
Săn lùng lỗi mạng trong Kubernetes: Khi AI phát hiện lỗi WireGuard trên GKE
Đội ngũ kỹ sư của Lovable đã sử dụng tác nhân AI để phát hiện lỗi crash liên tục trong các pod mạng anetd trên Google Kubernetes Engine (GKE). Sau khi khắc phục sự cố liên quan đến WireGuard theo đề xuất của Google, họ lại đối mặt với vấn đề về sự không khớp MTU gây mất kết nối Valkey. Bài viết chia sẻ quy trình gỡ rối phức tạp trong hệ thống phân tán và vai trò đột phá của AI trong việc phân tích log.
Tuần trước, người dùng của chúng tôi bắt đầu gặp phải những lỗi vô lý. Đôi khi việc mở dự án thất bại, đôi khi việc clone mã nguồn từ GitHub lại bị timeout. Chúng tôi thậm chí còn nhận được thông báo lỗi đáng sợ "Connection reset by peer" (Kết nối bị đồng nghiệp ngắt). Không có một mẫu lỗi rõ ràng nào cả, và đó luôn là loại mẫu tồi tệ nhất.
Trên một nền tảng như Lovable, nơi hiện tại tạo ra hơn 50 sandbox mỗi giây trong giờ cao điểm, ngay cả một tỷ lệ thất bại nhỏ cũng có thể trở thành vấn đề lớn đối với người dùng. Có gì đó đang rung chuyển trong hạ tầng của chúng tôi, và chúng tôi cần tìm ra nó.
Theo dấu vết
Sascha, một trong những kỹ sư hạ tầng của chúng tôi, đã bắt đầu từ nơi mà bất kỳ buổi gỡ rối nào cũng nên bắt đầu: các tệp nhật ký (logs). Tuy nhiên, chúng tôi có hàng triệu dòng log cần sàng lọc và các mẫu lỗi không tự hiện ra. Ông ấy quyết định thử một cách tiếp cận mới. Ông ấy đã thử nghiệm các tác nhân AI để gỡ lỗi, và đây dường như là thời điểm thích hợp để dựa vào chúng. Ông ấy thiết lập một tác nhân có quyền truy cập vào logs ClickHouse của chúng tôi và bắt đặt câu hỏi.
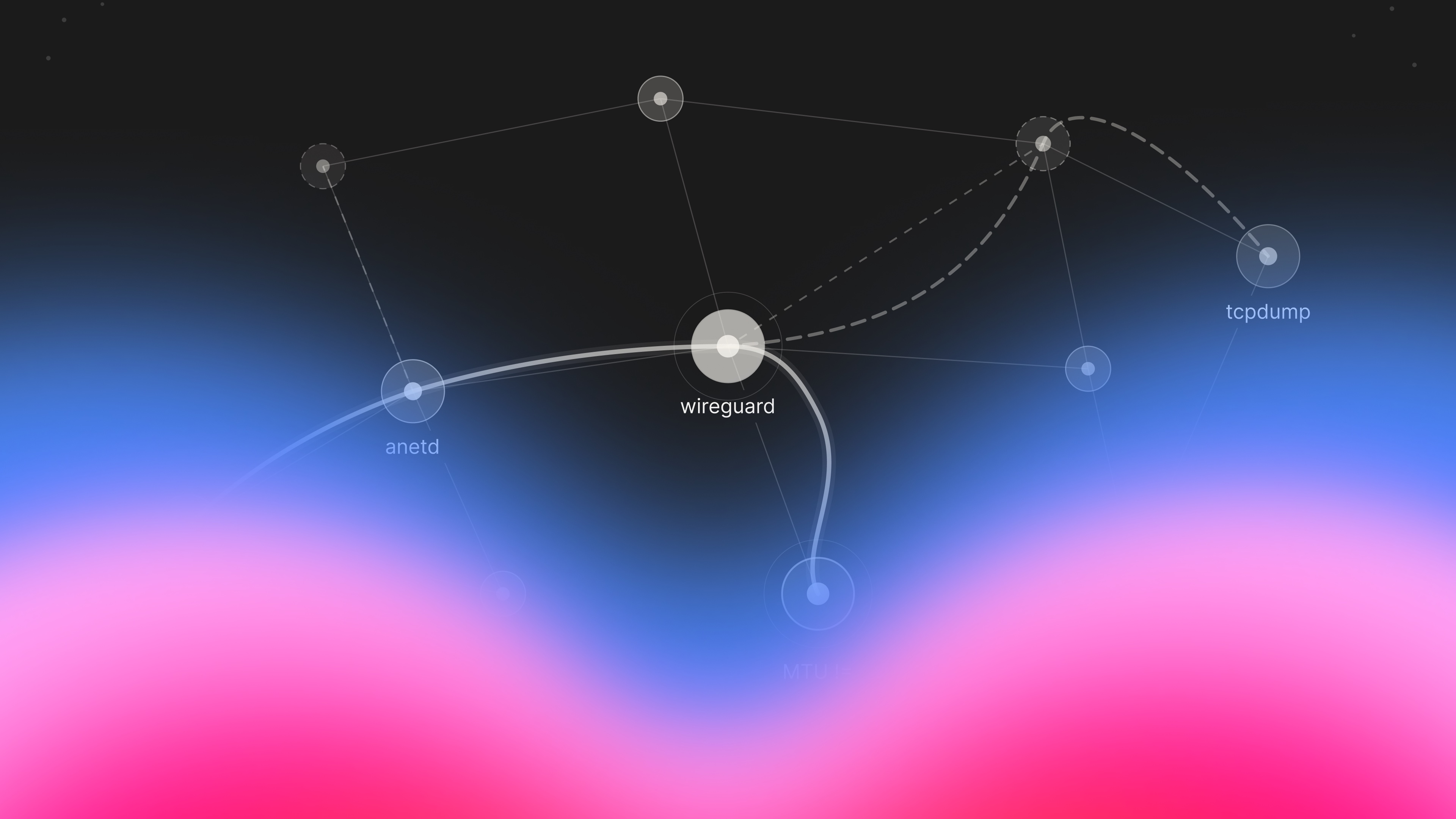
Tác nhân AI đã làm nổi bật một vấn đề đáng ngờ: các pod anetd trong cụm Google Kubernetes Engine (GKE) của chúng tôi đang khởi động lại liên tục, khoảng 120 lần khởi động lại cho mỗi pod trong sáu ngày, gần như là một lần crash mỗi giờ. Chắc chắn, điều này không thể ổn!
