
Agent AI của bạn đã ngừng hoạt động 2 tiếng rồi, nhưng chẳng ai hay biết
Agent vẫn chạy, Container báo trạng thái khỏe, nhưng lại không xử lý công việc. Bài viết phân tích tại sao các kiểm tra sức khỏe truyền thống của Kubernetes thất bại với AI Agents và giải pháp Heartbeat giúp phát hiện sự cố ngay lập tức.

Agent AI của bạn đã ngừng hoạt động 2 tiếng rồi, nhưng chẳng ai hay biết
Agent đã được triển khai xong. Pod đang chạy. Container vượt qua các bài kiểm tra liveness (sự sống). Grafana hiện một đường màu xanh phẳng lặng. Mọi thứ trông rất ổn.
Trừ việc agent đã ngừng xử lý công việc từ 2 tiếng trước. Nó vẫn "sống" — tiến trình vẫn ở đó — nhưng lại bị tắc nghẽn (deadlocked) ở một luồng (thread) nào đó. Bị chặn bởi một hàng đợi (queue) đầy ắp. Hoặc đang quay vòng trong một vòng lặp thử lại (retry loop) mà không bao giờ thành công. Ngầm nuốt chửng các ngoại lệ (exception) bên trong một vòng lặp while True.
Không ai hay biết cho đến khi khách hàng khiếu nại. Hoặc cho đến khi ai đó mở dashboard vào lúc 5 giờ chiều và tự hỏi tại sao hàng đợi nhiệm vụ lại tăng cả chiều nay.
Tại sao Kiểm tra Sức khỏe Container Không Hoạt động với Agent
Các bài kiểm tra liveness (liveness probes) của Kubernetes chỉ kiểm tra một thứ: tiến trình có phản hồi HTTP không? Nếu agent của bạn cung cấp một điểm cuối /healthz, bài kiểm tra sẽ vượt qua. Agent được coi là "khỏe mạnh".
Tuy nhiên, phản hồi /healthz và xử lý công việc là hai chuyện hoàn toàn khác nhau. Một agent có thể:
- Bị deadlock (bế tắc) trên một khóa nội bộ trong khi vẫn phục vụ HTTP.
- Worker thread bị OOM-kill (giết hết bộ nhớ) trong khi main thread vẫn sống sót.
- Rơi vào vòng lặp thử lại vô hạn trên một API xuống stream bị lỗi.
- Ngầm rơi vào nhánh
except: passvà ngừng mọi hoạt động.
Tiến trình đang chạy. Container màu xanh. Nhưng agent thì vô dụng.
Kiểm tra sức khỏe container: "Tiến trình có còn sống không?" CÓ
Thực tế bạn cần: "Agent có đang làm việc không?" KHÔNG
Khoảng trống này tồn tại vì việc điều phối container (container orchestration) được thiết kế cho các máy chủ web không trạng thái (stateless), không phải cho các agent chạy dài hạn (long-running) nắm giữ trạng thái, duy trì kết nối và xử lý công việc một cách bất đồng bộ.
Mô hình Heartbeat (Nhịp tim)
Giải pháp cho vấn đề này thực ra không mới. Các dịch vụ web đã giải quyết nó 15 năm trước thông qua giám sát nhịp tim (heartbeat monitoring). Ý tưởng rất đơn giản: agent định kỳ báo cáo "Tôi vẫn sống và đang làm việc". Nếu báo cáo dừng lại, có gì đó sai sót.
Sự khác biệt giữa kiểm tra sức khỏe và nhịp tim: kiểm tra sức khỏe bị động (có cái gì đó ping bạn), nhịp tim chủ động (bạn báo cáo ra ngoài). Một agent bị kẹt có thể phản hồi ping, nhưng không thể gửi nhịp tim. Đó chính là điểm mấu chốt.
Tuy nhiên, việc xây dựng hạ tầng nhịp tim cho agent đồng nghĩa với việc:
# 1. Người gửi nhịp tim (thêm vào mỗi agent)
import threading, time, requests
def heartbeat_loop(agent_id, interval=30):
while True:
try:
requests.post(
"https://monitoring.internal/heartbeat",
json={"agent_id": agent_id, "ts": time.time()},
timeout=5,
)
except Exception:
pass
time.sleep(interval)
threading.Thread(target=heartbeat_loop, args=("my-agent",), daemon=True).start()
# 2. Người kiểm tra nhịp tim (tiến trình cron riêng biệt)
# 3. Redis/Postgres để lưu trữ nhịp tim
# 4. Quy tắc cảnh báo (Slack, PagerDuty)
# 5. Dashboard hiển thị thời gian nhìn thấy lần cuối
# 6. Logic để phân biệt "dừng chủ động" và "crash"
# 7. Dọn dẹp cho các agent đã hủy đăng ký
Đó là một hệ thống giám sát. Bạn phải duy trì nó cho từng framework agent, cho từng môi trường triển khai, mãi mãi.
