
Sử dụng Local LLM để Phân loại Dữ liệu Văn bản Zero-Shot Hiệu quả
Bài viết chia sẻ một quy trình thực tế sử dụng Local LLM để phân loại dữ liệu văn bản hỗn loạn thành các danh mục có ý nghĩa mà không cần dữ liệu huấn luyện (labeled data). Phương pháp này tận dụng khả năng hiểu ngữ nghĩa của AI, vượt trội hơn so với các kỹ thuật phân cụm truyền thống trong việc xử lý các đoạn văn bản ngắn và phức tạp.
James Surowiecki từng viết rằng “các nhóm thông minh một cách đáng kinh ngạc và thường thông minh hơn những người thông minh nhất trong nhóm đó”. Ông đang nói về việc ra quyết định, nhưng nguyên tắc này cũng áp dụng cho phân loại: nếu đủ nhiều người mô tả cùng một hiện tượng, một hệ thống phân loại (taxonomy) sẽ bắt đầu hình thành, ngay cả khi không có hai người nào dùng cùng một cách diễn đạt. Thách thức nằm ở việc tách biệt tín hiệu này khỏi sự hỗn loạn.
Tôi có vài nghìn dòng dữ liệu văn bản tự do và cần phải làm chính xác điều đó. Mỗi dòng là một chú thích ngắn bằng ngôn ngữ tự nhiên giải thích lý do một phát hiện bảo mật tự động là không liên quan, chức năng nào cần dùng để khắc phục, hoặc thực hành viết code nào cần tuân theo. Một người viết “đây là code kiểm thử, không được triển khai ở đâu cả”. Một người khác viết “môi trường không phải sản xuất, an toàn để bỏ qua”. Người thứ ba viết “chỉ chạy trong pipeline CI/CD trong quá trình tích hợp”. Cả ba người đều nói về cùng một việc, nhưng không có hai người nào chia sẻ quá một hay hai từ.
Hệ thống phân loại đã ở đó rồi. Tôi chỉ cần công cụ phù hợp để trích xuất nó. Các kỹ thuật phân cụm và khớp từ khóa truyền thống không thể xử lý được sự biến thiên của cách diễn đạt, vì vậy tôi đã thử một thứ mà tôi chưa thấy được thảo luận nhiều: sử dụng Local LLM (Mô hình Ngôn ngữ Lớn chạy cục bộ) làm bộ phân loại zero-shot. Bài viết này sẽ khám phá hiệu suất của nó, cách hoạt động và một số mẹo để sử dụng và triển khai các hệ thống này.
Tại sao phân cụm truyền thống gặp khó khăn với văn bản tự do ngắn gọn
Phân cụm không giám sát tiêu chuẩn hoạt động bằng cách tìm sự gần nhau về mặt toán học trong một không gian đặc trưng nào đó. Đối với các tài liệu dài, điều này thường ổn. Đủ tín hiệu tồn tại trong tần suất từ hoặc vector nhúng để tạo thành các nhóm nhất quán. Nhưng văn bản ngắn, dày đặc ngữ nghĩa sẽ phá vỡ các giả định này theo một số cách cụ thể.
Độ tương đồng của nhúng (embedding similarity) gây nhầm lẫn giữa các nghĩa khác nhau. “Khóa này chỉ dùng trong phát triển” và “Khóa API này được hardcode để tiện lợi” tạo ra các vector nhúng tương tự vì từ vựng chồng chéo. Nhưng cái này nói về môi trường không sản xuất, còn cái kia nói về sự đánh đổi bảo mật có chủ đích. K-means hoặc DBSCAN không thể phân biệt được chúng vì các vector quá gần nhau.
Các mô hình chủ đề đưa ra từ ngữ, không phải khái niệm. Phân bổ Dirichlet tiềm ẩn (LDA) và các biến thể của nó tìm thấy các mẫu đồng xuất hiện của từ. Khi kho dữ liệu của bạn bao gồm các chú thích một câu, tín hiệu đồng xuất hiện từ quá thưa thớt để hình thành các chủ đề có ý nghĩa. Bạn sẽ nhận được các cụm được định nghĩa bởi “test”, “code” hoặc “security” thay vì các chủ đề mạch lạc.