Để bạn dễ hình dung, anetd là bản triển khai Cilium của Google, lớp mạng bên trong các cụm Kubernetes của chúng tôi. Khi anetd bị crash, các pod mới không thể lấy được giao diện mạng. Và khi toàn bộ sản phẩm của bạn phụ thuộc vào việc liên tục tạo ra các sandbox mới, sự bất ổn của mạng sẽ nhanh chóng dẫn đến những lỗi mà người dùng phải đối mặt.
Sascha đã đào sâu vào các bản dump crash. Stack trace chỉ ra một lỗi panic khi truy cập đồng thời vào bản đồ (concurrent map-access panic), nhiều goroutine đang cố gắng đọc và ghi vào cùng một cấu trúc dữ liệu cùng một lúc mà không có cơ chế khóa (locking) phù hợp. Nhưng chi tiết then chốt nằm ở nơi lỗi panic xảy ra: bên trong module WireGuard của anetd.
WireGuard bản thân nó là một giao thức mã hóa nguồn mở, mà Google không sở hữu. Nhưng họ sở hữu mã tích hợp nó vào anetd, trình nền mạng của họ cho GKE. Lỗi panic đang xảy ra trong mã tích hợp của Google, cụ thể là ở cách họ quản lý việc truy cập đồng thời vào cấu trúc dữ liệu bản đồ theo dõi các kết nối WireGuard.
Vấn đề này quan trọng vì nó có nghĩa là lỗi nằm ở bản triển khai của Google, không phải ở WireGuard itself. Do đó, chúng tôi cần sự trợ giúp của Google để khắc phục nó.
Nhờ sự hỗ trợ
Chúng tôi đã gọi điện cho nhóm tài khoản của Google. Đó là một ngày Chủ Nhật, nhưng vấn đề này đang ảnh hưởng đến người dùng nên đội ngũ đã họp lại. Đề xuất của đại diện họ rất thẳng thắn: tắt mã hóa trong suốt node-to-node (transparent node-to-node encryption). Điều này sẽ bỏ qua hoàn toàn lỗi mà chúng tôi đang gặp phải trong module WireGuard.
Chúng tôi đã thảo luận về các sự đánh đổi. Việc tắt mã hóa giữa các node không lý tưởng về mặt bảo mật, nhưng cụm của chúng tôi đã chạy trên mạng riêng tư của Google, và sự ổn định tốt hơn sự hoàn hảo khi người dùng đang gặp lỗi. Chúng tôi đã triển khai thay đổi, khởi động lại tất cả các pod anetd và theo dõi các bảng điều khiển. Các vụ crash dừng lại. Trong khoảng bốn giờ, chúng tôi nghĩ rằng mình đã xong việc. Một số thành viên trong nhóm đã đăng xuất. Sau đó, các thông báo Slack bắt đầu đổ về lại.
Một dấu vết khác
Chúng tôi bắt đầu thấy các lỗi kết nối ngẫu nhiên tới Valkey, kho lưu trữ dữ liệu trong bộ nhớ (in-memory data store) của chúng tôi.
Ban đầu, chúng tôi nghi ngờ chính Valkey. Việc sử dụng CPU đang tăng lên. Chúng tôi đã tăng gấp đôi số lượng node để đảm bảo rằng nó không bị quá tải. Đáng buồn là, các lỗi vẫn tiếp tục xuất hiện.
Erik, một kỹ sư khác trong cuộc gọi, có một linh cảm. Chúng tôi không thay đổi bất kỳ mã ứng dụng nào, vì vậy vấn đề phải nằm sâu hơn trong ngăn xếp công nghệ (stack). Có lẽ là mạng. Ông ấy đã chạy tcpdump trên một vài node và bắt đầu bắt gói tin.
