
6 bài học "xương máu" về kiến trúc LLM mà ít hướng dẫn nào đề cập
Bài viết chia sẻ 6 bài học sâu sắc về kiến trúc và tối ưu hóa Transformer khi tự xây dựng LLM từ đầu, từ việc ổn định thang hạng trong LoRA, ưu điểm của RoPE, cho đến cơ chế KV Cache và sự đánh đổi trong lượng tử hóa.

Các Mô hình Ngôn ngữ Lớn (LLM) đã tạo ra một cơn sốt toàn cầu. Đa số người dùng chỉ tương tác với chúng thông qua các API đã được tinh chỉnh: nhập câu lệnh (prompt) và nhận câu trả lời. Tuy nhiên, điều mà nhiều người bỏ qua là tầm quan trọng của kiến trúc bên dưới – những yếu tố quyết định nơi mô hình vượt trội và nơi cần cải thiện. Bên dưới "nắp capo" của những mô hình này là những lựa chọn thiết kế không hề hiển nhiên, quyết định tốc độ, chi phí và khả năng xử lý.
Để hiểu rõ kiến trúc này từ đầu đến cuối, tôi đã tự triển khai GPT-2 từ con số không chỉ bằng PyTorch. Trên nền tảng đó, tôi tích hợp thêm các kỹ thuật hiện đại như LoRA (Low-Rank Adapters), RoPE (Rotary Positional Embeddings), KV Cache và nhiều thứ khác. Quá trình thực hiện đã mang lại những khoảnh khắc "đau đầu" và tôi đã ghi chép lại tất cả. Dưới đây là 6 bài học quan trọng nhất mà ít hướng dẫn nào dạy bạn.
1. LoRA vs RsLoRA: Ổn định thang hạng (Rank-Stabilized)
LoRA tinh chỉnh mô hình bằng cách chỉ huấn luyện hai ma trận hạng thấp là B và A, trong khi giữ nguyên các trọng số gốc (W). Điều này giúp giảm đáng kể số lượng tham số cần huấn luyện (trong trường hợp của tôi chỉ còn 0,18%). LoRA sử dụng hai tham số là alpha (α) và rank (r), trong đó tỷ lệ alpha/rank đóng vai trò là hệ số tỷ lệ.
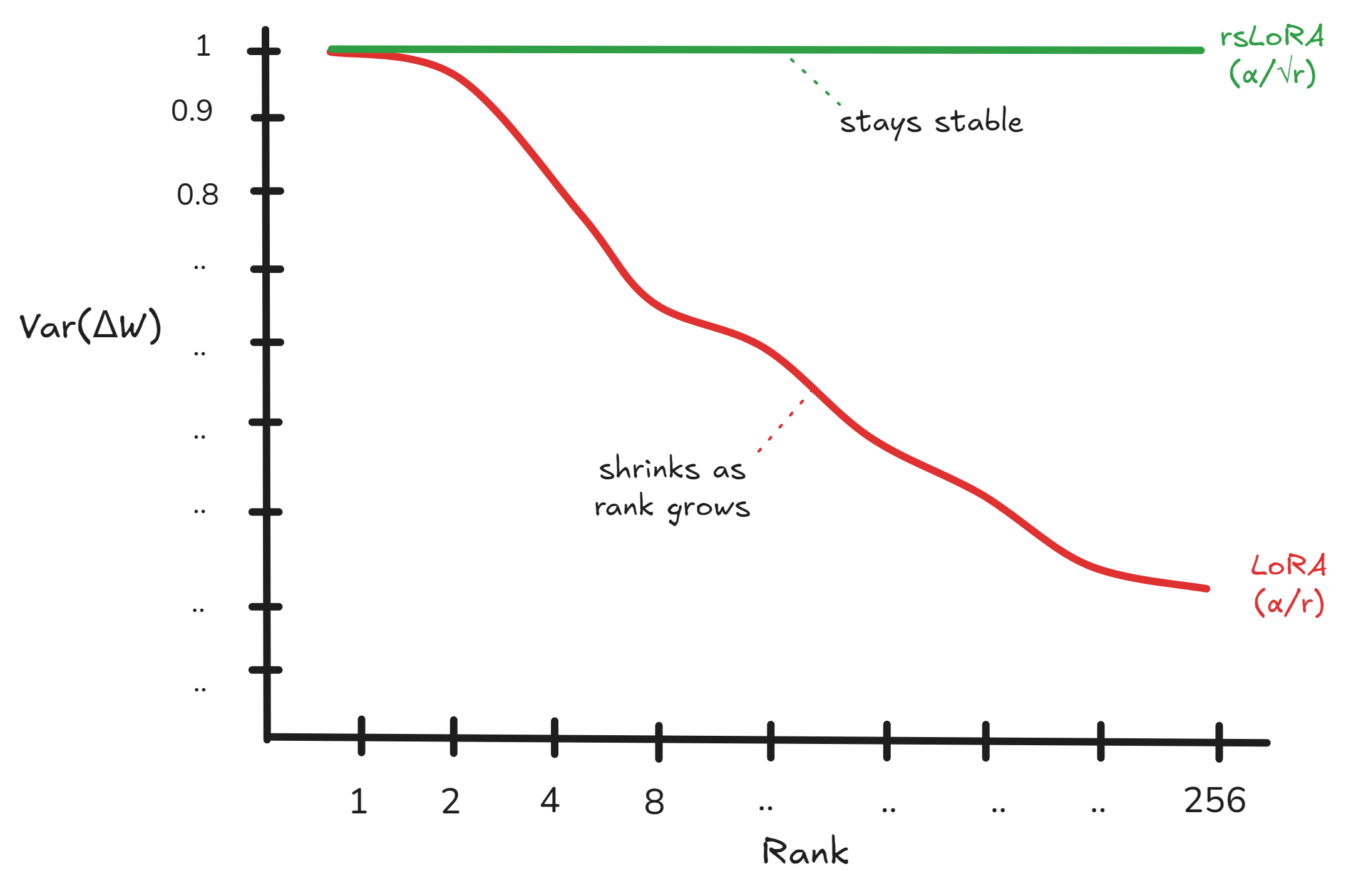 So sánh variance giữa LoRA và RsLoRA
So sánh variance giữa LoRA và RsLoRA
