
Ridge, Lasso hay ElasticNet? Bài học từ 134.400 lần mô phỏng giúp chọn đúng kỹ thuật Regularization
Nghiên cứu quy mô lớn từ các kỹ sư tại Instacart so sánh hiệu quả của Ridge, Lasso và ElasticNet qua 134.400 mô phỏng. Kết quả cho thấy ElasticNet là lựa chọn tối ưu cho việc chọn biến số trong dữ liệu phức tạp, trong khi Ridge đủ tốt cho hầu hết các bài toán dự đoán.
Ridge, Lasso, hay ElasticNet? Bài học từ 134.400 lần mô phỏng giúp chọn đúng kỹ thuật Regularization
Nếu bạn từng huấn luyện một mô hình tuyến tính bằng scikit-learn, bạn chắc chắn đã từng đứng trước câu hỏi: Nên dùng RidgeCV, LassoCV, hay ElasticNetCV? Có thể bạn đã chọn theo mặc định từ một hướng dẫn nào đó, hoặc nghe theo ý kiến của đồng nghiệp, hoặc đơn giản là thử cả ba và chọn cái có điểm cross-validation (CV) cao nhất.
Để thay thế trực giác bằng các quyết định thực nghiệm, chúng tôi đã thực hiện một nghiên cứu quy mô lớn với 134.400 mô phỏng dựa trên các mô hình Machine Learning thực tế đang vận hành. Câu trả lời cho việc chọn bộ điều chuẩn (regularizer) phụ thuộc vào mục tiêu bạn đang tối ưu hóa và một chỉ số chẩn đoán duy nhất mà bạn có thể tính toán trước khi khớp mô hình.
 Mô phỏng so sánh các kỹ thuật Regularization
Mô phỏng so sánh các kỹ thuật Regularization
Các phát hiện chính
Trước khi đi sâu vào chi tiết kỹ thuật, đây là những điểm nhấn quan trọng nhất từ nghiên cứu:
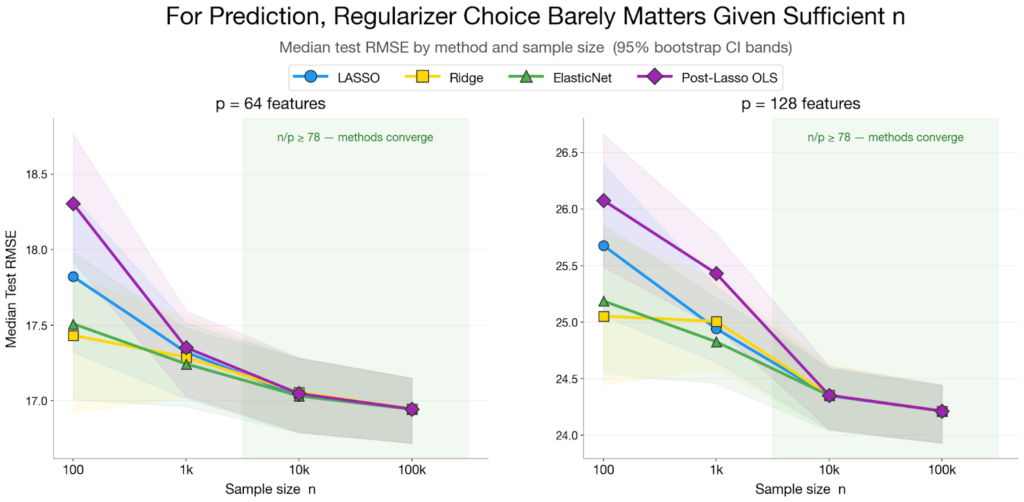
- Đối với dự đoán (Prediction): Sự khác biệt là không đáng kể. Ridge, Lasso và ElasticNet chênh lệch nhau tối đa 0,3% về median RMSE. Không có siêu tham số nào tạo ra hiệu ứng kích thước nhỏ cho sự khác biệt RMSE giữa chúng. Điều này chỉ đúng khi dữ liệu huấn luyện đủ lớn (trên 78 quan sát cho mỗi đặc trưng).
- Đối với lựa chọn biến số (Variable Selection): Sự khác biệt là cực kỳ lớn, đặc biệt trong điều kiện đa cộng tuyến (multicollinearity). Khả năng thu hồi (recall) của Lasso sụt giảm xuống 0,18 dưới các số điều kiện cao với tín hiệu yếu, trong khi ElasticNet duy trì mức 0,93.
