
Inference Scaling: Tại sao các mô hình suy luận lại làm đội chi phí điện toán của bạn?
Các mô hình AI thế hệ mới như GPT-5.5 và dòng o1 đang ưu tiên tính toán tại thời điểm suy luận (test-time compute) để nâng cao độ chính xác, dẫn đến việc gia tăng tiêu thụ token và chi phí hạ tầng. Bài viết phân tích tác động của inference scaling lên độ trễ, tài nguyên GPU và chiến lược tối ưu hóa chi phí cho doanh nghiệp.

Trong nhiều năm qua, việc làm cho một mô hình thông minh hơn thường đồng nghĩa với việc tăng số lượng tham số trong quá trình đào tạo. Tuy nhiên, ngày nay các mô hình hàng đầu như GPT 5.5 và dòng o1 đạt hiệu suất cao bằng cách chi tiêu nhiều tài nguyên tính toán hơn cho từng phản hồi đơn lẻ.
Quá trình này được gọi là inference scaling (mở rộng suy luận) hoặc test-time compute (tính toán tại thời điểm kiểm tra). Nó cho phép mô hình sử dụng sức mạnh xử lý bổ sung trong quá trình tạo phản hồi để tự kiểm tra logic của mình và lặp lại cho đến khi tìm ra câu trả lời tốt nhất. Đối với các đội ngũ sản phẩm, điều này biến việc lựa chọn mô hình thành một sự đánh đổi vận hành rủi ro cao. Bật chế độ suy luận không chỉ đơn thuần là một công tắc tùy chọn, mà là một cam kết tài nguyên thích ứng.
 So sánh Training-Time Scaling và Inference-Time Scaling
So sánh Training-Time Scaling và Inference-Time Scaling
Inference Scaling là gì (và không phải gì)?
Về mặt truyền thống, trí thông minh của mô hình được cố định trong quá trình đào tạo. Việc mở rộng quy mô đào tạo (training-time scaling) liên quan đến việc chi hàng triệu USD cho GPU để tạo ra một mạng nơ-ron tĩnh. Ngược lại, inference scaling dịch chuyển việc phân bổ tài nguyên đó sang giai đoạn tạo phản hồi. Thay vì thực hiện một lần chuyển tiếp (forward pass) cho mọi yêu cầu, mô hình sẽ tốn thêm sức mạnh xử lý để tìm kiếm câu trả lời tốt nhất trong khi người dùng chờ đợi.
Về mặt vận hành, chế độ suy luận hoạt động bằng cách tạo ra các token tư duy ẩn (hidden thinking tokens). Nó sử dụng chuỗi tư duy (chain of thought) để điều hướng logic trước khi hoàn thiện phản hồi thông qua ba cơ chế chính:
- Phân rã (Decomposition): Phá vỡ các vấn đề đa bước thành logic trung gian.
- Tự sửa lỗi (Self-Correction): Xác định các lỗi nội bộ và lặp lại trong quá trình tư duy.
- Lựa chọn chiến lược (Strategic Selection): Tạo ra nhiều câu trả lời nội bộ để chấm điểm và chọn ra kết quả chính xác nhất.
Kết quả là một mô hình chi tiêu thích ứng cho từng câu lệnh. Các tác vụ dễ như tóm tắt cơ bản sẽ rẻ và nhanh vì mô hình nhận thấy không cần logic phức tạp. Tuy nhiên, các câu lệnh khó, chẳng hạn như xem xét kiến trúc hệ thống phân tán, sẽ được cấp ngân sách tính toán lớn hơn. Trong các trường hợp này, mô hình tạm dừng để tạo ra hàng nghìn token nhằm xác minh lý do của mình.
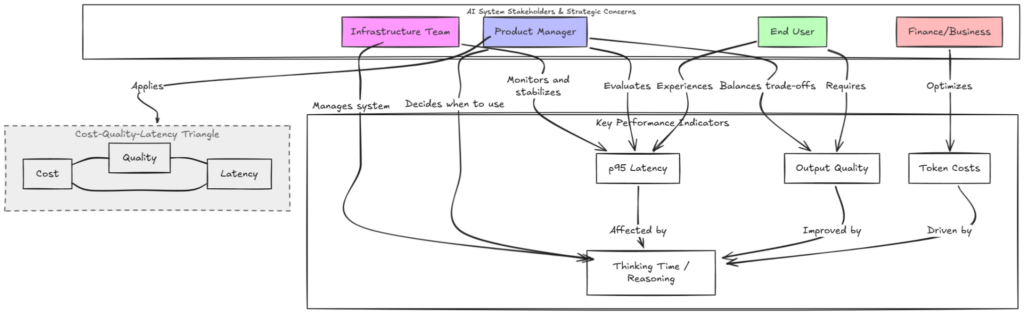
Tam giác Chi phí – Chất lượng – Độ trễ
Tam giác Chi phí – Chất lượng – Độ trễ là khuôn khổ thiết yếu cho mọi quyết định suy luận. Các đội ngũ phải xác định từng góc bằng các số liệu phù hợp với ưu tiên của kỹ thuật và tài chính.
