
Hướng dẫn toàn diện: Tối ưu hóa việc tóm tắt tài liệu khổng lồ bằng AI (Phần 2)
Tiếp nối phần 1, bài viết này đi sâu vào cách sử dụng kỹ thuật phân cụm (clustering) và chọn mẫu đại diện để tóm tắt hiệu quả các tài liệu lớn. Chúng ta sẽ khám phá quy trình Map-Reduce, giảm thiểu việc sử dụng token và cải thiện độ chính xác của các mô hình Generative AI.

Trong bài viết trước, chúng ta đã cùng nhau giải quyết một trong những thách thức lớn nhất trong việc tóm tắt tài liệu: làm thế nào để xử lý các tài liệu quá khổ mà một yêu cầu API đơn lẻ không thể gánh nổi. Chúng ta cũng đã thảo luận về những cạm bẫy của vấn đề nổi tiếng "Lost in the Middle" (Mất giữa) và chứng minh cách các kỹ thuật phân cụm như K-means có thể giúp cấu trúc và quản lý các đoạn thông tin hiệu quả.
Chúng ta đã chia Sổ tay Nhân viên GitLab thành các đoạn nhỏ (chunks), sử dụng mô hình nhúng (embedding model) để chuyển đổi những đoạn văn bản đó thành các biểu diễn số gọi là vector.
 Phân phối các nhãn cụm
Phân phối các nhãn cụm
Giờ đây, trong phần 2 đã được mong chờ từ lâu, chúng ta sẽ đi sâu vào trọng tâm của vấn đề. Với các cụm (clusters) đã có sẵn, chúng ta sẽ tập trung tinh chỉnh bản tóm tắt để đảm bảo không có ngữ cảnh quan trọng nào bị bỏ sót. Bài viết này sẽ hướng dẫn bạn qua các bước tiếp theo để biến các cụm thô thành những bản tóm tắt mạch lạc và có thể hành động được, từ đó cải thiện quy trình làm việc của Generative AI (GenAI) để xử lý ngay cả những nhiệm vụ tóm tắt tài liệu phức tạp nhất.
Ôn tập kỹ thuật nhanh
Trước khi bắt đầu, hãy nhanh chóng xem lại các bước kỹ thuật chúng ta đã thực hiện trong giải pháp này:
Các tệp cần thiết: Một tài liệu lớn, trong trường hợp này là Sổ tay Nhân viên GitLab.
Công cụ cần thiết:
- Ngôn ngữ lập trình: Python.
- Các gói thư viện: LangChain, LangChain Community, OpenAI, Matplotlib, Scikit-learn, NumPy và Pandas.
Các bước đã thực hiện:
- Tiền xử lý văn bản: Chia tài liệu thành các đoạn (chunks) để giới hạn lượng token sử dụng nhưng vẫn giữ được cấu trúc ngữ nghĩa.
- Kỹ thuật đặc trưng (Feature Engineering): Sử dụng mô hình nhúng của OpenAI để chuyển đổi các đoạn tài liệu thành vector nhúng, giữ lại biểu diễn ngữ nghĩa và cú pháp, giúp việc nhóm nội dung tương tự dễ dàng hơn cho các mô hình ngôn ngữ lớn (LLM).
- Phân cụm (Clustering): Áp dụng phân cụm K-means lên các vector nhúng đã tạo, nhóm các vector có ý nghĩa tương tự vào cùng một nhóm. Điều này giúp giảm dư thừa và đảm bảo độ chính xác khi tóm tắt.
Để dễ hình dung: Hãy tưởng tượng bạn đổ toàn bộ hồ sơ lưu trữ của một văn phòng xuống sàn. Khi bạn xếp đống tài liệu đó vào các thư mục, đó là "chunking". Việc nhúng sẽ gắn một "dấu vân tay" duy nhất cho những thư mục đó. Và cuối cùng, khi bạn phân loại các thư mục đó thành các chủ đề khác nhau như tài chính, chính sách, thì đó chính là "clustering".
Phân tích sâu các cụm dữ liệu
Bây giờ, hãy cùng xem xét kỹ hơn các cụm của chúng ta, vì đây là nền tảng cho bản tóm tắt. Chúng ta cần tạo ra một số thông tin chi tiết về các cụm để hiểu chất lượng và sự phân bổ của chúng.
Để thực hiện phân tích này, chúng ta cần sử dụng kỹ thuật Giảm chiều dữ liệu (Dimensionality Reduction). Đây đơn giản là việc giảm số lượng chiều của các vector nhúng. Như đã thảo luận, mỗi vector có thể có nhiều chiều (giá trị) để mô tả một từ/câu. Với mô hình của chúng ta, các vector được tạo ra có độ dài là 1272 chiều — một con số quá lớn để trực quan hóa (vì con người chỉ nhìn thấy được 3 chiều).
