
Tham số hay Tính toán: Cái nào quan trọng hơn trong Deep Learning?
Nghiên cứu mới từ Facebook AI Research thách thức quan điểm truyền thống cho rằng mô hình lớn hơn luôn tốt hơn bằng cách chứng minh sự cần thiết phải tách biệt số lượng tham số và lượng tính toán. Bài viết giới thiệu hai kiến trúc mới là Hash Layers và Staircase Attention, cho phép tăng hiệu suất mô hình thông qua việc tối ưu hóa linh hoạt tài nguyên tính toán hoặc bộ nhớ.
Trong thế giới học sâu (deep learning), thước đo phổ biến nhất để đánh giá sức mạnh của một mô hình thường là kích thước của nó, cụ thể là số lượng tham số (parameters). Tuy nhiên, lượng tính toán cần thiết để chạy mô hình cũng là một chỉ số quan trọng, nhưng thường bị bỏ qua vì nó thường gắn liền với kích thước mô hình. Các nhà nghiên cứu từ Facebook AI Research (ParlAI) đã công bố hai phương pháp mới giúp tách biệt hai khái niệm này, mở ra hướng đi mới trong việc thiết kế các mô hình AI hiệu quả hơn.
Hash Layers: Tăng tham số mà không tăng tính toán
Trong những năm gần đây, xu hướng xây dựng các mô hình Transformer khổng lồ với hàng tỷ tham số đã trở nên phổ biến để đạt được kết quả ấn tượng trên các nhiệm vụ ngôn ngữ. Tuy nhiên, các mô hình lớn này đòi hỏi lượng tính toán khổng lồ, khiến việc triển khai thực tế trở nên khó khăn.
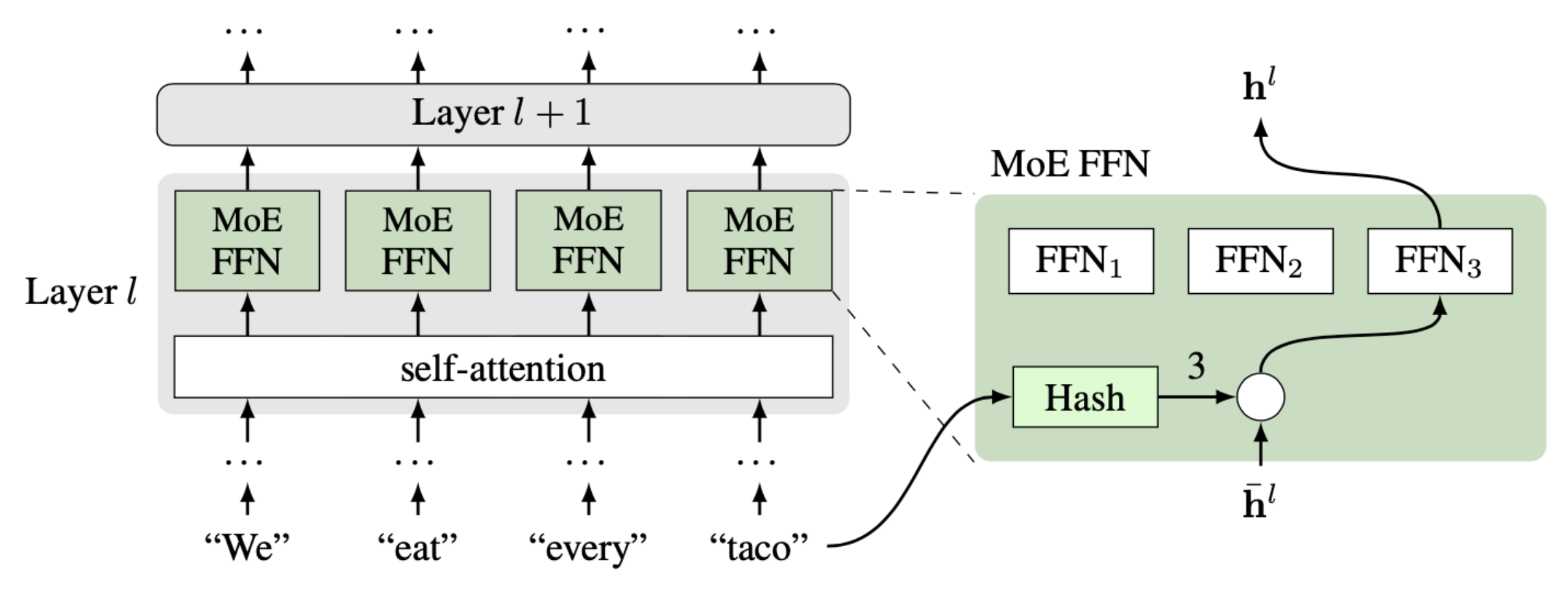
Hash Layers