 Tam giác Cost-Quality-Latency trong AI
Tam giác Cost-Quality-Latency trong AI
- Chi phí (Cost): Bao gồm cả token đầu ra hiển thị và token suy luận ẩn được tạo ra trong các vòng lặp tư duy nội bộ, cùng với các lần thử lại dùng để xác minh logic. Nó cũng đo thời gian GPU trên mỗi yêu cầu. Vì các mô hình này chiếm dụng bộ nhớ phần cứng trong thời gian dài hơn, chúng làm giảm tổng số đồng thời của hệ thống, buộc các đội ngũ phải mở rộng phần cứng hoặc hạn chế quyền truy cập của người dùng.
- Chất lượng (Quality): Đo lường hiệu quả thông qua tỷ lệ thành công nhiệm vụ và tỷ lệ lỗi của ảo giác (hallucinations). Các đội ngũ cũng sử dụng kiểm tra tính thực tế và điểm rubric, nơi một mô hình giám khảo chấm điểm logic hoặc giọng điệu.
- Độ trễ (Latency): Tập trung vào số liệu p50 và p95. Trong khi p50 cho thấy trải nghiệm điển hình, p95 giám sát 5% yêu cầu chậm nhất. Các độ trễ từ tư duy phức tạp có thể kích hoạt thời gian chờ khiến ứng dụng bị lỗi.
Hồ sơ ưu tiên độ trễ cao cho chatbot sẽ ưu tiên tốc độ và chấp nhận rủi ro logic cao hơn. Ngược lại, hồ sơ ưu tiên chất lượng cao cho quy hoạch kiến trúc sẽ chấp nhận độ trễ và chi phí token cao hơn để đảm bảo kết quả chính xác.
Tại sao hóa đơn lại "bùng nổ" trong môi trường sản xuất
Nghiên cứu của Apple Machine Learning Research đã xác định một khoảng cách hiệu quả nguy hiểm giữa các mô hình suy luận và LLM tiêu chuẩn. Nghiên cứu này phát hiện ra rằng Các Mô hình Suy luận Lớn (Large Reasoning Models) thường rơi vào "cái bẫy tư duy", nơi chúng đốt hàng nghìn token cho các tác vụ đơn giản như cộng 1 vào 9900. Với các mục có độ phức tạp thấp này, các mô hình tiêu chuẩn cung cấp độ chính xác tốt hơn mà không tốn thêm chi phí.
Các mô hình suy luận phá vỡ định giá tuyến tính truyền thống bằng cách giới thiệu hai hệ số nhân riêng biệt ảnh hưởng đến cả ngân sách và hạ tầng:
- Leo thang chi phí trên mỗi yêu cầu: Việc tiêu thụ token không còn tuyến tính. Các mô hình như GPT 5.5 sử dụng tư duy xen kẽ để tạo ra token suy luận trước và sau khi gọi công cụ. Cách tiếp cận dựa trên tìm kiếm này khám phá nhiều đường dẫn logic, mở rộng sử dụng tính toán theo cấp số nhân tương đối với độ phức tạp của nhiệm vụ.
- Giảm dung lượng và đồng thời: Ngay cả khi giá token giảm, việc chiếm dụng phần cứng vẫn là điểm nghẽn. Một mô hình tiêu chuẩn dự đoán trong một giây trong khi mô hình suy luận có thể chiếm dụng bộ nhớ GPU trong ba mươi giây. Việc chiếm dụng kéo dài này làm giảm tổng số người dùng mà phần cứng của bạn có thể phục vụ cùng lúc.
