
Tối ưu hóa WebAssembly: Gắn kết file tar như hệ thống tệp mà không cần giải nén
Bài viết giới thiệu kỹ thuật mới cho phép gắn kết (mount) các file lưu trữ tar trực tiếp vào hệ thống tệp ảo của WebAssembly mà không cần giải nén toàn bộ. Phương pháp này sử dụng một file index JSON để định vị dữ liệu, giúp tiết kiệm bộ nhớ và tăng tốc độ tải cho các ứng dụng web như WebR.
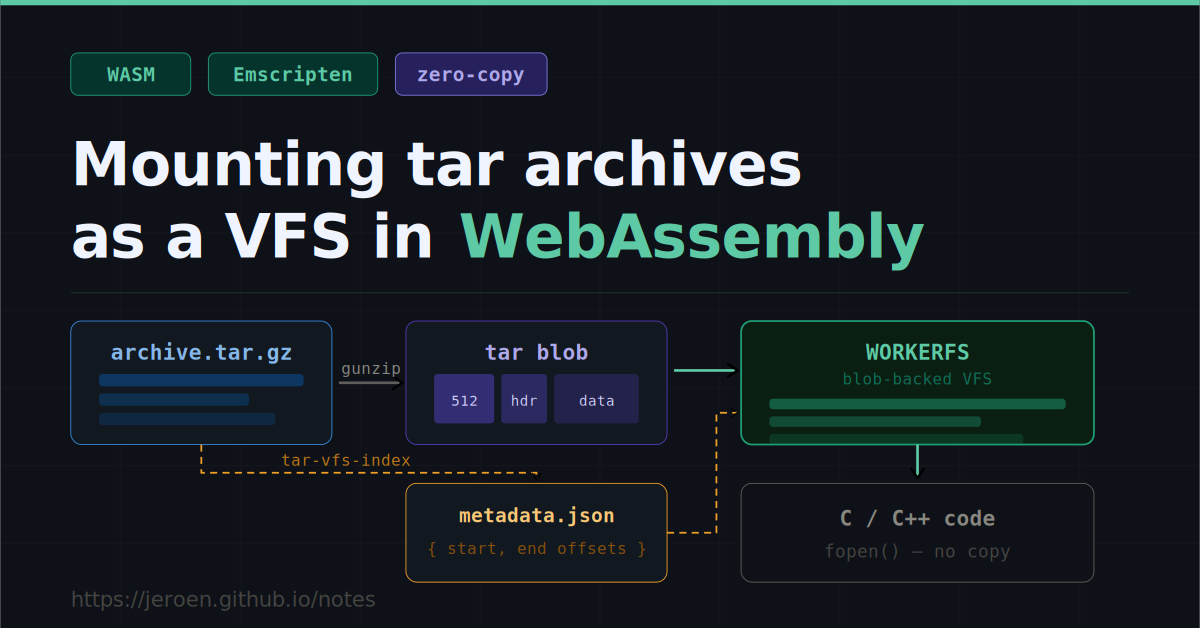
Trong môi trường phát triển web hiện đại, WebAssembly (Wasm) đang ngày càng đóng vai trò quan trọng trong việc mang các ứng dụng nặng sang trình duyệt. Tuy nhiên, việc xử lý dữ liệu lớn, đặc biệt là các file nén tar truyền thống, vẫn là một thách thức về hiệu suất và bộ nhớ. Một kỹ thuật mới đang được chú ý cho phép gắn kết (mount) các file lưu trữ tar trực tiếp như một hệ thống tệp, loại bỏ nhu cầu giải nén tốn kém.
 Minh họa hệ thống tệp ảo
Minh họa hệ thống tệp ảo
Thách thức với các file tarball truyền thống
Một lượng lớn dữ liệu trên Internet được lưu trữ và phân phối dưới dạng tarball, thường là các file nén .tar.gz. Để truy cập dữ liệu này trong môi trường WebAssembly, quy trình truyền thống thường bao gồm ba bước tốn kém: tải xuống toàn bộ file .tar.gz, giải nén nó, sau đó duyệt qua dữ liệu để sao chép các file cần thiết vào bộ nhớ.