Regex và khớp từ khóa không thể xử lý sự biến thiên của cách diễn đạt. Bạn có thể viết quy tắc để bắt “test code” và “non-production”, nhưng bạn sẽ bỏ lỡ “chỉ dùng trong CI”, “không bao giờ triển khai”, “fixture chỉ dành cho phát triển”, và hàng chục cách diễn đạt khác đều diễn đạt cùng một ý tưởng cơ bản.
Điểm chung: các phương pháp này hoạt động trên các đặc điểm bề mặt (token, vector, mẫu) thay vì ý nghĩa ngữ nghĩa. Đối với các nhiệm vụ phân loại mà ý nghĩa quan trọng hơn từ vựng, bạn cần một thứ hiểu được ngôn ngữ.
LLM làm bộ phân loại Zero-Shot
Sự thật cốt lõi rất đơn giản: thay vì yêu cầu thuật toán khám phá các cụm, hãy xác định các danh mục ứng viên của bạn dựa trên kiến thức lĩnh vực và yêu cầu mô hình ngôn ngữ phân loại từng mục.
Điều này hoạt động vì LLM xử lý ý nghĩa ngữ nghĩa, không chỉ là mẫu token. “Khóa này chỉ dùng trong phát triển” và “Môi trường không sản xuất, an toàn để bỏ qua” hầu như không có từ trùng lặp, nhưng mô hình ngôn ngữ hiểu rằng chúng diễn đạt cùng một ý tưởng. Điều này không chỉ là trực giác. Chae và Davidson (2025) đã so sánh 10 mô hình trên các chế độ huấn luyện zero-shot, few-shot và fine-tuned và nhận thấy rằng các LLM lớn ở chế độ zero-shot hoạt động cạnh tranh với BERT đã được fine-tune trên các nhiệm vụ phát hiện quan điểm. Wang và cộng sự (2023) nhận thấy LLM vượt trội hơn các phương pháp phân loại tiên tiến nhất trên ba trong số bốn bộ dữ liệu chuẩn chỉ bằng cách sử dụng zero-shot prompting, không cần dữ liệu huấn luyện có nhãn.
Thiết lập bao gồm ba thành phần:
- Danh mục ứng viên: Một danh sách các danh loại loại trừ lẫn nhau được định nghĩa từ kiến thức lĩnh vực. Trong trường hợp của tôi, tôi bắt đầu với khoảng 10 chủ đề dự kiến (code kiểm thử, xác thực đầu vào, bảo vệ khung, môi trường không sản xuất, v.v.) và mở rộng lên 20 ứng viên sau khi xem xét mẫu.
- Prompt phân loại: Được cấu trúc để trả về nhãn danh mục và một lý do ngắn. Nhiệt độ thấp (0.1) để đảm bảo tính nhất quán. Đầu ra tối đa ngắn (100 token) vì chúng ta chỉ cần một nhãn, không phải một bài luận.
- Local LLM: Tôi sử dụng Ollama để chạy các mô hình cục bộ. Không có chi phí API, không có dữ liệu rời khỏi máy của tôi và đủ nhanh cho hàng nghìn phân loại.
Dưới đây là phần cốt lõi của prompt phân loại:
CLASSIFICATION_PROMPT = """
Phân loại văn bản này vào một trong các chủ đề sau:
{themes}
Văn bản:
"{content}"
Chỉ phản hồi với số và tên chủ đề, cùng một lý do ngắn gọn.
Định dạng: THEME_NUMBER. THEME_NAME | Lý do
Phân loại:
"""
Và lệnh gọi Ollama:
response = ollama.generate(
model="gemma2",
prompt=prompt,
options={
"temperature": 0.1, # Nhiệt độ thấp để phân loại nhất quán
"num_predict": 100, # Phản hồi ngắn, ta chỉ cần nhãn
}
)
Có hai điều cần lưu ý. Thứ nhất, cài đặt nhiệt độ rất quan trọng. Ở mức 0.7 hoặc cao hơn, cùng một đầu vào có thể tạo ra các phân loại khác nhau trên các lần chạy. Ở mức 0.1, mô hình gần như xác định, giúp làm mượt quá trình phân loại. Thứ hai, giới hạn num_predict ngăn mô hình tạo ra các giải thích bạn không cần, giúp tăng tốc độ xử lý đáng kể.
Xây dựng quy trình xử lý (Pipeline)
Quy trình đầy đủ có ba bước: tiền xử lý, phân loại, phân tích.
