
Khi "Bytes" nói mọi ngôn ngữ: Cách AI vượt qua rào cản chữ viết trong việc đối chiếu tên
Bài toán đối chiếu tên người qua các hệ thống chữ viết khác nhau luôn là thách thức lớn cho các hệ thống kiểm soát. Bài viết này giới thiệu một phương pháp sử dụng mô hình Transformer nhỏ gọn hoạt động trực tiếp trên byte UTF-8 kết hợp với kỹ thuật Contrastive Learning, giúp thu hẹp khoảng cách hiệu suất giữa các truy vấn Latin và không Latin tới 10 lần so với phương pháp cổ điển.

Khi "Bytes" nói mọi ngôn ngữ: Cách AI vượt qua rào cản chữ viết trong việc đối chiếu tên
Mỗi khi một hệ thống sàng lọc kiểm tra tên đối với danh sách đen, nó thường đối mặt với một "thất bại thầm lặng" mà ít ai bàn tới. Hãy thử nhập "Владимир Путин" vào một hệ thống được lập chỉ mục bằng "Vladimir Putin", hầu hết các phương pháp đối chiếu tên sẽ không trả về kết quả nào. Hai chuỗi ký tự này không có ký tự nào chung, khiến khoảng cách chỉnh sửa (edit distance) trở nên vô nghĩa, các mã âm thanh (phonetic codes) thất bại (vì chúng giả định dùng chữ Latin), và BM25 cũng hoàn toàn bó tay.
Đây không phải là một trường hợp ngoại lệ hiếm gặp. Các cơ sở dữ liệu nhập cư, hệ thống hồ sơ bệnh viện và các quy trình tuân thủ tài chính đều phải đối mặt với vấn đề này hàng ngày. Tuy nhiên, các phương pháp tiếp cận chủ yếu hiện nay vẫn là cổ điển (khoảng cách chỉnh sửa, các biến thể Soundex) hoặc quá nặng nề (fine-tune một mô hình ngôn ngữ đa ngữ trên vài trăm cặp dữ liệu thủ công). Trong bài viết này, chúng ta sẽ khám phá cách một nhóm nghiên cứu đã đào tạo một bộ mã hóa Transformer nhỏ gọn từ đầu trên các byte UTF-8 thô, không cần bộ phân tích từ (tokenizer), không cần xương sống tiền huấn luyện (pretrained backbone) và không cần phát hiện chữ viết, để giải quyết bài toán truy xuất tên âm thanh đa chữ viết.
Tại sao bài toán này lại khó?
Thách thức nằm ở giao điểm của ba yếu tố không tương thích:
Các hệ thống chữ viết là các tập hợp ký tự rời rạc. "Schwarzenegger" và "שוורצנגר" (tiếng Do Thái) không có ký tự chung. Khoảng cách chỉnh sửa, phương pháp mặc định cho khớp mờ (fuzzy matching), luôn cho ra điểm số tối đa mỗi khi vượt qua ranh giới chữ viết. Băm âm thanh (như Double Metaphone, Soundex) mã hóa phát âm approximated tiếng Anh, nên về thiết kế nó vô dụng với các truy vấn không phải chữ Latin.
Chuyển đổi sang chữ Latin (Romanization) không phải là một hàm đơn nhất. Tên tiếng Trung "张" có thể chuyển thành Zhang, Chang, hoặc Cheung tùy thuộc vào phương ngữ, tiêu chuẩn chuyển đổi và quy ước lịch sử. Tên tiếng Hàn "박" có thể là Park, Pak, hoặc Bak. Bất kỳ phương pháp nào cố gắng chuẩn hóa về một dạng Latin chuẩn (như ICU transliterate) sẽ đúng cho một quy ước nhưng thất bại với các quy ước khác.
Tên không mang ngữ cảnh ngữ nghĩa. Các phương pháp truy xuất dày đặc (dense retrieval) như DPR và BGE-M3 rất mạnh mẽ cho các nhiệm vụ cấp câu vì các từ xung quanh cung cấp ngữ cảnh. Với một tên người chỉ có 2 từ, không có ngữ cảnh để bù đắp cho sự không khớp về bề mặt.