Quá trình này không chỉ tốn thời gian mà còn tiêu tốn nhiều bộ nhớ (RAM), đặc biệt là trong các môi trường bị hạn chế tài nguyên như trình duyệt web trên thiết bị di động. Việc sao chép dữ liệu liên tục giữa các lớp bộ nhớ tạo ra gánh nặng lớn cho hiệu suất ứng dụng.
Giải pháp tối ưu: Sử dụng chỉ mục metadata
Thay vì giải nén toàn bộ, một giải pháp tối ưu đã được áp dụng cho WebR (bản port của ngôn ngữ R lên WebAssembly). Ý tưởng cốt lõi là tạo ra một file index nhỏ chứa metadata, liệt kê kích thước và vị trí (offset) của từng file bên trong tar. Nhờ đó, hệ thống có thể mount trực tiếp blob dữ liệu của tar thông qua WORKERFS của Emscripten mà không cần bất kỳ thao tác sao chép nào.
Cách tiếp cận này đã mang lại cải thiện đáng kể về khả năng sử dụng. Hiện tại, tất cả các gói R (R packages) cho webR đều được phân phối theo cách này, giúp thời gian tải nhanh hơn nhiều trong khi vẫn được lưu trữ dưới dạng file .tar.gz tĩnh trên máy chủ.
Cơ chế hoạt động của Emscripten VFS và WORKERFS
Emscripten cung cấp một hệ thống tệp ảo POSIX (VFS) để các lệnh nhập/xuất tệp (I/O) từ mã C/C++ có thể hoạt động trong WebAssembly mà không cần sửa đổi. Đây là yếu tố then chốt cho WebR, vì R tương tác rất nhiều với các tệp trên đĩa, đặc biệt khi tải các gói phần mềm.
VFS hỗ trợ các backend có thể cắm thêm, trong đó WORKERFS được thiết kế để cung cấp quyền truy cập chỉ đọc (read-only) cho các đối tượng Blob từ Web Workers mà không cần sao chép dữ liệu của chúng vào bộ nhớ heap của Wasm. Các tệp xuất hiện trong VFS tại các đường dẫn được khai báo, nhưng việc đọc dữ liệu được thực hiện bằng cách cắt (slice) blob gốc theo yêu cầu. Về cơ bản, đây là cơ chế memory-mapping cho trình duyệt: nội dung tệp nằm ở lớp JavaScript và chỉ được truy cập khi mã C thực sự đọc chúng.
Tạo chỉ mục cho file tar
Cấu trúc của một file tar là một chuỗi các header 512 byte tuần tự, theo sau là dữ liệu của tệp và được đệm theo ranh giới khối. Nội dung tệp là liền mạch và có thể địa chỉ hóa theo byte, do đó bản thân lưu trữ tar có thể đóng vai trò là nguồn dữ liệu (blob); chúng ta chỉ cần biết vị trí bắt đầu và kết thúc của mỗi tệp.
Gói npm tar-vfs-index thực hiện chính xác nhiệm vụ này: nó đọc luồng tar hoặc tar.gz và xuất ra một chỉ mục JSON ở định dạng metadata tương thích với file_packager của Emscripten.
Ví dụ về cấu trúc JSON index:
{
"files": [
{ "filename": "mypackage/DESCRIPTION", "start": 512, "end": 548 },
{ "filename": "mypackage/R/code.R", "start": 1536, "end": 1563 }
],
"remote_package_size": 3072
}
Các giá trị start và end là độ lệch byte (byte offsets) trong dữ liệu tar đã giải nén, chính là dải dữ liệu mà WORKERFS sẽ sử dụng để cắt blob khi mã C mở một tệp.