Tuy nhiên, một vấn đề thống kê với LoRA được chỉ ra bởi Kalajdzievski là: nếu giữ việc tăng rank (hạng), việc chia các tham số tinh chỉnh cho rank sẽ cuối cùng làm giảm tầm quan trọng của trọng số. Nói một cách đơn giản: khi rank tăng lên, các cập nhật trọng số riêng lẻ sẽ thu nhỏ lại và LoRA âm thầm trở nên kém hiệu quả mà bạn không hề hay biết.
Để giải quyết vấn đề thu nhỏ này, RsLoRA (Rank-Stabilized LoRA) đã được giới thiệu với một giải pháp đơn giản nhưng hiệu quả: thay thế "r" bằng "√r" (căn bậc hai của r). Điều này giúp phương sai của các trọng số tinh chỉnh trở nên hằng số, đảm bảo độ lớn của trọng số vẫn ổn định với mọi cập nhật. Do đó, tốt hơn hết là nên sử dụng RsLoRA thay vì LoRA truyền thống.
2. Sức mạnh của RoPE so với các phương pháp nhúng vị trí khác
Nhúng vị trí (positional embeddings) thường bị coi là chi tiết phụ, nhưng chúng ta có thể đang đánh giá thấp tầm quan trọng của nó. Một cách tiếp cận sai lầm có thể hoàn toàn làm hỏng một mô hình LLM khổng lồ. Bài báo gốc "Attention Is All You Need" sử dụng Sinusoidal Positional Embeddings (PEs). Cách tiếp cận này không sử dụng tham số nhưng thiếu tính linh hoạt để nắm bắt các vị trí tương đối và làm thay đổi độ lớn của thông tin thực tế trong token embeddings.
Các mô hình như GPT-2 và GPT-3 sau đó chuyển sang cách tiếp cận Learned Parameters (Tham số có thể học), để mạng nơ-ron tự tìm thông tin vị trí. Tuy nhiên, cách này làm tăng tải trọng tham số và vấn đề cộng trực tiếp vào token embeddings vẫn còn tồn tại.
RoPE (Rotary Positional Embeddings) đã giải quyết hầu hết các nhược điểm này. Khác với các cách tiếp cận cũ, RoPE mã hóa vị trí bằng cách xoay các ma trận Query và Key dựa trên vị trí và tần số của chúng, để nguyên token embeddings không bị thay đổi. RoPE đạt được hai mục tiêu cùng lúc: không thêm tải trọng tham số và không cộng trực tiếp, đảm bảo thông tin gốc được bảo toàn.