Sự đột phá: Mô hình hóa ở cấp độ Byte
Sự thật đơn giản đằng sau cách tiếp cận này là: mọi ký tự Unicode đều phân giải một cách xác định thành 1 đến 4 byte từ một bảng chữ cái cố định gồm 256 ký hiệu. "Владимир" và "Vladimir" là các chuỗi byte khác nhau, nhưng một mô hình được đào tạo tương phản (contrastively) trên đủ các cặp âm thanh có thể học cách ánh xạ chúng đến các vector gần nhau. Từ vựng theo định nghĩa là phổ quát.
Xây dựng dữ liệu đào tạo quy mô lớn
Không thể đào tạo mô hình này mà không có dữ liệu, và không có sẵn bộ dữ liệu 4 triệu cặp tên âm thanh đa chữ viết nào cả. Các nhà nghiên cứu đã xây dựng một bộ dữ liệu thông qua quy trình LLM gồm 4 giai đoạn.
 Quy trình tạo dữ liệu
Quy trình tạo dữ liệu
Giai đoạn 1: Lấy mẫu phân tầng từ Wikidata. Bắt đầu với 2 triệu thực thể tên người từ Wikidata. Lấy mẫu ngẫu nhiên sẽ tạo ra dữ liệu bị chi phối bởi tên tiếng Anh. Họ phân tầng theo nhóm phạm vi chữ viết và lấy mẫu tỷ lệ trong mỗi nhóm để có độ phủ cân bằng.
Giai đoạn 2: Biến thể âm thanh Latin (Llama-3.1-8B). Với mỗi tên gốc tiếng Anh, họ yêu cầu Llama-3.1-8B-Instruct tạo ra 4 biến thể chính tả âm thanh — các loại lỗi nghe chính tả mà người thật thường mắc phải.
Giai đoạn 3: Chuyển đổi đa chữ viết (Qwen3-30B). Với mỗi tên tiếng Anh và các biến thể Latin của nó, họ tạo ra các bản chuyển đổi sang 8 chữ viết: Ả Rập, Nga, Trung, Nhật, Do Thái, Hindi, Hy Lạp, Hàn.
Giai đoạn 4: Hợp nhất và gắn thẻ. Giai đoạn cuối hợp nhất các nhãn thực tế từ Wikidata với đầu ra của LLM, loại bỏ trùng lặp và gắn thẻ mỗi cặp dương (positive pair) theo loại: âm thanh, chữ viết, hoặc kết hợp.
Kết quả là một bộ dữ liệu khổng lồ: 119.040 thực thể, 4,67 triệu cặp dương.
Mô hình ByteLevelEncoder
Bộ mã hóa này thực sự nhỏ gọn: 6 lớp Transformer, 8 đầu attention, chiều ẩn 256, FFN 1024, dropout 0.1, độ dài tối đa 256 byte. Tổng số tham số: ~4 triệu.
Điểm thú vị là mô hình này hoạt động trực tiếp trên byte UTF-8 thô. Nó sử dụng nn.Embedding với kích thước từ vựng là 256 (tương ứng với các byte có thể có). Việc sử dụng pre-norm (chuẩn hóa trước) là rất quan trọng khi đào tạo Transformer từ đầu để ổn định gradient.
Đầu ra là một vector đơn vị trong 256 chiều. Độ tương đồng Cosine chính là tích vô hướng trên các vector đơn vị, do đó việc truy xuất chỉ đơn giản là một phép tính dot product.
Chiến lược đào tạo: InfoNCE và Hard Negative Mining
Hàm mất mát được sử dụng là tiêu chuẩn InfoNCE: một cặp (neo, dương) nên có tích vô hướng cao; tích vô hướng của neo với mọi dương khác trong lô (các âm trong lô) nên thấp.
Tuy nhiên, các mẫu âm trong lô (in-batch negatives) thì rẻ nhưng nông: chúng là những tên ngẫu nhiên, dễ tách biệt. Mô hình sớm sẽ dễ dàng phân biệt "Catherine" và "Zhao Wei". Điều khó khăn là phân biệt "Katarina" và "Katherine" — những tên nghe giống nhau nhưng là người khác nhau.
