
GPT-5.5: Khả năng tấn công mạng sánh ngang Mythos nhưng mở cửa cho tất cả mọi người
Mô hình GPT-5.5 mới của OpenAI đang tạo ra cú sốc lớn trong cộng đồng an ninh mạng nhờ khả năng phát hiện lỗ hổng vượt trội, sánh ngang với Anthropic Mythos nhưng lại được phát hành miễn phí. Các bài kiểm nghiệm thực tế cho thấy tỷ lệ bỏ sót lỗ hổng đã giảm xuống mức kỷ lục 10%, đồng thời cải thiện đáng kể hiệu suất trong cả kiểm thử hộp đen và hộp trắng.

GPT-5.5: Khả năng tấn công mạng sánh ngang Mythos nhưng mở cửa cho tất cả mọi người
Trong vài tuần qua, chúng tôi đã nằm trong nhóm được chọn có quyền truy cập sớm. Chúng tôi đã tiến hành kiểm thử mô hình này trên các hệ thống benchmark và quy trình làm việc của mình, và giờ đây xin chia sẻ những quan sát thực tế mà chúng tôi thu được. Dưới đây là đánh giá của chúng tôi về GPT-5.5 và cách nó hoạt động trong các khả năng an ninh mạng tấn công (offensive security).
Anthropic có Mythos, nhưng chỉ một số ít người được nhìn thấy nó. Giờ đây, OpenAI đã có một mô hình mà theo mọi đánh giá có vẻ khá tương đương — nhưng họ lại phát hành nó tự do cho tất cả mọi người. Giống như Mythos, GPT 5.5 mang lại một bước tiến nhảy vọt trong việc phát hiện lỗ hổng.
 XBOW Benchmark
XBOW Benchmark
Các mô hình không tồn tại trong môi trường chân không, vì vậy tại XBOW, chúng tôi không đánh giá chúng một cách cô lập. Chúng tôi chạy chúng bên trong các quy trình tác nhân (agent workflows) của mình, trên các nhiệm vụ kiểm thử xâm nhập (penetration testing) thực tế và đo lường cách chúng hoạt động. Điều này bao gồm mọi thứ từ việc phát hiện lỗ hổng, đăng nhập vào ứng dụng, cho đến tạo ra các báo cáo cuối cùng.
Chúng tôi cũng được thiết kế để không phụ thuộc vào một mô hình cụ thể. Các phần khác nhau của hệ thống sử dụng các mô hình khác nhau tùy thuộc vào công việc — đôi khi đó là mô hình nhỏ hơn, nhanh hơn để đảm bảo độ phản hồi, và đôi khi là sử dụng mô hình mạnh mẽ nhất có sẵn để tối đa hóa độ chính xác.
Cách chúng tôi đo lường hiệu suất
Để hiểu tại sao điều này lại quan trọng, đáng nói sơ qua về cách chúng tôi đánh giá các mô hình.
Như đã đề cập trong một bài viết trước, chúng tôi đã xây dựng một hệ thống benchmark nội bộ dựa trên các lỗ hổng thực tế. Chúng tôi lấy các ứng dụng mã nguồn mở mà trước đây đã từng phát hiện ra lỗ hổng, đóng băng chúng ở phiên bản có lỗ hổng và chạy các tác nhân của mình chống lại chúng. Mục tiêu không phải là đo lường các hoàn thành đơn lẻ, mà là đánh giá toàn bộ quy trình xác định và khai thác các vấn đề đó.
Điều này mang lại cho chúng tôi một cách nhất quán và thực tế để so sánh các mô hình theo thời gian. Chỉ số chính mà chúng tôi theo dõi ở đây là tỷ lệ bỏ sót (miss rate): số lượng lỗ hổng đã biết mà mô hình không tìm thấy.