Khi chế độ suy luận làm mọi thứ tồi tệ hơn
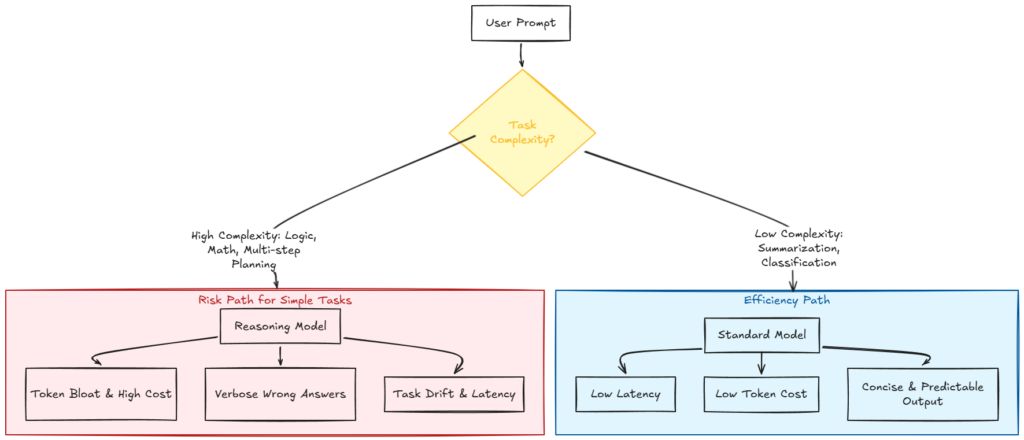
Inference scaling là một công cụ chuyên biệt chứ không phải là một nâng cấp chất lượng phổ quát. Kích hoạt chế độ suy luận cho các tác vụ độ phức tạp thấp như tóm tắt hoặc giải thích cơ bản tạo ra sự quá tải vận hành. Điều này tiêu tốn đáng kể tài nguyên tính toán và ngân sách mà không mang lại lợi ích đo lường được về độ chính xác đầu ra.
Một kịch bản cụ thể minh họa sự đánh đổi này trong phân loại khối lượng lớn. Với câu lệnh phân loại chó, giấy, mèo, trứng và phô mai vào các danh mục:
- Một mô hình tiêu chuẩn cung cấp danh sách có cấu trúc trong vòng dưới 200 mili-giây.
- Một mô hình suy luận có thể tạo ra hàng trăm token ẩn để tranh luận về mối quan hệ phát sinh loài giữa các vật nuôi hoặc lịch sử công nghiệp của giấy.
Mặc dù đầu ra cuối cùng là giống hệt nhau, nhưng mô hình suy luận phải chịu độ trễ và chi phí token cao hơn đáng kể. Trong môi trường sản xuất, đây là một loại "thuế thông minh" cho một nhiệm vụ không yêu cầu logic phức tạp.
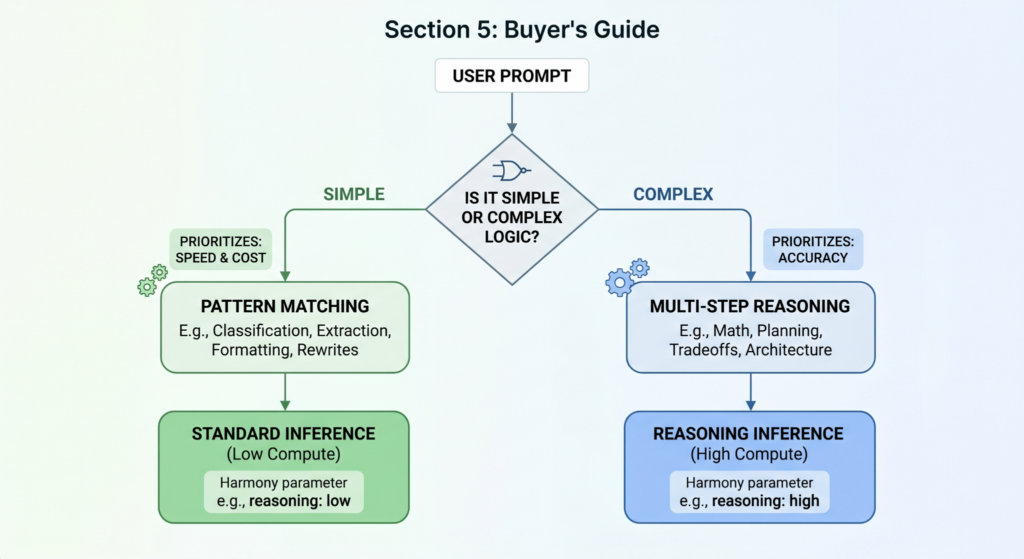
Hướng dẫn mua sắm: Khi nào nên trả tiền cho việc "suy nghĩ"
Để hình dung tác động của phân loại nhiệm vụ, hãy xem xét một đội ngũ phát triển đang xây dựng trợ lý lập trình. Ban đầu, họ định tuyến tất cả lưu lượng truy cập đến một mô hình suy luận mạnh mẽ để đảm bảo chất lượng. Tuy nhiên, họ phát hiện ra rằng 70% yêu cầu là cho các tác vụ đơn giản như định dạng mã, kiểm tra cú pháp và hoàn thành cơ bản.