Đây là lý do cho kỹ thuật ANCE (Approximate Nearest Neighbour Contrastive Estimation): định kỳ xây dựng lại chỉ mục FAISS từ các nhúng của mô hình hiện tại, sau đó với mỗi neo, tìm các hàng xóm gần nhất không khớp và sử dụng chúng làm mẫu âm khó (hard negatives).
 Lịch trình đào tạo ANCE
Lịch trình đào tạo ANCE
Trong 200 bước đầu tiên: chỉ sử dụng lô ngẫu nhiên. Sau bước 200: chỉ mục FAISS được làm mới định kỳ. Tỷ lệ mẫu âm khó tăng tuyến tính từ 0 lên 0,7 sau 500 bước.
Đánh giá và Kết quả
Thiết lập truy xuất là tiêu chuẩn: kho ngữ liệu là 11.974 tên neo, mỗi cái được mã hóa thành vector và lưu trong chỉ mục FAISS. Mỗi biến thể dương trong tập kiểm tra được dùng làm truy vấn.
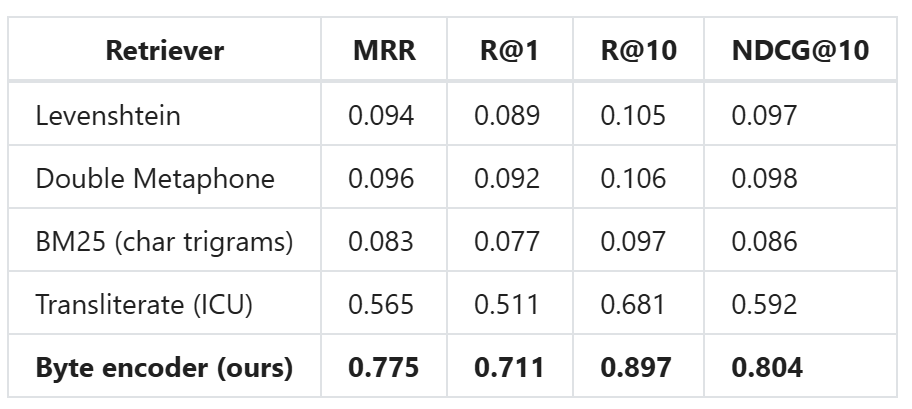
Kết quả tổng thể: Các phương pháp cơ sở cổ điển (Levenshtein, Double Metaphone, BM25) có MRR chỉ khoảng 0,09. Điều này nghe tệ, nhưng thực tế là do 70% truy vấn kiểm tra là đa chữ viết, nơi các phương pháp này đạt điểm gần 0 vì không có ký tự chung.
Mô hình ByteLevelEncoder đạt được 0,775 MRR và 0,897 R@10 trên 8 chữ viết không phải Latin, giảm khoảng cách hiệu suất giữa truy vấn Latin và không Latin xuống 10 lần so với phương pháp cổ điển tốt nhất.