3. Weight Tying: Chia sẻ trọng số
Weight Tying đề cập đến việc chia sẻ trọng số giữa lớp nhúng token (token embedding layer) và đầu ra (output projection head). Về mặt lịch sử, GPT, GPT-2 và BERT đều sử dụng kỹ thuật này. Trên một mô hình 124 triệu tham số, nó giúp tiết kiệm 38 triệu tham số (khoảng 30%), một con số đáng kể. Trực giác cũng cho thấy điều này hợp lý vì lớp nhúng ánh xạ token -> vector và đầu ra ánh xạ vector -> token, chúng là phép chuyển vị tự nhiên của nhau.
Tuy nhiên, khi các mô hình mở rộng lên hàng tỷ tham số, khoản tiết kiệm 38 triệu này trở nên ít hơn 0,5% tổng số, thực sự không có ý nghĩa gì. Do đó, hầu hết các LLM hiện đại như LLaMA, Mistral và Falcon giữ chúng riêng biệt, vì việc tách biệt cho phép đầu ra tự do chuyên biệt hóa độc lập. Weight Tying có ý nghĩa với các mô hình nhỏ, nhưng đã âm thầm biến mất khi mô hình được mở rộng quy mô.
4. Pre-LayerNorm so với Post-LayerNorm
Pre-LN và Post-LN nằm ở hai phía đối diện của sự đánh đổi giữa ổn định và hiệu suất. Kiến trúc Transformer gốc sử dụng Post-LN (nơi chuẩn hóa xảy ra sau phép cộng dư). Mặc dù Post-LN có thể dẫn đến hiệu suất cuối cùng tốt hơn, nó nổi tiếng là khó huấn luyện vì có thể gây ra hiện tượng gradient nổ hoặc biến mất trong các mạng sâu.
Bắt đầu với GPT-2, ngành công nghiệp đã chuyển sang Pre-LN (nơi chuẩn hóa xảy ra bên trong khối dư). Lựa chọn này ưu tiên sự ổn định khi huấn luyện, mặc dù thường phải đánh đổi một chút về khả năng biểu diễn cuối cùng của mô hình.
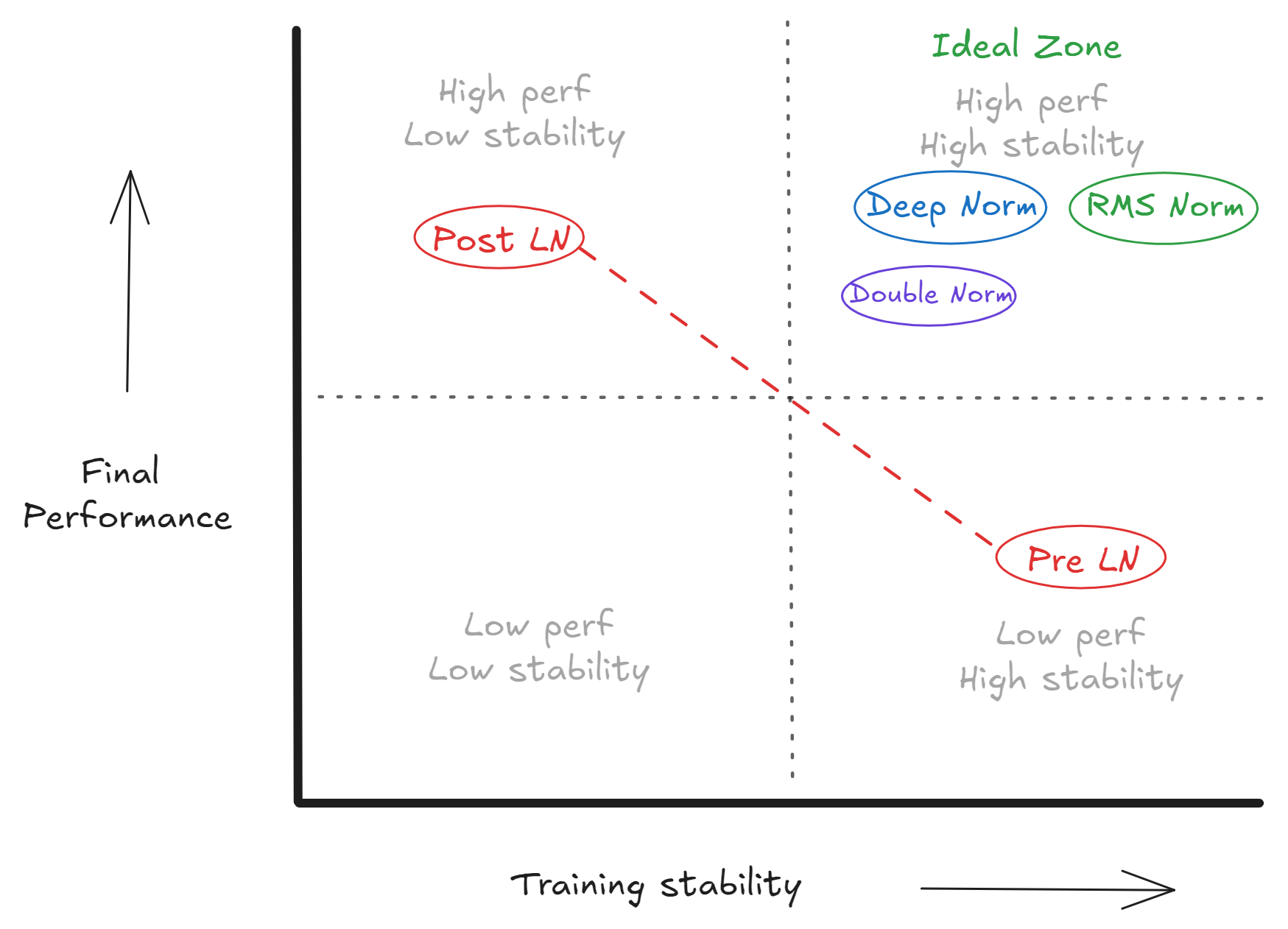 So sánh kiến trúc Pre-LN và Post-LN
So sánh kiến trúc Pre-LN và Post-LN
5. KV-Cache: Tối ưu hóa tốc độ suy luận