Một giải pháp là sử dụng phương pháp "hỗn hợp chuyên gia thưa" (Sparse Mixture-of-Experts - MoE), trong đó mỗi chuyên gia có các tham số riêng và chỉ được kích hoạt cho một phần dữ liệu đầu vào. Trong nghiên cứu này, các tác giả đề xuất cơ chế định tuyến dựa trên hashing (băm) cho các token đầu vào.
Khác với các phương pháp học phức tạp trước đây, hashing MoE đơn giản hơn nhiều: mỗi từ trong từ điển được gán cho một chuyên gia cố định một cách ngẫu nhiên hoặc cân bằng. Mặc dù đơn giản, phương pháp này hoạt động hiệu quả trên nhiều nhiệm vụ khó khăn về ngôn ngữ và hội thoại. Thử nghiệm trên tập dữ liệu Reddit cho thấy cơ chế hashing này vượt trội so với các mô hình cơ sở (baseline), cho phép huấn luyện các mô hình lên tới 4,5 tỷ tham số nhưng chỉ sử dụng một phần nhỏ tham số cho mỗi đầu vào cụ thể.
Staircase Attention: Tăng tính toán mà không thêm tham số
Trong khi việc thêm tham số là một hướng đi phổ biến, việc tăng lượng tính toán lại ít được khám phá hơn. Các mô hình Transformer tiêu chuẩn thường "khóa" chặt tính toán và tham số vào kiến trúc. Để giải quyết vấn đề này, nghiên cứu giới thiệu một họ kiến trúc mới tách biệt hai yếu tố này.
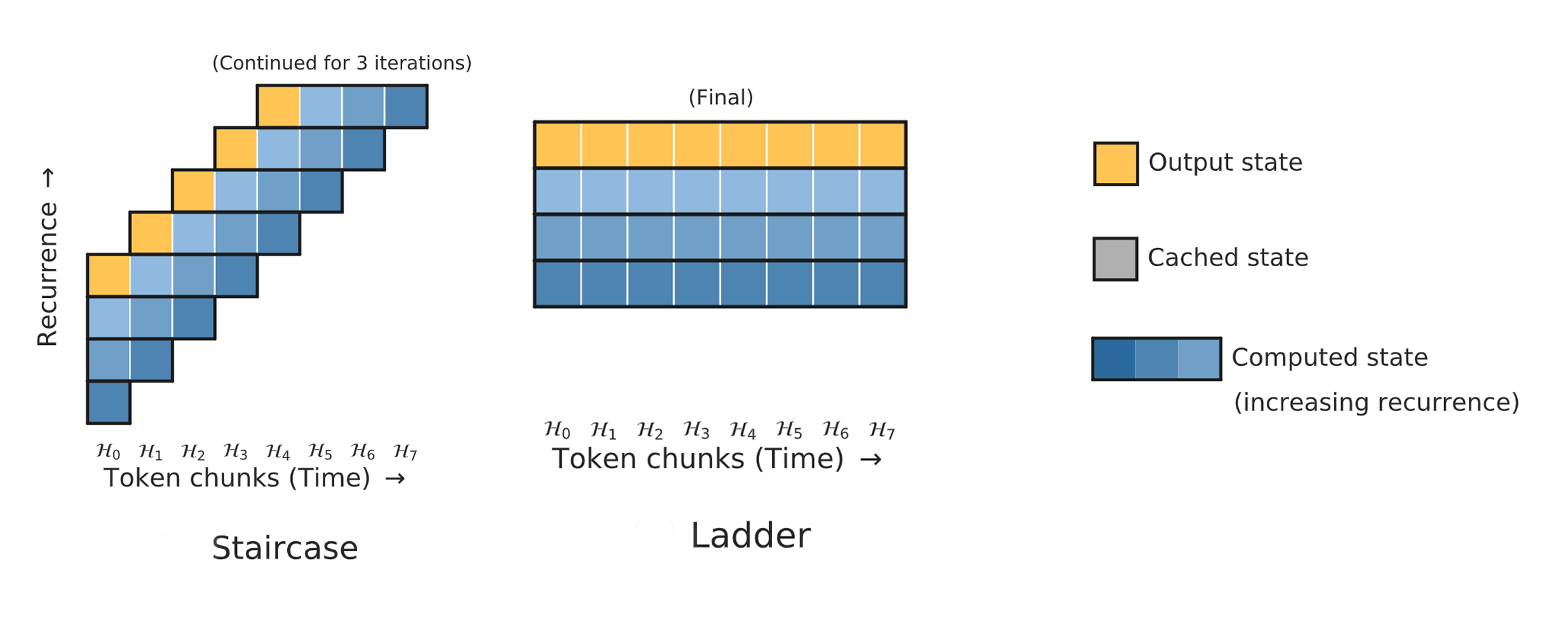 Staircase Attention
Staircase Attention
Mô hình "Ladder" đơn giản là xếp chồng cùng một Transformer nhiều lần. Điều này có nghĩa là một tham số sẽ tham gia vào tính toán nhiều lần, tăng lượng tính toán trong khi giữ nguyên kích thước mô hình. Sự thay đổi đơn giản này mang lại cải thiện hiệu suất đáng kể.
