
Thay thế PySpark bằng 4 tệp YAML: Cách để các nhà phân tích xây dựng Data Pipeline mà không cần kỹ sư
Mindbox đã thay thế các pipeline Python phức tạp bằng sự kết hợp của dlt, dbt và Trino. Cách tiếp cận khai báo này giúp rút ngắn thời gian triển khai từ vài tuần xuống còn một ngày, trao quyền cho các nhà phân tích tự xây dựng pipeline chỉ bằng YAML và SQL.
Trước đây, chúng tôi mất ba tuần để triển khai một pipeline dữ liệu duy nhất. Ngày nay, một nhà phân tích không có kinh nghiệm về Python có thể hoàn thành công việc này chỉ trong một ngày. Đây là câu chuyện về cách chúng tôi đạt được điều đó.
Tôi là Kiril Kazlou, một kỹ sư dữ liệu tại Mindbox. Đội ngũ của chúng tôi thường xuyên phải tính toán lại các chỉ số kinh doanh cho khách hàng, điều này đồng nghĩa với việc chúng tôi liên tục xây dựng các data mart (kho dữ liệu con) cho thanh toán và phân tích, đồng thời trích xuất dữ liệu từ hàng chục nguồn khác nhau.
Trong một thời gian dài, chúng tôi dựa vào PySpark để xử lý tất cả dữ liệu. Vấn đề nằm ở đâu? Bạn thực sự không thể làm việc với PySpark nếu không có kinh nghiệm về Python. Mỗi pipeline mới đều yêu cầu một lập trình viên. Và điều đó đồng nghĩa với việc phải chờ đợi — đôi khi là cả vài tuần.
Trong bài viết này, tôi sẽ hướng dẫn bạn cách chúng tôi xây dựng một nền tảng dữ liệu nội bộ, nơi một nhà phân tích hoặc quản lý sản phẩm có thể thiết lập một pipeline được cập nhật thường xuyên chỉ bằng cách viết bốn tệp YAML.
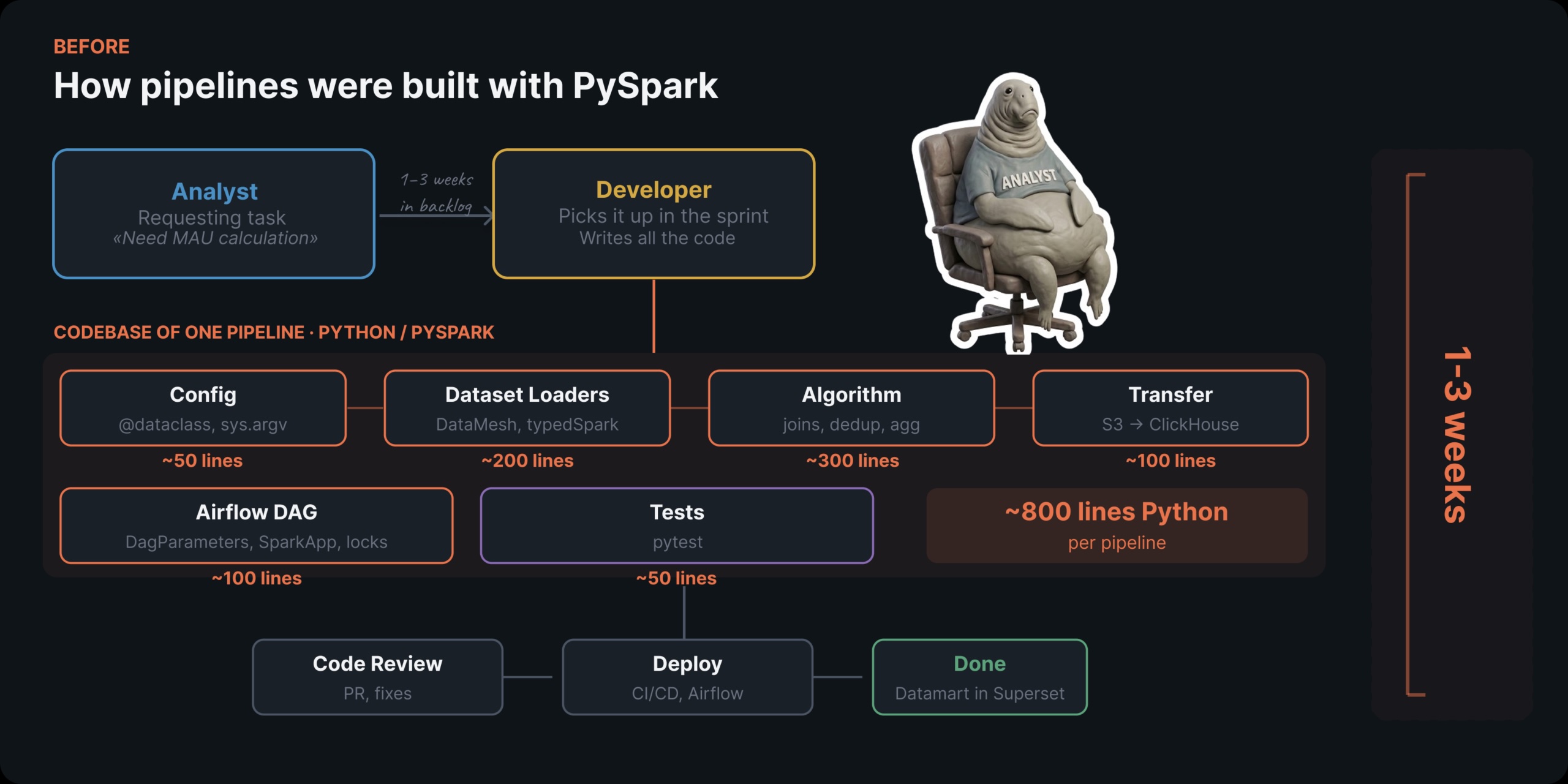
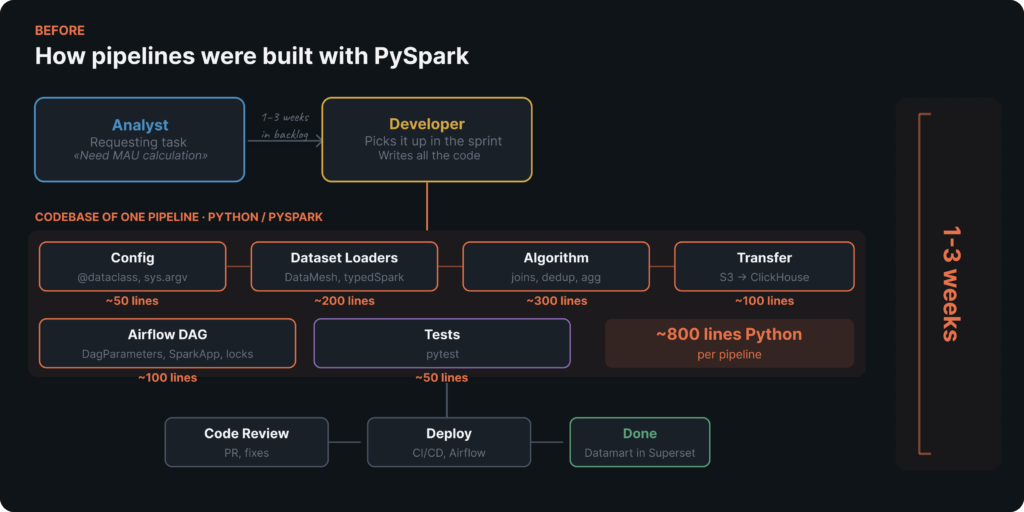 Quy trình cũ sử dụng PySpark
Quy trình cũ sử dụng PySpark
Tại sao PySpark lại làm chậm tốc độ của chúng tôi
Hãy tôi minh họa những khó khăn thông qua một ví dụ kinh điển — tính toán MAU (Người dùng hoạt động hàng tháng).