Quy trình gắn kết (Mount) vào VFS
Để mount một file tar trong WORKERFS, chúng ta cần hai thứ: Blob tar đã giải nén và metadata JSON chứa các chỉ mục. Nếu file đầu vào được nén gzip (.tar.gz), bạn nên dẫn nó qua DecompressionStream gốc của trình duyệt trước:
const [metaRes, dataRes] = await Promise.all([
fetch('archive.tar.gz.json'),
fetch('archive.tar.gz'),
]);
const metadata = await metaRes.json();
const blob = await new Response(
dataRes.body.pipeThrough(new DecompressionStream('gzip'))
).blob();
FS.mkdir('/pkg');
FS.mount(WORKERFS, { packages: [{ metadata, blob }] }, '/pkg');
Sau khi mount, mọi thao tác mở tệp từ mã C trong Emscripten sẽ được phục vụ bằng cách cắt blob tại đúng dải phạm vi tương ứng. Không có tệp nào được giải nén ra riêng biệt; dữ liệu tar đã giải nén vẫn nằm trong bộ nhớ làm kho lưu trữ hỗ trợ.
Tích hợp index vào chính file tar
Mặc dù việc phục vụ metadata dưới dạng file .json riêng biệt hoạt động tốt với mọi file .tar.gz hiện có và giúp tách biệt mối quan tâm rõ ràng, nhưng có một phương án thay thế là sửa đổi file tar gốc và chèn metadata bên trong chính lưu trữ tar, dưới dạng một mục nhập bổ sung ở cuối.
Bạn có thể thực hiện việc này bằng lệnh:
npx tar-vfs-index --append archive.tar.gz
Kết quả là một file .tar.gz tự chứa (self-contained), cho phép bộ nạp (loader) mount mà không cần tìm nạp một file metadata riêng biệt. Tuy nhiên, nó cần thực hiện thêm một số công việc để trích xuất file metadata nhúng trước khi mount. WebR đang sử dụng phương pháp này cho các gói nhị phân của mình.
Kết luận: Tại sao kỹ thuật này hiệu quả
Sự kết hợp của ba yếu tố kỹ thuật đã làm cho giải pháp này khả thi:
- Cấu trúc phẳng của Tar: Dữ liệu tệp đã liền mạch và có thể địa chỉ hóa theo byte, nên lưu trữ tar tự nhiên đóng vai trò là backend lưu trữ cho VFS.
- Cắt blob trong WORKERFS: Backend hệ thống tệp được thiết kế để phục vụ các lần đọc từ blob mà không sao chép, do đó quyền truy cập zero-copy (không sao chép) có sẵn miễn là metadata ở đúng định dạng.
- Hỗ trợ gunzip gốc của trình duyệt: Các file
.tar.gzphải được giải nén trước khi dữ liệu có thể được sử dụng làm blob truy cập ngẫu nhiên. May mắn là các trình duyệt hiện nay thực hiện việc này rất hiệu quả trong quá trình tải xuống.
Kết quả cuối cùng là khi WebR tải một gói R từ file .tar.gz vào hệ thống tệp ảo, chúng ta tránh được rất nhiều thao tác sao chép thừa thãi, và thời gian cũng như bộ nhớ cần thiết xấp xỉ bằng thời gian tải xuống và giải nén một yêu cầu HTTP có kích thước tương ứng.
Bài viết liên quan

Công nghệ
Fosi Audio C3: Card âm thanh gaming tích hợp AI giúp game thủ "nghe thấy" đối thủ
28 tháng 5, 2026

Công nghệ
Founders Fund ra mắt gameshow với sự tham gia của Sam Altman, Palmer Luckey và các nhân vật công nghệ hàng đầu
05 tháng 6, 2026

Công nghệ
Tấn công mạng làm tê liệt nhà máy đường lớn tại Australia, nông dân không thể thu hoạch
17 tháng 6, 2026