Tiền xử lý loại bỏ nội dung thêm token nhưng không thêm tín hiệu phân loại. URL, các cụm từ mẫu (để biết thêm thông tin, xem...) và các lỗi định dạng đều bị loại bỏ. Các thuật ngữ phổ biến được chuẩn hóa (“false positive” trở thành “FP”, “production” trở thành “prod”) để giảm sự biến thiên của token. Khử trùng lặp theo băm nội dung loại bỏ các bản sao chính xác. Bước này đã giảm ngân sách token của tôi khoảng 30% và làm cho phân loại nhất quán hơn.
Phân loại chạy từng mục qua LLM với các danh mục ứng viên. Với khoảng 7.000 mục, việc này mất khoảng 45 phút trên MacBook Pro sử dụng Gemma 2 (9 tỷ tham số). Tôi cũng đã kiểm tra Llama 3.2 (3 tỷ tham số), nhanh hơn nhưng kém chính xác hơn một chút ở các trường hợp khó khi hai danh mục gần nhau. Gemma 2 xử lý các mục mơ hồ tốt hơn đáng kể.
Một mối quan tâm thực tế: các lần chạy dài có thể thất bại giữa chừng. Quy trình lưu các điểm kiểm tra (checkpoints) sau mỗi 100 phân loại, vì vậy bạn có thể tiếp tục từ nơi bạn dừng lại.
Phân tích tổng hợp kết quả và tạo biểu đồ phân phối. Dưới đây là hình ảnh kết quả đầu ra:
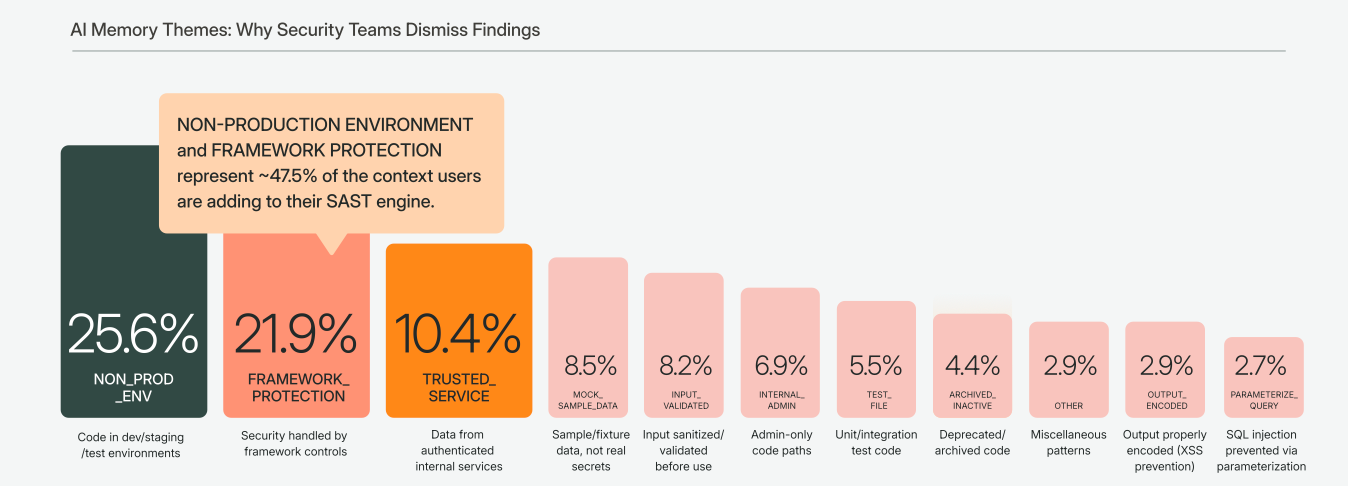 Biểu đồ phân phối các chủ đề được phân loại bởi LLM
Biểu đồ phân phối các chủ đề được phân loại bởi LLM
Biểu đồ kể một câu chuyện rõ ràng. Hơn một phần tư tất cả các mục mô tả code chỉ chạy trong môi trường không sản xuất. Một nhóm 21,9% khác mô tả các trường hợp mà khung bảo mật đã xử lý rủi ro. Chỉ hai danh mục này đã chiếm một nửa bộ dữ liệu, loại thông tin chi tiết rất khó để trích xuất từ văn bản không có cấu trúc bằng bất kỳ cách nào khác.