- Tỷ lệ mẫu trên đặc trưng lớn (n/p ≥ 78): Các phương pháp trở nên có thể thay thế cho nhau. Hãy dùng Ridge vì nó nhanh nhất.
- Post-Lasso OLS nên tránh: Đây là phương pháp duy nhất hoạt động kém hiệu quả nhất trên mọi mục tiêu chúng tôi đo lường.
Nghiên cứu này kiểm tra những gì?
Chúng tôi đã biến đổi đồng thời bảy siêu tham số trong không gian mô phỏng, bao gồm kích thước mẫu, đặc trưng, đa cộng tuyến, tỷ lệ tín hiệu trên nhiễu (SNR), tính thưa thớt của hệ số và các tham số khác. Khung mô phỏng của chúng tôi không phải là ngẫu nhiên mà được dựa trên tám mô hình ML thực tế tại Instacart, bao gồm dự báo nhu cầu, dự đoán chuyển đổi và thông tin tồn kho.
 Biểu đồ so sánh hiệu suất
Biểu đồ so sánh hiệu suất
Chúng tôi đã chạy bốn khung regularization (Ridge, Lasso, ElasticNet và Post-Lasso OLS) trên 960 cấu hình siêu tham số, mỗi cấu hình sử dụng 35 hạt giống ngẫu nhiên, tổng cộng là 134.400 mô phỏng. Chúng tôi đo lường ba chỉ số chính: độ chính xác dự đoán (test RMSE), lựa chọn biến số (F1 score) và ước lượng hệ số (L2 error).
Phát hiện 1: Đối với dự đoán, chỉ cần dùng Ridge
Đây là phát hiện quan trọng nhất đối với số lượng lớn các kỹ sư thực hành. Ridge, Lasso và ElasticNet gần như thay thế được cho nhau trong mục đích dự đoán. Phân tích omega-squared của chúng tôi xác nhận điều này: không có siêu tham số đơn lẻ nào đạt được kích thước hiệu ứng nhỏ (ω² ≥ 0,01) cho sự khác biệt RMSE giữa ba phương pháp này.
Kết luận thực tế: Hãy mặc định sử dụng RidgeCV. Kích thước mẫu quan trọng hơn nhiều so với việc chọn bộ điều chuẩn. Tuy nhiên, dự đoán không phải là mục tiêu duy nhất đáng để tối ưu hóa.
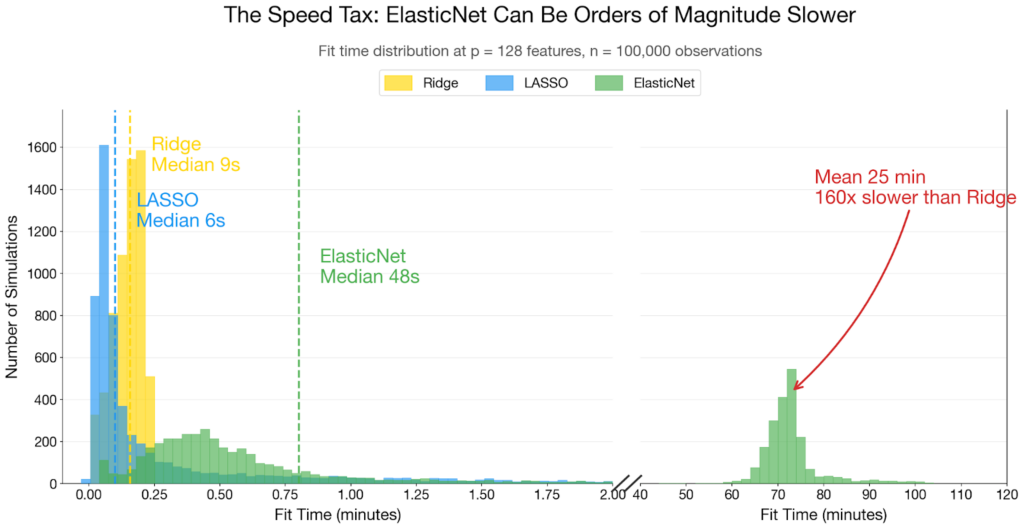
Phát hiện 2: Đối với lựa chọn biến số, ElasticNet là lựa chọn an toàn
Ở đây, việc chọn phương pháp thực sự quan trọng. Lựa chọn biến số – nhiệm vụ xác định các đặc trưng thực sự đóng góp vào kết quả – là mục tiêu nhạy cảm nhất với bộ điều chuẩn.