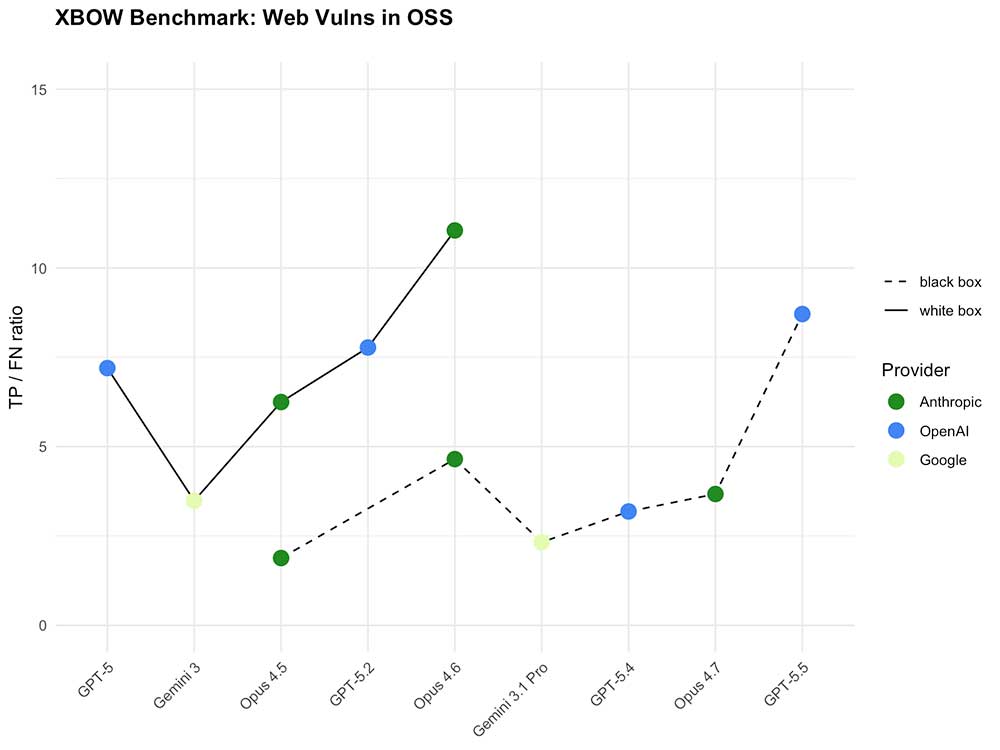
Một bước tiến lớn cho Kiểm thử Hộp đen, và Benchmark Hộp trắng của chúng tôi đã "chết"
Trên benchmark này, GPT-5.5 mang lại hiệu suất tốt nhất mà chúng tôi từng thấy cho đến nay.
Để bạn dễ hình dung: GPT-5 đã bỏ sót 40% lỗ hổng. Opus 4.6 giảm con số này xuống 18%. GPT-5.5 lại giảm tiếp xuống chỉ còn 10%.
Đó không phải là một sự cải thiện nhỏ. Mỗi lỗ hổng bị bỏ sót là một rủi ro thực tế trong cuộc sống. Khi bạn đang chạy kiểm thử bảo mật tự động, việc thu hẹp khoảng cách này là rất quan trọng.
Câu chuyện ấn tượng hơn nữa xuất hiện khi bạn phân tách hiệu suất giữa hộp đen (black box) và hộp trắng (white box). Cả hai đều quan trọng — những kẻ tấn công thường nhìn thấy hệ thống từ góc độ hộp đen, mặc dù đối với một đợt kiểm thử xâm nhập, khách hàng thường sẽ cung cấp mã nguồn của họ để cho phép kiểm thử hộp trắng hoàn chỉnh hơn.
Ngay cả khi không có mã nguồn, GPT-5.5 đã vượt trội hơn GPT-5 đang chạy với mã nguồn. Điều này đảo lược thứ bậc mong đợi: Kiểm thử hộp đen trước đây giống như việc đấm bốc với đôi găng tay dày. Giờ đây nó cảm giác như đang làm việc bằng tay trần.