Cơ chế attention là động cơ cốt lõi của Transformer, cho phép mô hình duy trì ngữ cảnh dài hạn. Trong quá trình suy luận (inference), các token được dự đoán từng cái một theo cách tự hồi quy. Mỗi token mới phải "chú ý" đến tất cả các token trước đó, nghĩa là các ma trận K và V liên tục được tính toán lại từ đầu cho mỗi token đã thấy. Đây là sự lãng phí lớn.
Giải pháp rất đơn giản: chỉ cần lưu cache (bộ nhớ đệm) các ma trận K và V trong quá trình xử lý. Mỗi token mới chỉ cần tính toán K và V của chính nó, sau đó lấy phần còn lại từ cache. Điều này giúp giảm độ phức tạp thời gian từ O(T²) xuống O(T) cho một chuỗi có độ dài T.
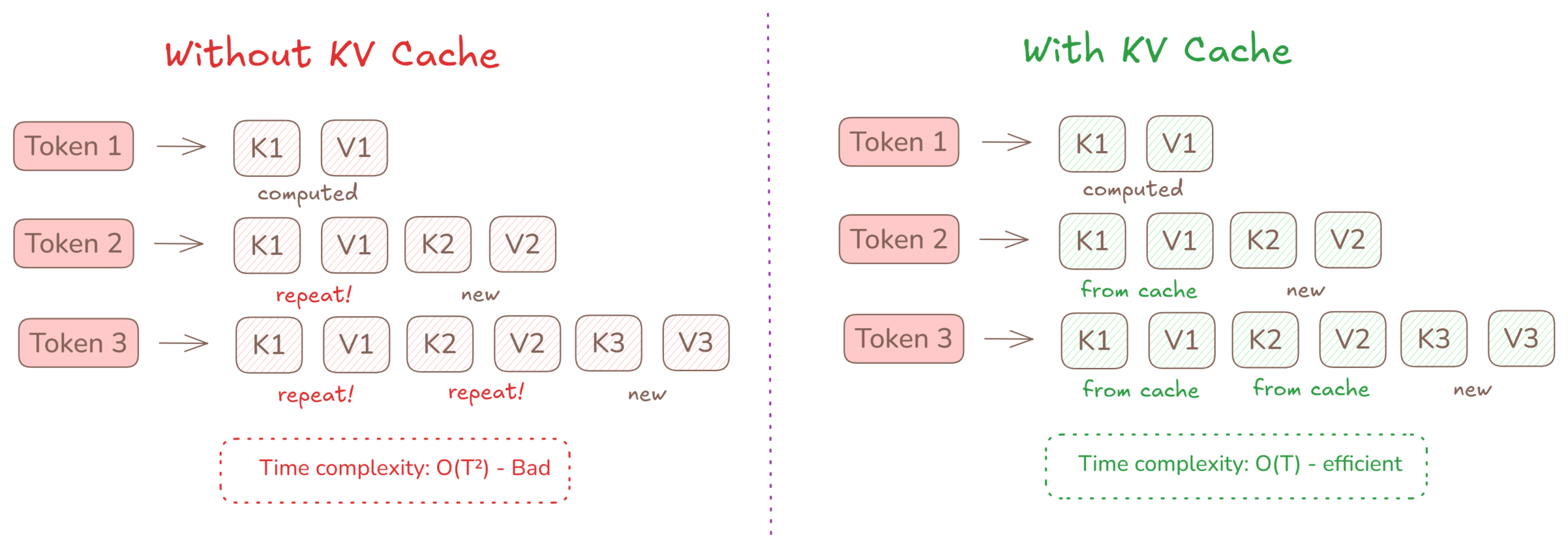 Cơ chế hoạt động của KV Cache
Cơ chế hoạt động của KV Cache
Tuy nhiên, có một sự đánh đổi mà ít ai đề cập: KV Cache không miễn phí. Nó tiêu thụ bộ nhớ tỷ lệ thuận với số_lớp * độ_dài_chuỗi * chiều. Với các ngữ cảnh dài, điều này trở nên đáng kể, và đó chính là lý do bộ nhớ là nút thắt cổ chai trong việc phục vụ LLM, không phải là sức tính toán.
Gần đây, các nghiên cứu như TurboQuant của Google đã tìm cách nén KV Cache xuống chỉ còn 3 bit mỗi giá trị, đạt được mức giảm 5-6 lần tiêu thụ bộ nhớ mà không làm mất độ chính xác.
6. Sự đánh đổi trong Lượng tử hóa: Tại sao LayerNorm bị bỏ qua
Lượng tử hóa (Quantization) là quá trình giảm độ chính xác số học của trọng số mô hình, thường từ 32-bit xuống 8-bit (INT8) hoặc 4-bit, giúp mô hình rẻ hơn và nhanh hơn. Tuy nhiên, lượng tử hóa không được áp dụng mù quáng cho mọi lớp.
LayerNorm hầu như luôn bị bỏ qua trong quá trình lượng tử hóa INT8. Lý do là một phép tính chi phí-lợi ích đơn giản mà ít bài viết giải thích.