Hãy tưởng tượng việc cố gắng vẽ bản đồ mặt phẳng sơ sơ của một nhà kho khổng lồ chứa đầy các hộp được sắp xếp theo hàng trăm đặc điểm tinh tế. Bản đồ đó sẽ không bao gồm tất cả các chi tiết của nhà kho, nhưng vẫn cực kỳ hữu ích để xác định những hộp nào thường được nhóm lại với nhau.
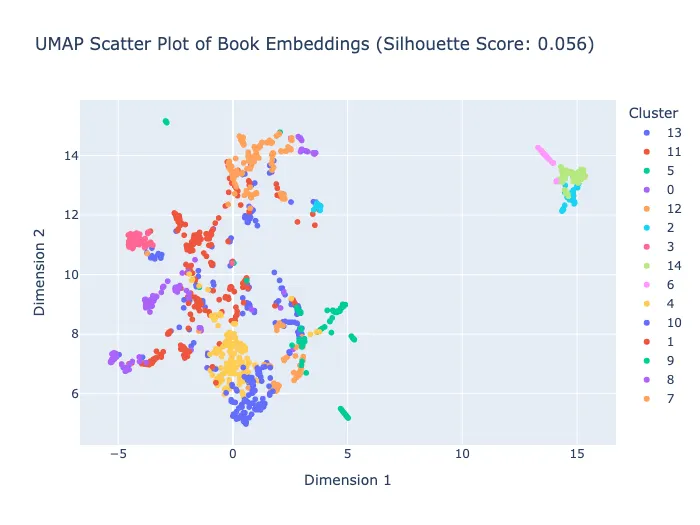
Chúng ta sử dụng UMAP (một phương pháp giảm chiều dữ liệu) để nén thông tin chiều cao xuống bản đồ 2D.
 Biểu đồ phân tán UMAP của các vector nhúng
Biểu đồ phân tán UMAP của các vector nhúng
Vậy chúng ta đang nhìn thấy gì ở đây? Mỗi dấu chấm là một đoạn văn bản từ sổ tay. Các dấu chấm có cùng màu thuộc về cùng một cụm. Khi các dấu chấm cùng màu tụ lại với nhau một cách gọn gàng, điều đó cho thấy cụm đó khá mạch lạc. Khi các màu khác nhau chồng chéo lên nhau nhiều, điều đó cho biết các chủ đề trong tài liệu có thể bị hòa lẫn vào nhau — điều này không quá ngạc nhiên đối với một sổ tay nhân viên thực tế pha trộn giữa chính sách, vận hành, quản trị và nhiều khía cạnh khác.
Một số nhóm trong biểu đồ khá nhỏ gọn và tách biệt về mặt thị giác, đặc biệt là ở phía bên phải. Những nhóm khác chồng chéo ở trung tâm giống như những người tham dự một sự kiện networking cứ di chuyển giữa các cuộc trò chuyện. Điều này cho thấy các cụm mang tính thông tin, nhưng không hoàn hảo tuyệt đối.
Đánh giá chất lượng cụm bằng các chỉ số
Chỉ nhìn biểu đồ là chưa đủ, chúng ta cần những con số cụ thể để đánh giá. Chúng ta sẽ sử dụng ba chỉ số chính:
-
Silhouette Score (Điểm Silhouette): 0.056. Hãy giải thích điểm này bằng ví dụ một bữa tiệc. Điểm Silhouette cao có nghĩa là hầu hết mọi người đứng gần nhóm của mình và xa những người khác. Điểm thấp có nghĩa là mọi người đang lơ lửng giữa các nhóm, lắng nghe nửa vời hai cuộc trò chuyện. Ở đây, 0.056 là thấp, cho thấy các chủ đề trong sổ tay chồng chéo khá nhiều. Tuy nhiên, điều này không lý tưởng nhưng cũng không loại trừ khả năng sử dụng.
-
Calinski-Harabasz Score: 25.184. Chỉ số này thưởng cho các cụm có nội dung chặt chẽ và tách biệt tốt với nhau. Hãy tưởng tượng căn tin của một trường học. Nếu mỗi nhóm bạn ngồi gần nhau tại bàn riêng và các bàn được tách biệt tốt, căn tin trông có tổ chức. Điểm số của chúng ta cho thấy có một số cấu trúc trong dữ liệu.