Bề ngoài, việc này có vẻ giống như một công việc SQL đơn giản: COUNT(DISTINCT customerId) trên một vài bảng trong một khoảng thời gian. Nhưng vì gánh nặng cơ sở hạ tầng — PySpark, thiết lập Airflow DAG, phân bổ tài nguyên Spark, kiểm thử — chúng tôi phải giao việc này cho các nhà phát triển. Kết quả? Cả một tuần chỉ để vận hành một bộ đếm MAU.
Mỗi chỉ số mới mất từ một đến ba tuần để hoàn thành. Và mỗi lần, quy trình đều giống hệt nhau:
- Một nhà phân tích xác định các yêu cầu kinh doanh, tìm một lập trình viên có sẵn và giao bối cảnh.
- Lập trình viên làm rõ chi tiết, viết mã PySpark, trải qua quá trình review mã, cấu hình DAG và triển khai.
Những gì chúng tôi thực sự mong muốn là để các nhà phân tích và quản lý sản phẩm — những người hiểu rõ nhất về logic kinh doanh và thành thạo SQL, YAML — tự xử lý việc này. Không cần Python. Không cần PySpark.
Chúng tôi đã thay thế PySpark bằng cái gì: Chỉ cần YAML và SQL
Để áp dụng cách tiếp cận khai báo (declarative approach), chúng tôi chia lớp dữ liệu thành ba phần và chọn công cụ phù hợp nhất cho từng phần:
- dlt (data load tool): Nạp dữ liệu từ các API và cơ sở dữ liệu bên ngoài vào bộ nhớ đối tượng (object storage). Được cấu hình hoàn toàn thông qua một tệp YAML. Không cần viết mã.
- dbt (data build tool) trên Trino: Chuyển đổi dữ liệu sử dụng SQL thuần túy. Nó liên kết các mô hình thông qua
ref(), tự động xây dựng đồ thị phụ thuộc và xử lý các bản cập nhật tăng dần (incremental updates). - Airflow + Cosmos: Điều phối các pipeline. Airflow DAG được tạo tự động từ
dag.yamlvà dự án dbt.
Chúng tôi đã sử dụng Trino làm công cụ truy vấn cho các truy vấn đặc biệt (ad-hoc queries) và kết nối nó với Superset cho BI. Nó đã chứng minh được hiệu quả: đối với các truy vấn có logic chuẩn, Trino xử lý các tập dữ liệu khổng lồ nhanh hơn và tốn ít tài nguyên hơn Spark. Hơn nữa, Trino hỗ trợ truy cập liên kết (federated access) đến nhiều kho dữ liệu từ một truy vấn SQL duy nhất. Đối với 90% các pipeline của chúng tôi, Trino là sự lựa chọn hoàn hảo.
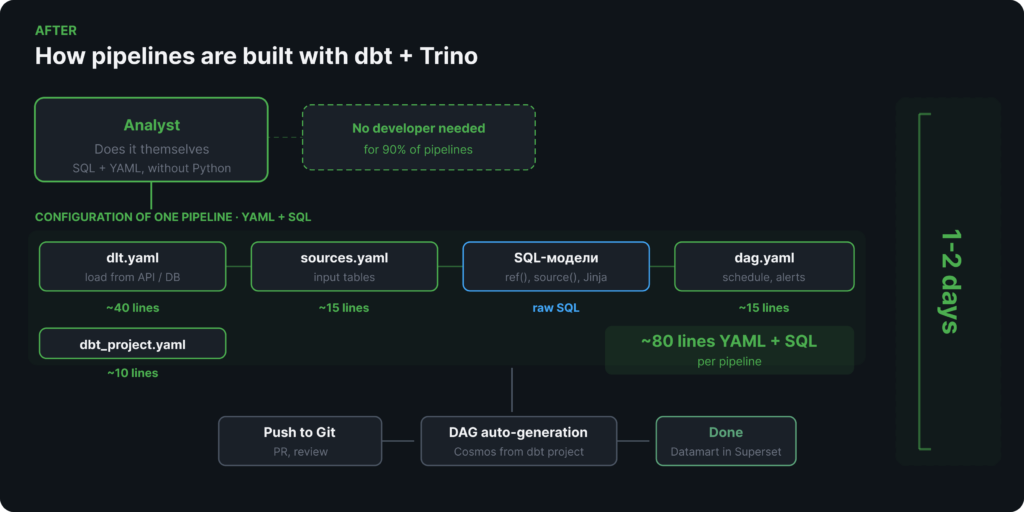 Quy trình mới sử dụng dbt và Trino
Quy trình mới sử dụng dbt và Trino
Cách chúng tôi nạp dữ liệu: dlt.yaml
Tệp YAML đầu tiên mô tả nơi và cách nạp dữ liệu để xử lý tiếp theo. Dưới đây là một ví dụ thực tế — nạp dữ liệu thanh toán từ một API nội bộ:
product: sg-team
feature: billing
schema: billing_tarification