Trong khi phần còn lại của nhóm theo đuổi các manh mối tiềm năng khác, ông ấy lọc lưu lượng truy cập trong Wireshark. Sau đó ông ấy tìm ra bằng chứng phạm tội:
"Destination unreachable (Fragmentation needed)" (Đích đến không thể tiếp cận - Cần phân mảnh).
Đó là lúc mọi thứ bắt đầu khớp với nhau.
Sự không khớp MTU: "Chúng ta sẽ cần một gói tin lớn hơn"
Đây là những gì đang xảy ra: Khi WireGuard được bật, cụm của chúng tôi sử dụng MTU (đơn vị truyền tải tối đa) là 1420 byte để tính đến chi phí mã hóa của WireGuard. Thông thường, Ethernet sử dụng MTU tiêu chuẩn là 1500 byte.
Khi chúng tôi tắt WireGuard, chúng tôi mong đợi cấu hình sẽ thay đổi để sử dụng đầy đủ 1500 byte. Tuy nhiên, một số node trong cụm chưa được khởi động lại. Chúng vẫn đang sử dụng MTU cũ là 1420 byte.
Vấn đề này đặc biệt ảnh hưởng đến các kết nối Valkey vì chúng được phân phối trên các node có cài đặt MTU không khớp nhau. Vì vậy, tùy thuộc vào việc pod API của bạn đang chạy trên node nào, bạn có thể kết nối tốt... hoặc thất bại một cách bí ẩn. Giải pháp rất đơn giản một khi chúng tôi hiểu ra: khởi động lại (reroll) tất cả các node để có cấu hình MTU nhất quán trên toàn cụm.
Giải quyết vấn đề
Cuộc gọi Chủ Nhật đó kéo dài hơn ba tiếng. Chúng tôi đã chia sẻ màn hình, đi qua các stack trace và bắt gói tin, xác nhận các giả thuyết. Có sự hợp tác tốt với đội ngũ của Google. Họ nhận ra lỗi anetd ngay lập tức khi chúng tôi chỉ ra bằng chứng. Không có nhiều khách hàng tạo và xóa pod với khối lượng như chúng tôi, vì vậy chúng tôi đã phát hiện ra một vấn đề mà họ chưa bắt kịp.
Các hệ thống phân tán hiếm khi thất bại chỉ ở một lớp. Các vụ crash WireGuard là lớp đầu tiên. Sự không khớp MTU bị ẩn bên dưới, chỉ trở nên hiển thị sau khi chúng tôi khắc phục vấn đề ban đầu.
Chúng tôi đã theo dõi các bảng điều khiển lỗi cho đến khi các lỗi kết nối Valkey biến mất. Đến khi các lỗi cuối cùng được xóa sạch, chúng tôi đều cảm thấy tự hào về thành quả. Đã là đêm muộn Chủ Nhật, và chúng tôi quyết định theo dõi qua Thứ Hai trước khi tuyên bố toàn thắng, nhưng cuộc khủng hoảng tức thời đã qua đi.
Bài học rút ra
Bài học thực sự ở đây là về các lỗi đa lớp. Khi bạn khắc phục một thứ trong hệ thống phân tán, bạn cần theo dõi kỹ lưỡng những gì sẽ xuất hiện tiếp theo. Chúng tôi hiện nay kỹ lưỡng hơn trong việc xác thực sau các thay đổi hạ tầng.
Đối với Sascha, sự cố này đã thay đổi hoàn toàn cách tiếp cận gỡ lỗi của ông ấy. Đây là lần đầu tiên ông ấy dựa nhiều vào các tác nhân AI để điều tra, và khả năng truy vấn logs ở quy mô lớn cũng như làm nổi bật các mẫu mà không cần phân tích thủ công là một bước ngoặt lớn. "Tôi chưa bao giờ quay lại cách cũ," ông ấy nói sau đó.
Đội ngũ cũng học được cách tin vào trực giác khi phản bác lại các nhà cung cấp. Erik đã đúng về vấn đề MTU ngay cả khi đánh giá ban đầu của Google không đồng ý. Niềm tin kỹ thuật đó rất quan trọng khi đối mặt với các vấn đề như thế này.
Về phần mình, Google đã vá lỗi đồng thời WireGuard. Chúng tôi không phải là người duy nhất được hưởng lợi từ bản sửa lỗi đó.
Làm việc trên các vấn đề như thế này
Nếu việc gỡ lỗi hạ tầng đám mây phức tạp nghe có vẻ thú vị với bạn, chúng tôi đang tuyển dụng tại Lovable. Chúng tôi làm việc trên các vấn đề kỹ thuật đầy thách thức mỗi ngày, và chúng tôi rất muốn có bạn trong đội ngũ.
Bài viết liên quan

Phần mềm
Startup Jedify huy động 24 triệu USD để trang bị ngữ cảnh kinh doanh cho tác nhân AI
10 tháng 6, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026
Công nghệ
Chủ đề từ LLM không phải là dữ liệu quan sát: Cảnh báo cho các nhà phân tích dữ liệu
21 tháng 5, 2026