 Biểu đồ tối ưu hóa chi phí cho Reasoning Models
Biểu đồ tối ưu hóa chi phí cho Reasoning Models
Bằng cách triển khai chính sách định tuyến, đội ngũ đã đạt được kết quả sau:
- Nhiệm vụ Đơn giản (70%): Giảm từ 2.100 USD/ngày xuống còn 70 USD/ngày.
- Nhiệm vụ Suy luận (30%): Giữ nguyên ở 900 USD/ngày.
- Tổng chi phí hàng ngày: Giảm từ 3.000 USD xuống còn 970 USD.
- Chi phí hàng năm: Tiết kiệm hơn 740.000 USD mỗi năm mà không làm giảm chất lượng của trợ lý lập trình.
Việc triển khai chế độ suy luận hiệu quả đòi hỏi sự chuyển dịch từ kỹ thuật prompt engineering chung sang quản lý tài nguyên chiến lược. Các quyết định nên dựa trên mật độ logic của nhiệm vụ và hậu quả kinh doanh của một lỗi sai.
Phân loại nhiệm vụ cho Test-Time Compute:
- Sử dụng (Use): Toán học, lập kế hoạch đa bước, các đánh đổi phức tạp. (Chi phí lỗi cao; logic phải được xác minh).
- Có thể (Maybe): Kiến trúc mã, tổng hợp rủi ro cao. (Độ chính xác cấu trúc quan trọng hơn nhu cầu độ trễ).
- Tránh (Avoid): Trích xuất, phân loại, định dạng, viết lại. (Khối lượng lớn, độ phức tạp thấp; tốc độ là ưu tiên).
Quản trị vận hành
Quản trị chuyển đổi inference scaling từ một thí nghiệm sang một chính sách sản xuất. Các nguyên tắc chính bao gồm:
- Định tuyến trước (Route First): Triển khai một bộ phân loại nhanh, rẻ để xác định độ phức tạp của câu lệnh. Chỉ nâng cấp các câu lệnh yêu cầu logic đa bước lên các mô hình suy luận.
- Áp dụng có chọn lọc (Selective Application): Không sử dụng suy luận cho toàn bộ quy trình làm việc. Chỉ áp dụng nó cho các nút logic cụ thể nơi độ chính xác là quan trọng.
- Giới hạn cứng (Hard Caps): Đặt giới hạn nghiêm ngặt về số lượng token suy luận tối đa, số lần thử lại và tổng thời gian yêu cầu để ngăn chặn các vòng lặp logic gây ra các đợt tăng giá hóa đơn không thể đoán trước.
Chuyển sang kỷ nguyên của inference scaling có nghĩa là chúng ta phải ngừng coi LLM như những chiếc hộp kỳ diệu và bắt đầu coi chúng như bất kỳ tài nguyên kỹ thuật đắt đỏ nào khác. Các mô hình suy luận cực kỳ mạnh mẽ cho lập trình rủi ro cao và toán học phức tạp, nhưng chúng là quá mức cần thiết cho định dạng cơ bản hoặc phân loại.
Những đội ngũ chiến thắng trong kỷ nguyên mới sẽ không phải là những đội ngũ có ngân sách tính toán lớn nhất, mà là những đội ngũ có quản trị thông minh nhất. Bằng cách sử dụng phân loại nhiệm vụ vững chắc và định tuyến có chọn lọc, bạn có thể giữ biên lợi nhuận lành mạnh mà không hy sinh chất lượng sản phẩm. Hãy coi các token suy luận như một tài nguyên quý giá, áp dụng chúng vào nơi thực sự cần thiết và để các mô hình nhanh của bạn xử lý phần còn lại.
Bài viết liên quan

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026

AI & ML
NSA được cho đang tích hợp AI Anthropic vào các hoạt động tấn công mạng bất chấp lệnh cấm
05 tháng 6, 2026
Công nghệ
Chủ đề từ LLM không phải là dữ liệu quan sát: Cảnh báo cho các nhà phân tích dữ liệu
21 tháng 5, 2026