dag:
dag_id: dlt_billing_tarification
schedule: "0 4 * * *"
description: "Daily refresh of tarification data"
tags:
- billing
alerts:
enabled: true
severity: warning
source:
type: rest_api
client:
base_url: "https://internal-api.example.com"
auth:
type: bearer
token: dlt-billing.token
resources:
- name: tarification_data
endpoint:
path: /tarificationData
method: POST
json:
firstPeriod: "{{ previous_month_date }}"
lastPeriod: "{{ previous_month_date }}"
pricingPlanLine: CurrentPlan
write_disposition: replace
Cấu hình này xác định bốn tài nguyên từ một API duy nhất. Đối với mỗi tài nguyên, chúng tôi chỉ định điểm cuối, tham số yêu cầu và chiến lược ghi — trong trường hợp này là replace có nghĩa là "ghi đè mỗi lần". Bạn cũng có thể thêm các bước xử lý, định nghĩa kiểu cột và cấu hình cảnh báo.
Toàn bộ cấu hình chỉ dài 40 dòng YAML. Nếu không có dlt, mỗi bộ kết nối sẽ là một tập lệnh Python xử lý các yêu cầu, phân trang, thử lại, tuần tự hóa sang định dạng Delta Table và tải lên bộ nhớ.
Cách chúng tôi chuyển đổi dữ liệu với SQL: dbt_project.yaml và sources.yaml
Bước tiếp theo là cấu hình mô hình dbt. Với Trino, điều đó có nghĩa là các truy vấn SQL.
Dưới đây là ví dụ về cách chúng tôi thiết lập tính toán MAU. Đây là cách chuẩn bị sự kiện từ một nguồn duy nhất trông như thế nào:
-- int_mau_events_visits.sql (đơn giản hóa)
{{ config(materialized='table') }}
WITH period AS (
-- Cửa sổ cuộn: 5 tháng trước đến hiện tại
SELECT
YEAR(CURRENT_DATE - INTERVAL '5' MONTH) AS start_year,
MONTH(CURRENT_DATE - INTERVAL '5' MONTH) AS start_month,
YEAR(CURRENT_DATE) AS end_year,
MONTH(CURRENT_DATE) AS end_month
),
events AS (
-- Lấy các sự kiện truy cập trong khoảng thời gian
SELECT src._tenant, src.unmergedCustomerId,
'visits' AS src_type, src.endpoint
FROM {{ source('final', 'customerstracking_visits') }} src
CROSS JOIN period p
WHERE src.unmergedCustomerId IS NOT NULL
AND /* ...bộ lọc thời gian theo giới hạn năm/tháng... */
)
-- ...các bước xử lý tiếp theo
SELECT ewc._tenant, ewc.customerId, ewc.src_type, ewc.endpoint
FROM events_with_customer ewc
WHERE EXISTS (
SELECT 1 FROM {{ ref('int_actual_customers') }} ac
WHERE ewc._tenant = ac._tenant
AND ewc.customerId = ac.customerId
)
Tất cả 10 nguồn sự kiện đều tuân theo cùng một mô hình. Sau đó, các mô hình được hợp nhất vào một luồng duy nhất và cuối cùng là data mart nơi mọi thứ được tổng hợp.