Kích thước mẫu chi phối áp đảo. Nhưng khi bạn ở chế độ mẫu nhỏ (n/p thấp), các yếu tố khác trở nên quan trọng, đặc biệt là đa cộng tuyến.
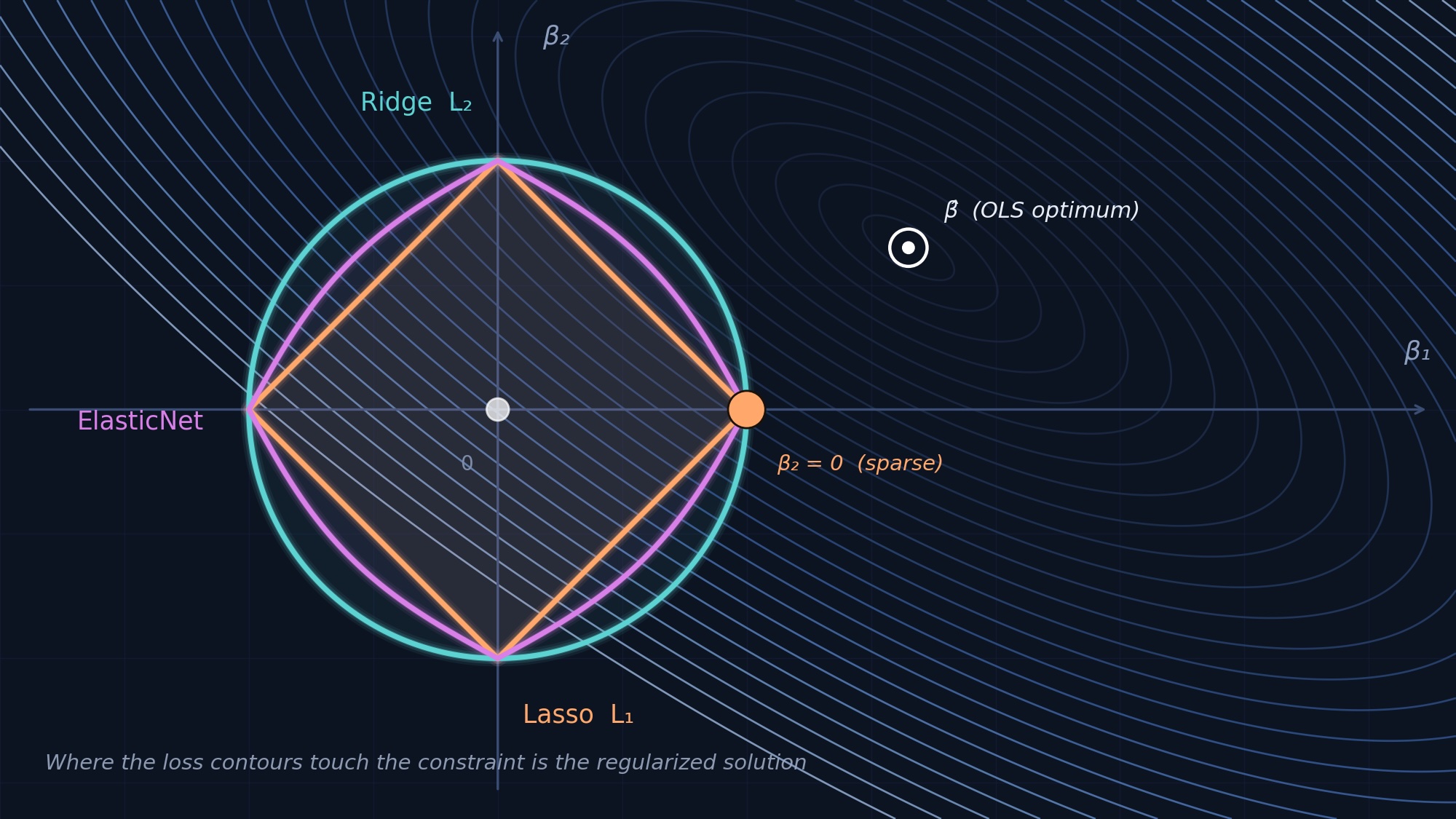
Đa cộng tuyến cao (κ ~ 10⁴): Đừng dùng Lasso
Đây là một trong những phát hiện mạnh mẽ nhất của nghiên cứu. Nếu các đặc trưng của bạn có tương quan vừa phải (điều gần như chắc chắn xảy ra với bất kỳ tập hợp đặc trưng kỹ thuật nào), phát hiện này áp dụng cho bạn.