Khi phương pháp này không phù hợp
Kỹ thuật này hoạt động tốt nhất trong một ngách cụ thể: bộ dữ liệu quy mô vừa phải (hàng trăm đến hàng chục nghìn mục), văn bản phức tạp về ngữ nghĩa, và tình huống bạn có đủ kiến thức lĩnh vực để xác định các danh mục ứng viên nhưng không có dữ liệu huấn luyện có nhãn.
Nó không phải là công cụ phù hợp khi:
- Danh mục của bạn được định nghĩa bằng từ khóa (chỉ cần dùng regex),
- Bạn có dữ liệu huấn luyện có nhãn (huấn luyện một bộ phân loại có giám sát; nó sẽ nhanh hơn và rẻ hơn),
- Bạn cần độ trễ dưới giây ở quy mô lớn (sử dụng nhúng và tra cứu láng giềng gần nhất),
- Hoặc khi bạn thực sự không biết các danh mục nào tồn tại. Trong trường hợp này, hãy chạy mô hình hóa chủ đề khám phá trước để phát triển trực giác, sau đó chuyển sang phân loại LLM khi bạn có thể xác định danh mục.
Ràng buộc khác là thông lượng. Ngay cả trên máy nhanh, phân loại một mục mỗi một phần nhỏ của giây có nghĩa là 7.000 mục mất gần một giờ. Đối với bộ dữ liệu trên 100.000 mục, bạn sẽ muốn một mô hình được lưu trữ qua API hoặc chiến lược xử lý hàng loạt.
Các ứng dụng khác đáng để thử
Quy trình này có thể tổng quát hóa cho bất kỳ vấn đề nào bạn có văn bản không có cấu trúc và cần các danh mục có cấu trúc.
- Phản hồi của khách hàng: Các phản hồi NPS, vé hỗ trợ và kết quả khảo sát mở đều gặp phải cùng một vấn đề: cách diễn đa dạng cho một tập hợp hữu hạn các chủ đề cơ bản. “Ứng dụng của bạn bị crash mỗi khi tôi mở cài đặt” và “Trang cài đặt bị hỏng trên iOS” là cùng một danh mục, nhưng khớp từ khóa sẽ không bắt được điều đó.
- Phân loại lỗi (Bug triage): Mô tả lỗi dạng văn bản tự do có thể được tự động phân loại theo thành phần, nguyên nhân gốc rễ hoặc mức độ nghiêm trọng. Điều này đặc biệt hữu ích khi người báo lỗi không biết thành phần nào chịu trách nhiệm.
- Phân loại ý định code: Đây là cái tôi chưa thử nhưng thấy hấp dẫn: phân loại các đoạn code, quy tắc Semgrep hoặc quy tắc cấu hình theo mục đích (xác thực, truy cập dữ liệu, xử lý lỗi, ghi nhật ký). Cùng một kỹ thuật được áp dụng. Xác định danh mục, viết prompt phân loại, chạy kho dữ liệu qua mô hình cục bộ.
Bắt đầu như thế nào
Quy trình rất đơn giản: xác định danh mục của bạn, viết prompt phân loại và chạy dữ liệu của bạn qua mô hình cục bộ.
Phần khó nhất không phải là code. Đó là xác định các danh loại loại trừ lẫn nhau và cùng nhau bao quát (MECE). Lời khuyên của tôi: bắt đầu với mẫu 100 mục, phân loại chúng thủ công, chú ý những danh mục nào bạn thường xuyên sử dụng, và sử dụng những danh mục đó làm danh sách ứng viên của bạn. Sau đó để LLM mở rộng quy mô theo mẫu.
Tôi đã sử dụng kỹ thuật này như một phần của phân tích lớn hơn về cách các nhóm bảo mật khắc phục lỗ hổng. Kết quả phân loại đã giúp làm nổi bật loại ngữ cảnh bảo mật nào phổ biến nhất trên các tổ chức, và biểu đồ trên là một trong các đầu ra từ công việc đó. Nếu bạn quan tâm đến khía cạnh bảo mật, báo cáo đầy đủ có sẵn tại liên kết đó.
Bài viết liên quan

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026
AI & ML
MFA chỉ là bước khởi đầu: Tại sao xác thực thành công vẫn không ngăn chặn được tin tặc?
21 tháng 5, 2026

Phần cứng
Tổng quan tình hình trung tâm dữ liệu AI: Cuộc đua năng lượng, tranh cãi pháp lý và những bước đột phá phần cứng
08 tháng 5, 2026