 So sánh hiệu suất
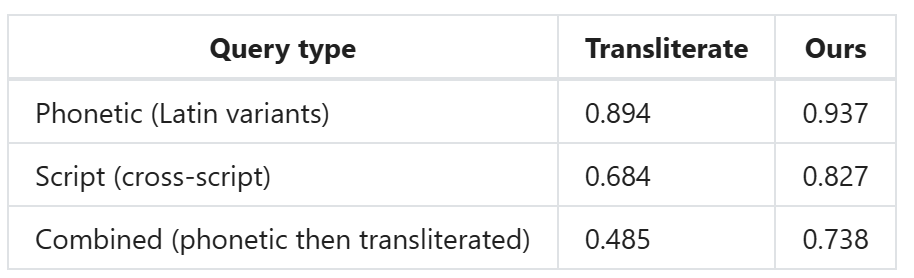
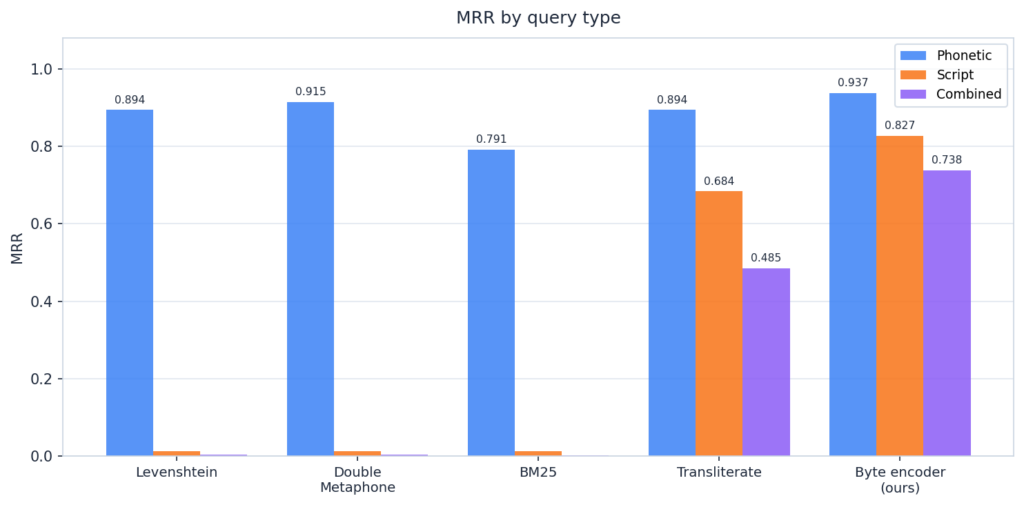
So sánh hiệu suất
Mô hình duy trì hiệu suất mạnh mẽ trên cả ba loại truy vấn (âm thanh, chữ viết, kết hợp). Khoảng cách chữ viết (script gap) — sự chênh lệch R@10 giữa Latin và không Latin — được giảm từ mức 0,88-0,94 của các phương pháp cổ điển xuống chỉ còn 0,096.
Những hạn chế và bài học
Mô hình không thể hoàn toàn đóng lại khoảng cách với tiếng Trung và tiếng Hàn. Lý do là sự mơ hồ trong chuyển đổi sang chữ Latin (ví dụ: "张" có thể là Zhang, Chang, Cheung). Dữ liệu đào tạo chứa tất cả các biến thể này là dương cho cùng một thực thể, tạo ra tín hiệu gradient xung đột.
Ngoài ra, quy trình dữ liệu chỉ tạo ra biến thể không phải Latin bằng cách chuyển đổi từ Latin. Nó không bao gồm các biến thể chính tả trong cùng một chữ viết gốc (ví dụ: các quy tắc chính tả Ả Rập thay thế).
Các điểm chính rút ra:
- Tokenization cấp độ byte là một công cụ bị sử dụng ít cho các nhiệm vụ đa ngữ. Nó loại bỏ các token ngoài từ vựng (out-of-vocabulary), không cần bộ phân tích từ cụ thể cho ngôn ngữ và cung cấp một từ vựng phổ quát 256 ký hiệu.
- LLM là động cơ dữ liệu khả thi cho các nhiệm vụ truy xuất tài nguyên thấp. Quy trình 4 giai đoạn này có thể tổng quát hóa cho các bài toán khớp thực thể khác.
- Hard Negative Mining (ANCE) rất quan trọng. Chuyển đổi từ mẫu âm ngẫu nhiên sang mẫu âm khó được khai thác từ ANN giúp làm sắc không gian nhúng đáng kể.
- Báo cáo kết quả theo loại truy vấn và chữ viết, không chỉ MRR tổng thể. Một con số trung bình có thể che giấu những biến động lớn về hiệu năng thực tế.
Mã nguồn, quy trình dữ liệu và checkpoint đã được công bố trên GitHub, mở ra hướng đi mới cho việc xử lý ngôn ngữ tự nhiên ở cấp độ thấp nhất của dữ liệu văn bản.
Bài viết liên quan

Công nghệ
Google thay đổi hoàn toàn thanh tìm kiếm: Bước nhảy vọt với Gemini 3.5 Flash và Tác nhân AI
19 tháng 5, 2026

Phần mềm
Tấn công Cache Poisoning biến các gói npm TanStack thành mối đe dọa nguy hiểm
12 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026