Mô hình "Staircase" cũng xếp chồng các Transformer nhưng dịch chuyển mỗi khối nhiều bước thời gian về phía trước. Điều này tạo ra tính chất đệ quy (recurrent) theo thời gian, rất quan trọng để duy trì trạng thái nội bộ cho việc theo dõi các thay đổi thông tin. Trên các nhiệm vụ yêu cầu duy trì trạng thái, Staircase hoạt động vượt trội so với các mô hình feedforward thông thường.
Kết hợp cả hai phương pháp
Một câu hỏi tự nhiên là liệu chúng ta có thể kết hợp Hash Layers và Staircase Attention hay không? Câu trả lời là có. Các cải thiện từ hai phương pháp này bổ trợ cho nhau, mang lại lợi ích đáng kể khi kết hợp so với việc sử dụng riêng lẻ.
Tổng kết lại, nghiên cứu này cho thấy chúng ta cần xem xét riêng biệt số lượng tham số và lượng tính toán khi thiết kế mô hình máy học. Bằng cách sử dụng Hash Layers và Staircase Attention, các nhà nghiên cứu có thể kiểm soát tinh chỉnh hơn về tài nguyên, mở đường cho việc tạo ra các mô hình mạnh mẽ và hiệu quả hơn trong tương lai.
Bài viết liên quan

Công nghệ
Anthropic và OpenAI mang cuộc chiến công nghệ sang chính trường Mỹ
20 tháng 5, 2026

Công nghệ
Threads cán mốc 500 triệu người dùng, ra mắt tính năng cá nhân hóa thuật toán mới
16 tháng 6, 2026

Công nghệ
Tấn công mạng làm tê liệt nhà máy đường lớn tại Australia, nông dân không thể thu hoạch
17 tháng 6, 2026