Đối với cấu hình data mart, chúng tôi sử dụng incremental_strategy='merge'. dbt tự động tạo truy vấn hợp nhất, thay thế unique_key cho upsert. Không cần triển khai tải tăng dần thủ công.
Để liên kết các mô hình thành một dự án duy nhất, chúng tôi thiết lập dbt_project.yaml và sources.yaml mô tả các bảng đầu vào.
Kết quả là logic kinh doanh giống hệt như chúng tôi có trong PySpark, nhưng bằng SQL thuần túy: sources.yaml thay thế các schema PySpark, {{ ref() }} và {{ source() }} thay thế .get_table(), và thứ tự thực thi tự động thông qua đồ thị phụ thuộc thay thế việc tinh chỉnh tài nguyên Spark thủ công.
Cách chúng tôi cấu hình Airflow: dag.yaml
Tệp cấu hình thứ tư xác định khi nào và cách Airflow chạy pipeline:
product: sg-team
feature: billing
schema: mau
schedule: "15 21 * * *" # hàng ngày lúc 00:15 MSK
params:
- name: start_date
description: "Start date (YYYY-MM-DD). Leave empty for auto"
default: ""
- name: months_back
description: "Months to look back (default: 5)"
default: 5
alerts:
enabled: true
severity: warning
Sau đó, tập lệnh Python của chúng tôi phân tích dag.yaml và dbt_project.yaml cũng như sử dụng thư viện Cosmos để tạo một Airflow DAG hoàn chỉnh. Đây là mảnh mã Python duy nhất trong toàn bộ thiết lập. Nó được viết một lần và hoạt động cho mọi dự án dbt.
Cosmos đọc manifest.json từ dự án dbt, phân tích đồ thị phụ thuộc của mô hình và tạo một tác vụ Airflow riêng biệt cho mỗi mô hình. Các phụ thuộc tác vụ được xây dựng tự động dựa trên các lệnh gọi ref() trong SQL.
Các nhà phân tích xây dựng Pipeline như thế nào mà không cần Lập trình viên
Bây giờ, khi một nhà phân tích cần một pipeline định kỳ mới, họ có thể tổng hợp nó trong vài bước:
- Tạo một thư mục trong repo:
dbt-projects/my_new_pipeline/. - Nếu cần nạp dữ liệu bên ngoài, hãy viết cấu hình YAML cho dlt.
- Viết các mô hình SQL trong thư mục
models/và mô tả các nguồn trongsources.yaml. - Tạo
dbt_project.yamlvàdag.yaml. - Đẩy lên Git, trải qua quá trình review và hợp nhất (merge).
CI/CD xây dựng dự án dbt và chuyển các tạo tác (artifacts) đến S3. Airflow đọc các tệp DAG từ đó, Cosmos phân tích dự án dbt và tạo đồ thị tác vụ. Theo lịch trình, dbt chạy các mô hình trên Trino theo đúng thứ tự. Kết quả cuối cùng là một data mart được cập nhật trong kho dữ liệu, có thể truy cập thông qua Superset.
 Bảng so sánh hiệu quả
Bảng so sánh hiệu quả
Những gì đã thay đổi sau khi di chuyển
Để các nhà phân tích có thể tự xây dựng pipeline, họ cần hiểu các khái niệm ref() và source(), sự khác biệt giữa table và incremental materialization, và những điều cơ bản về Git. Chúng tôi đã tổ chức một số hội thảo nội bộ và tổng hợp các hướng dẫn từng bước cho từng loại nhiệm vụ.
Tại sao Stack mới không thay thế hoàn toàn PySpark
Khoảng 10% các pipeline của chúng tôi, PySpark vẫn là lựa chọn duy nhất — khi một phép biến đổi đơn giản không phù hợp với SQL. dbt hỗ trợ các macro Jinja, nhưng đó không phải là thay thế cho Python đầy đủ. Và sẽ không trung thực nếu bỏ qua các hạn chế của các công cụ mới.