Trong điều kiện số điều kiện (κ) cao với SNR thấp:
- Recall của Lasso: 0,18 (nó bỏ lỡ 82% các đặc trưng thực).
- Recall của ElasticNet: 0,93 (nó bắt được 93% các đặc trưng thực).
Cơ chế thì đã được biết đến rộng rãi: Khi các đặc trưng có tương quan cao, Lasso sẽ tùy ý chọn một cái từ mỗi nhóm tương quan và đưa các cái còn lại về 0. Thành phần phạt L2 của ElasticNet, hay còn gọi là "hiệu ứng nhóm" (grouping effect), giữ các đặc trưng tương quan lại với nhau.
 Sơ đồ quyết định lựa chọn mô hình
Sơ đồ quyết định lựa chọn mô hình
Khung quyết định thực tế
Dựa trên các phát hiện, chúng tôi đề xuất quy trình sau để chọn bộ điều chuẩn phù hợp:
- Nếu n/p ≥ 78: Hãy dùng Ridge. Dành ngân sách tinh chỉnh của bạn cho việc khác.
- Nếu n/p < 78 và κ cao (đa cộng tuyến): Hãy dùng ElasticNet và đừng nghi ngờ nữa.
- Nếu n/p < 78 và κ thấp: Sử dụng kiến thức lĩnh vực. Mô hình thưa thớt -> Lasso. Mô hình dày đặc -> Ridge.
Chẩn đoán α: Một proxy miễn phí cho SNR
Tham số tiềm ẩn quan trọng nhất cho các quyết định chi tiết là tỷ lệ tín hiệu trên nhiễu (SNR), có thể ước tính với chi phí bằng không. Khi scikit-learn's LassoCV khớp dữ liệu của bạn, nó trả về giá trị α được chọn. Giá trị này tỷ lệ nghịch với SNR cơ bản: α cao tín hiệu yếu, α thấp tín hiệu mạnh.
Các giá trị α được chọn cao nhất (tiếp cận 10⁴–10⁵) tập trung hoàn toàn trong các cấu hình mẫu nhỏ, SNR thấp. Bạn có thể sử dụng giá trị này làm hướng dẫn sơ bộ cho tình trạng dữ liệu của mình.
Kết luận: Quy mô mẫu dữ liệu là trên hết
Một điều rút ra quan trọng hơn bất kỳ hướng dẫn nào ở cấp độ phương pháp: Việc tăng tỷ lệ mẫu trên đặc trưng (n/p) làm được nhiều hơn cho mọi mục tiêu so với bất kỳ lựa chọn bộ điều chuẩn nào.
Kích thước mẫu là yếu tố chi phối sự khác biệt về hiệu suất trên cả ba chỉ số. Nếu bạn đang dành hàng ngày để tinh chỉnh bộ điều chuẩn trong khi có thể mở rộng tập huấn luyện của mình, bạn đang tối ưu hóa sai thứ.
Trong mọi trường hợp không chắc chắn về SNR, tính thưa thớt, hoặc đang hoạt động trong phạm vi κ trung gian: ElasticNet là lựa chọn mặc định an toàn, và Post-Lasso OLS nên tránh xa.
Bài viết này được tổng hợp và biên tập dựa trên nghiên cứu của Ahsaas Bajaj và Benjamin S Knight từ Instacart.
Bài viết liên quan
Công nghệ
Chủ đề từ LLM không phải là dữ liệu quan sát: Cảnh báo cho các nhà phân tích dữ liệu
21 tháng 5, 2026

Công nghệ
Tấn công mạng làm tê liệt nhà máy đường lớn tại Australia, nông dân không thể thu hoạch
17 tháng 6, 2026

Công nghệ
OpenAI tặng ưu đãi Codex đặc biệt cho 8.000 developer sau khi tiệc GPT-5.5 cháy vé
05 tháng 5, 2026