Lợi ích là không đáng kể: LayerNorm几乎没有 không có tham số, chỉ có γ và β, một số ít giá trị so với hàng triệu tham số trong một lớp tuyến tính. Việc tiết kiệm từ việc lượng tử hóa chúng về cơ bản bằng không.
Chi phí lại rất cao: LayerNorm nhạy cảm về mặt toán học. Nó tính toán trung bình và phương sai trên mỗi nhúng token, sau đó áp dụng γ và β để thay đổi tỷ lệ. Các sai số chính xác nhỏ trong các tham số này (mà INT8 đưa ra) sẽ làm méo mó đầu ra đã chuẩn hóa, gây ra hiệu ứng dây chuyền đến mọi lớp tiếp theo.
Rõ ràng, lượng tử hóa LayerNorm mang lại gần như không có lợi ích trong khi gây ra sự suy giảm chất lượng có nghĩa. Do đó, nó được giữ ở độ chính xác đầy đủ.
Kết luận
6 điều này không phải là bí mật, chúng đang ẩn ngay trước mắt trong mọi LLM lớn. Nhưng các hướng dẫn hiếm khi dừng lại để giải thích lý do tại sao. Tại sao RsLoRA khắc phục vấn đề phương sai mà hầu hết mọi người không nhận ra. Tại sao RoPE để nguyên token embeddings. Tại sao Weight Tying âm thầm biến mất khi mô hình mở rộng. Tại sao Pre-LN đánh đổi hiệu suất lấy sự ổn định. Tại sao KV Cache biến O(T²) thành O(T). Tại sao LayerNorm sống sót qua lượng tử hóa với độ chính xác đầy đủ.
Xây dựng từ con số không buộc bạn phải đối mặt với mọi quyết định này. Bạn không thể trừu tượng hóa chúng. Và đó chính là lý do tôi khuyên bất kỳ ai thực sự muốn hiểu cách các hệ thống này hoạt động, không chỉ là sử dụng chúng, nên thử tự tay xây dựng.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Google tung ra Antigravity 2.0: Ứng dụng lập trình thế hệ mới với công cụ CLI và gói đăng ký AI Ultra
19 tháng 5, 2026