- dlt + Delta: hỗ trợ upsert thử nghiệm. Chúng tôi sử dụng định dạng Delta trong lớp lưu trữ. Bộ kết nối Delta của dlt được đánh dấu là thử nghiệm, vì vậy chiến lược hợp nhất không hoạt động ngay lập tức. Chúng tôi phải tìm cách giải quyết — trong một số trường hợp, chúng tôi sử dụng
replacethay vìmerge(hy sinh tính tăng dần), và trong các trường hợp khác, chúng tôi viết cácprocessing_stepstùy chỉnh. - Khả năng chịu lỗi hạn chế của Trino: Trino có cơ chế chịu lỗi, nhưng nó hoạt động bằng cách ghi kết quả trung gian vào S3. Với khối lượng dữ liệu cấp terabyte của chúng tôi, điều này là không thực tế — số lượng thao tác S3 khổng lồ làm cho nó trở nên quá đắt đỏ. Nếu không bật khả năng chịu lỗi, khi một worker Trino bị sập, toàn bộ truy vấn sẽ thất bại. Ngược lại, Spark chỉ khởi động lại tác vụ thất bại. Chúng tôi giải quyết vấn đề này bằng cách thử lại ở cấp DAG và phân tách các mô hình nặng thành chuỗi các mô hình trung gian.
- UDF và logic tùy chỉnh: Trong Spark, bạn có thể viết logic tùy chỉnh bằng Python ngay trong pipeline — rất tiện lợi. Với kiến trúc mới, việc này khó hơn nhiều. dbt trên Trino không giúp ích nhiều: Jinja chỉ tạo SQL và các mô hình Python của dbt chỉ hoạt động với Snowflake, Databricks và BigQuery. Bạn có thể viết UDF trong Trino, nhưng chỉ bằng Java — với tất cả chi phí đi kèm: một repo riêng, một pipeline xây dựng, triển khai các tệp JAR trên tất cả các worker. Vì vậy, khi một phép biến đổi không phù hợp với SQL, bạn sẽ kết thúc với một con quái vật SQL không thể bảo trì hoặc một tập lệnh độc lập phá vỡ dòng chảy dữ liệu.
Tiếp theo là gì: Kiểm thử, Mẫu mô hình và Đào tạo
- Kiểm thử tốt hơn: Chúng tôi có kiểm thử pipeline vững chắc trong PySpark, nhưng kiến trúc mới vẫn đang bắt kịp. Các phiên bản dbt gần đây đã giới thiệu kiểm thử đơn vị — giờ đây bạn có thể xác minh logic mô hình SQL đối với dữ liệu giả mà không cần khởi chạy toàn bộ pipeline. Chúng tôi muốn thêm các bài kiểm tra dbt cả ở cấp mô hình và như một lớp giám sát riêng biệt.
- Mẫu có thể tái sử dụng cho các mô hình phổ biến: Nhiều mô hình dbt của chúng tôi trông giống nhau. Một cấu hình duy nhất có thể mô tả hàng chục mô hình với cùng một mẫu — chỉ khác bảng nguồn và bộ lọc. Chúng tôi dự định trích xuất logic chia sẻ thành các macro dbt.
- Mở rộng cơ sở người dùng nền tảng: Chúng tôi muốn nhiều kỹ sư và nhà phân tích hơn làm việc độc lập với dữ liệu. Chúng tôi đang lên kế hoạch các buổi đào tạo nội bộ thường xuyên, tài liệu và hướng dẫn onboarding để người dùng mới có thể bắt kịp nhanh chóng và bắt đầu xây dựng các mô hình của riêng họ.
Nếu đội ngũ của bạn cũng đang mắc kẹt trong vòng lặp "nhà phân tích chờ đợi lập trình viên", tôi rất muốn nghe cách bạn đang giải quyết vấn đề đó. Hãy kết nối với tôi trên LinkedIn để chúng ta có thể trao đổi.

