 4.1
Dưới đây là một số con số ấn tượng từ các bài kiểm tra nội bộ của IBM:
| Tiêu chuẩn | Kiểm tra | 3B | 8B | 30B |
|---|---|---|---|---|
| IFEval | Tuân thủ hướng dẫn | 82.1 | 87.1 | 89.7 |
| BFCL V3 | Gọi công cụ (Tool calling) | 60.8 | 68.3 | 73.7 |
| GSM8K | Lý luận toán học | 87.0 | 92.5 | 94.2 |
| DeepMind-Math | Toán học nâng cao | 64.6 | 80.1 | 81.9 |
| EvalPlus | Lập trình | 67.1 | 80.2 | 82.7 |
| ArenaHard | Chất lượng chat thực tế | 37.8 | 69.0 | 71.0 |
Phiên bản 30B dẫn đầu bảng BFCL V3 của chính IBM với 73.7 điểm, vượt qua Gemma-4-31B. Bản 8B với 68.3 điểm đánh bại Granite 4.0-H-Small cũ (64.7). Đáng chú ý, bản 3B nhỏ gọn vẫn đạt 60.8 điểm trên BFCL V3, vượt qua Qwen3-8B (mô hình lớn gấp đôi).
Cửa sổ ngữ cảnh 512K token
Việc khiến mô hình xử lý 512K token là một thử thách, nhưng làm được điều đó mà không làm mô hình quên cách xử lý 4K token còn khó hơn. IBM giải quyết vấn đề này bằng cách tiếp cận mở rộng theo giai đoạn trong Giai đoạn 5: 32K -> 128K -> 512K.
Sau mỗi giai đoạn mở rộng, IBM thực hiện hợp nhất mô hình (model merge). Bằng cách hợp nhất checkpoint ngữ cảnh dài trở lại với các trọng số trước đó thay vì chỉ tiếp tục huấn luyện, họ đã bảo toàn các hành vi mà mô hình đã học ở độ dài ngắn.
Cách chạy và đối tượng phù hợp
Bạn có thể chạy Granite 4.1 dễ dàng thông qua Ollama. Bản 3B chạy mượt trên hầu hết máy tính cá nhân, bản 8B cần cấu hình tốt hơn một chút, còn bản 30B đòi hỏi máy có GPU rời. Tất cả đều có sẵn trên Hugging Face dưới namespace ibm-granite. Các biến thể lượng tử hóa FP8 cũng rất đáng thử nếu bộ nhớ bị hạn chế.
Nếu bạn đang xây dựng ứng dụng cần khả năng gọi công cụ đáng tin cậy, độ trễ dự đoán được và giấy phép Apache 2.0 không gây rắc rối pháp lý, Granite 4.1 đặc biệt là bản 8B, là một lựa chọn cực kỳ sáng giá. Đây là một dòng mô hình ưu tiên sản xuất từ một đội ngũ rõ ràng đã dành nhiều thời gian để khắc phục vấn đề hơn là chỉ hô hào về các con số trên lý thuyết.
Bài viết liên quan

Công nghệ
Vượt xa Prompt Engineering: Kiến tạo Hệ thống AI có Nhận thức Ngữ cảnh và Quản lý Bộ nhớ ở Quy mô lớn
10 tháng 6, 2026

Công nghệ
Anthropic và OpenAI mang cuộc chiến công nghệ sang chính trường Mỹ
20 tháng 5, 2026

Công nghệ
Threads cán mốc 500 triệu người dùng, ra mắt tính năng cá nhân hóa thuật toán mới
16 tháng 6, 2026