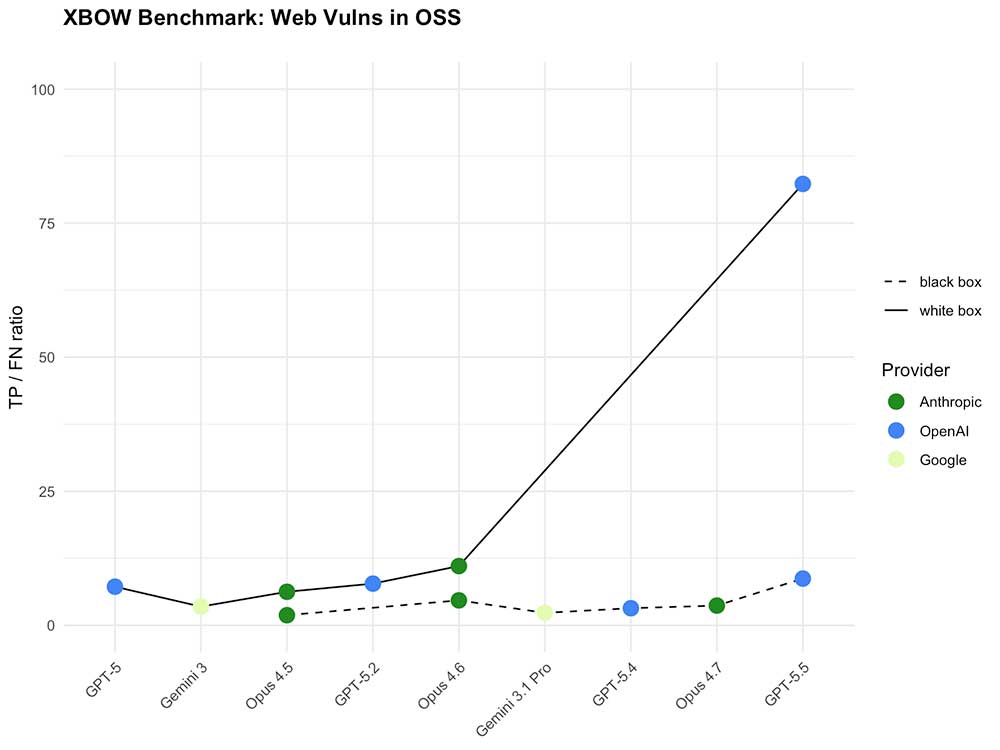
Nhưng khi bạn thêm mã nguồn vào.
Trong môi trường hộp trắng, GPT-5.5 không chỉ cải thiện — nó bỏ xa đối thủ. Bước nhảy vọt về hiệu suất lớn đến mức nó làm cho biểu đồ bị nén lại. Với mã nguồn, nó thực sự đã "giết chết" benchmark của chúng tôi.
Tóm lại: GPT-5.5 nâng cao mức sàn trong kiểm thử hộp đen và phá vỡ trần nhà trong kiểm thử hộp trắng.