-
Davies-Bouldin Score: 3.567. Chỉ số cuối cùng đo độ chồng chéo giữa các cụm; càng thấp càng tốt. Điểm số này cho thấy có sự chồng chéo ý nghĩa nhưng không quá nhiều để duy trì sự tách biệt mối quan tâm lành mạnh.
Ba chỉ số này đủ để chúng ta tự tin tiếp tục với kỹ thuật phân cụm của mình.
Chọn đại diện cho các cụm
Bây giờ chúng ta đã biết các cụm hữu ích, câu hỏi tiếp theo là: làm thế nào để tóm tắt chúng mà không phải tóm tắt tất cả 1360 đoạn một cách riêng lẻ? Câu trả lời là chọn một ví dụ đại diện từ mỗi cụm.
Đây là nơi phép toán xảy ra. Mỗi cụm là một nhóm các số, và trong nhóm đó sẽ có một trung tâm, được gọi là trọng tâm (centroid). Chúng ta đo khoảng cách từ mỗi đoạn đến trọng tâm này (khoảng cách Euclidean). Các vector có khoảng cách Euclidean nhỏ nhất với trọng tâm tương ứng của chúng sẽ được chọn từ mỗi cụm.
Điều này giống như việc rút ra tờ giấy nói lên nhiều điều nhất từ mỗi chồng tài liệu. Thay vì để LLM đọc qua tất cả các trang, nó chỉ cần xử lý các ví dụ nổi bật nhất. Kết quả là chúng ta chỉ còn 15 đoạn được chọn lựa chiến lược thay vì tất cả 1360 đoạn. Đây là một sự giảm thiểu công sức nghiêm trọng mà không cần đoán mò.
 Xem trước các bản tóm tắt
Xem trước các bản tóm tắt
Quy trình tóm tắt Map-Reduce
Cuối cùng, chúng ta đã đến bước tóm tắt thực sự. Chúng ta sẽ áp dụng quy trình kiểu "map-reduce":
- Map (Ánh xạ): Tóm tắt từng đoạn đại diện riêng lẻ. Chúng ta yêu cầu mô hình: "Hãy lấy một đoạn tại một thời điểm và giải thích nó kỹ lưỡng." Điều này dễ dàng hơn nhiều cho mô hình so với việc cố gắng lý luận toàn bộ sổ tay trong một lần.
- Reduce (Giảm): Sau khi có 15 bản tóm tắt cục bộ, chúng ta yêu cầu LLM tóm tắt những bản tóm tắt đó thành một tổng quan chung.
Kết quả và Đánh giá
Chúng ta đã kết hợp 15 bản tóm tắt lại với nhau. Tổng số token của tài liệu trung gian mới này là 4219 token. Đây là một thành công rực rỡ so với con số 220.035 token của tài liệu gốc. Chúng ta đã đạt được mức giảm 98% việc tiêu thụ token trong cửa sổ ngữ cảnh!
Tuy nhiên, bản tóm tắt cuối cùng có một điểm hơi "lệch": nó tập trung nhiều hơn vào các phần hệ thống demo và Kubernetes của sổ tay so với sự lan rộng đầy đủ các chủ đề chúng ta thấy trước đó. Điều này không có nghĩa là quy trình thất bại, mà cho thấy bước tổng hợp cuối cùng (reduce) cần được tinh chỉnh thêm để đảm bảo bao quát tất cả các chủ đề lớn.
Kết luận
Phần 1 là về việc tồn tại qua vấn đề quy mô. Phần 2 là về việc biến chiến lược tồn tại đó thành một quy trình tóm tắt thực tế.
Phân cụm giúp giải quyết vấn đề quy mô. Việc chọn đoạn đại diện giúp quy trình có cấu trúc hơn. Nhưng prompt tóm tắt cuối cùng vẫn cần tinh chỉnh để bao quát toàn bộ tài liệu. Đối với tôi, đó là giá trị thực tế của thí nghiệm này. Nó mang lại cho chúng ta một thứ hữu ích ngay bây giờ, và cũng chỉ ra rõ ràng những gì chúng ta cần sửa chữa tiếp theo.
Đây không phải là một kết thúc hoàn hảo "nhiệm vụ hoàn thành", mà là một bước tiến vững chắc trong việc biến việc tóm tắt tài liệu lớn bằng AI trở nên khả thi và hiệu quả hơn.
Bài viết liên quan
Phần mềm
BootProof: "Nút chạy" trung thực cho các kho mã nguồn, ưu tiên bằng chứng thay vì cảm tính
11 tháng 6, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026

Phần mềm
Shii haa: Ứng dụng biến micro điện thoại thành cảm biến phát hiện nhịp thở
02 tháng 6, 2026