 Web Vulnerabilities
Web Vulnerabilities
Con đường dẫn đến thành công
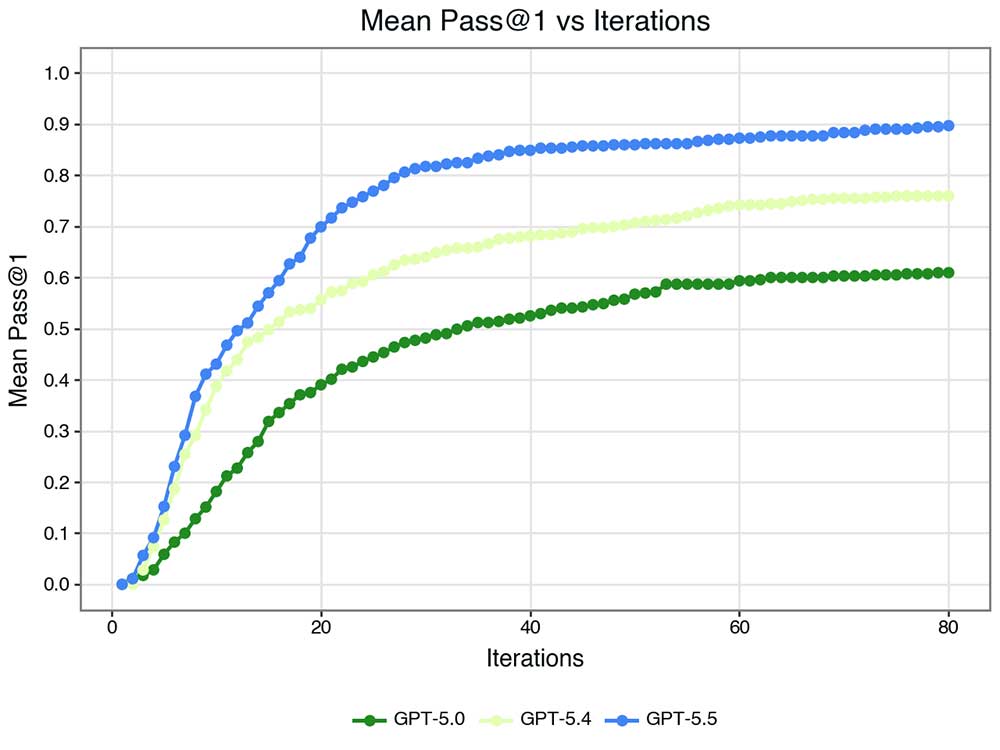
Việc tìm thấy hay không tìm thấy một lỗ hổng không phải là vấn đề nhị phân — một số được tìm thấy nhanh, một số chậm. Khi so sánh các mô hình dựa trên số lượng hành động chúng thực hiện trước khi tìm thấy lỗ hổng, một mô hình thú vị trong sự tiến triển giữa các phiên bản GPT hiện ra:
Đầu tiên, GPT-5.4 học cách đi nhanh hơn. Sau đó, GPT-5.5 học cách đi xa hơn.
Ngay cả về mặt thị giác, sự khác biệt giữa 5.4 và 5.5 rõ ràng là bội số của bước tiến phụ điển hình.
Tương tác trong thế giới thực
Chúng tôi cũng kiểm tra các mô hình trên những gì chúng tôi gọi là benchmark "sử dụng máy tính" — các nhiệm vụ phản ánh cách các tác nhân của chúng tôi tương tác với các ứng dụng thực tế. Điều này bao gồm đăng nhập, điều hướng giao diện và xử lý các loại ma sát mà bạn gặp phải trong môi trường sản xuất.
Trên benchmark về thị lực của chúng tôi, GPT-5.5 đạt được 97,5%, đưa nó vào biên độ của kết quả tốt nhất mà chúng tôi từng thấy (Anthropic's Opus 4.7).
Nhưng một lần nữa, những cải tiến thú vị hơn xuất hiện trong các quy trình làm việc thực tế. Khi đăng nhập vào các hệ thống mục tiêu, GPT-5.5 nhanh hơn đáng kể so với bất kỳ mô hình nào chúng tôi từng kiểm tra. Nó đăng nhập thành công chỉ với khoảng một nửa số lần lặp lại so với mô hình tốt nhất tiếp theo.
Quan trọng không kém, nó cũng thất bại nhanh hơn. Nếu thông tin đăng nhập không chính xác hoặc hệ thống chặn quyền truy cập, nó xác định điều đó và chuyển sang việc khác trong khoảng một nửa thời gian. Điều đó có vẻ như là một chi tiết nhỏ, nhưng nó có tác động trực tiếp đến trải nghiệm người dùng. Thành công nhanh hơn giúp tăng tốc các đợt đánh giá. Thất bại nhanh hơn có nghĩa là chúng tôi có thể thông báo cho khách hàng về các vấn đề — như thông tin đăng nhập bị hỏng hoặc phát hiện bot — sớm hơn nhiều.
Và nó gắn liền với một chủ đề chung hơn:
Kiên trì hay Chuyển hướng (Persist or Pivot)
Một trong những cải tiến ít được đề cập hơn là cách GPT-5.5 cư xử khi mọi thứ không hoạt động.
Trong thực tế, các tác nhân cần liên tục quyết định xem nên kiên trì hay chuyển hướng. Đẩy quá mạnh vào một con đường thất bại và bạn lãng phí thời gian. Từ bỏ quá sớm và bạn bỏ lỡ cơ hội. Cân bằng đúng điều này rất khó, và đó là điều mà ngay cả các phòng thí nghiệm hàng đầu về biên giới (frontier labs) cũng đang gặp khó khăn khi đào tạo các LLM. Sau tất cả, RLHF và các phương pháp tương tự tối ưu hóa chúng để làm người dùng tiêu dùng hài lòng, và không ai thích loại thuốc đắng: "điều tốt nhất cần làm ngay bây giờ là từ bỏ".
Tuy nhiên, khi chúng tôi tiếp tục giao cho các mô hình ngày càng nhiều trách nhiệm hơn, việc từ bỏ thay vì đập đầu ngu ngốc vào tường trở nên quan trọng hơn bao giờ hết. Trong tập hợp các trường hợp ví dụ của XBOW cho những tình huống mà một tác nhân nên từ bỏ, GPT-5.5 đôi khi vẫn kiên trì lâu hơn lý tưởng — nhưng chỉ bằng một nửa so với các phiên bản GPT trước đó (hoặc thực tế là Opus).
Điều đó làm cho GPT-5.5 không chỉ có khả năng hơn, mà còn thực tế hơn.
 Mean Pass
Mean Pass
Điều này có nghĩa là gì cho khách hàng
Tất cả những điều này chuyển hóa thành những cải thiện hữu hình.
Các cuộc điều tra hoàn thành nhanh hơn. Khả năng bao phủ lỗ hổng được cải thiện. Các vòng phản hồi (feedback loops) được thắt chặt, đặc biệt là khi có sự cố xảy ra sớm trong bài kiểm tra. Trải nghiệm tổng thể trở nên phản hồi nhanh hơn và đáng tin cậy hơn.
Bởi vì chúng tôi vận hành một hệ thống đa mô hình, điều này không có nghĩa là một mô hình duy nhất sẽ thay thế mọi thứ khác. Chúng tôi sẽ tiếp tục sử dụng các mô hình khác nhau trên các phần khác nhau của ngăn xếp tùy thuộc vào nhiệm vụ. Nhưng đối với các quy trình kiểm thử xâm nhập cốt lõi, GPT-5.5 rõ ràng đang thiết lập một tiêu chuẩn mới.
GPT-5.5: Dẫn đầu trong các lĩnh vực quan trọng nhất
Chúng tôi sử dụng mô hình tốt nhất cho từng công việc, và ngay lúc này GPT-5.5 đang dẫn đầu trong một số lĩnh vực. Một số trong số đó là cụ thể cho pentest, nhưng hiệu suất mạnh mẽ của nó không bị giới hạn ở những điều đó. Điều đó vẽ nên bức tranh về một mô hình nói chung mạnh mẽ hơn — một mức tăng lớn hơn so với việc nâng cấp phiên bản phụ điển hình.
Chúng tôi sẽ tiếp tục đánh giá nó khi nó được đưa vào sản xuất, nhưng kết quả ban đầu cho thấy nó sẽ trở thành một phần quan trọng trong ngăn xếp công nghệ của chúng tôi.
Bài viết liên quan

Công nghệ
Anthropic và OpenAI mang cuộc chiến công nghệ sang chính trường Mỹ
20 tháng 5, 2026

Phần cứng
Nvidia chính thức đưa siêu vi xử lý Grace Blackwell lên PC với dòng notebook RTX Spark
01 tháng 6, 2026
AI & ML
MFA chỉ là bước khởi đầu: Tại sao xác thực thành công vẫn không ngăn chặn được tin tặc?
21 tháng 5, 2026