Chỉ Cần Một Dòng Code
Thay vì tất cả những thứ phức tạp trên, bạn có thể làm như sau:
from axme import AxmeClient, AxmeClientConfig
import os
client = AxmeClient(AxmeClientConfig(api_key=os.environ["AXME_API_KEY"]))
client.mesh.start_heartbeat()
Chỉ vậy thôi. Một luồng daemon (daemon thread) sẽ thức dậy mỗi 30 giây, gửi một nhịp tim đến nền tảng, rồi quay lại ngủ. Khi agent dừng lại — vì crash, deadlock, OOM, hoặc lỗi phân vùng mạng — các nhịp tim cũng dừng theo. Nền tảng sẽ nhận ra ngay.
Không cần Redis. Không cần cron. Không cần Prometheus. Không cần tích hợp webhook. Không cần quy tắc cảnh báo phải bảo trì.
Cách Tính toán Sức khỏe
Nền tảng theo dõi dấu thời gian của từng nhịp tim và tự động tính toán sức khỏe:
| Thời gian kể từ nhịp tim cuối | Trạng thái | Ý nghĩa |
|---|---|---|
| < 90 giây | healthy (Khỏe mạnh) | Agent đang sống và báo cáo |
| 90 - 300 giây | degraded (Suy giảm) | Agent có thể bị kẹt hoặc quá tải |
| > 300 giây | unreachable (Không thể tiếp cận) | Agent đã tắt hoặc không báo cáo |
| Tắt thủ công | killed (Đã chặn) | Người vận hành đã chặn agent này một cách có ý thức |
Ngưỡng được thiết kế xung quanh khoảng thời gian mặc định là 30 giây. Một agent khỏe mạnh với interval_seconds=30 sẽ gửi nhịp tim mỗi 30 giây. Nếu nền tảng không nhận được tín hiệu trong 90 giây (lỡ 3 nhịp), có lẽ có vấn đề gì đó. Nếu qua 5 phút, coi như agent đã mất.
Trạng thái degraded (suy giảm) là trạng thái hữu ích nhất. Nó là cảnh báo sớm. Agent chưa chết hẳn, nhưng đã lỡ vài nhịp. Có thể vòng lặp sự kiện (event loop) đang quá tải. Có thể GC dọn rác tốn 45 giây. Có thể mạng không ổn định. Bạn có một khoảng thời gian để điều tra trước khi agent trở nên hoàn toàn không thể tiếp cận.
Điều Gì Xảy Ra Khi Agent Bị Down
Dưới đây là mốc thời gian với giám sát nhịp tim:
00:00 Agent khởi động. Bắt đầu gửi nhịp tim.
00:30 Nhịp tim gửi đi. Trạng thái: healthy.
01:00 Nhịp tim gửi đi. Trạng thái: healthy.
01:15 Agent bị deadlock trên pool kết nối database.
01:30 Không có nhịp tim. (Agent bị kẹt, không thể gửi).
02:00 Không có nhịp tim trong 90s. Trạng thái: healthy -> degraded.
02:00 Nền tảng ghi log chuyển đổi trạng thái.
05:15 Không có nhịp tim trong 300s. Trạng thái: degraded -> unreachable.
05:15 Nền tảng chặn việc gửi intent mới đến agent này.
Nếu không có giám sát nhịp tim:
00:00 Agent khởi động.
01:15 Agent bị deadlock.
...
...
03:15 Ai đó nhận ra hàng đợi nhiệm vụ đang tăng lên.
03:30 Kỹ sư SSH vào. "Tiến trình đang chạy."
03:45 "Container màu xanh. Log thì trông ổn... đợi đã, không có log mới nào từ 1:15."
04:00 Kỹ sư khởi động lại agent.
Sự khác biệt: 2 phút so với 2.75 tiếng. Và kịch bản đầu tiên là tự động — không cần con người phải nhận ra bất cứ điều gì.
Nhịp tim Đi kèm Chỉ số (Metrics)
Nhịp tim không chỉ là một tín hiệu ping. Nó có thể mang theo các chỉ số vận hành, được đẩy (flush) tự động cùng mỗi nhịp:
client.mesh.start_heartbeat(include_metrics=True)
# Khi agent xử lý công việc, báo cáo chỉ số
client.mesh.report_metric(success=True, latency_ms=234.5, cost_usd=0.003)
client.mesh.report_metric(success=False, latency_ms=5012.0)
# Chỉ số được lưu trong bộ nhớ đệm và gửi cùng nhịp tim tiếp theo
# Không cần pipeline chỉ số riêng biệt
Mỗi 30 giây, nhịp tim sẽ gửi cả thông điệp "Tôi vẫn sống" và "Dưới đây là tình hình của tôi" — tỷ lệ thành công, độ trễ trung bình, chi phí tích lũy. Nền tảng sẽ tổng hợp theo từng agent và hiển thị thông qua CLI và dashboard.
Điều này biến nhịp tim từ một tín hiệu sống/chết nhị phân thành một tín hiệu sức khỏe liên tục. Một agent đang sống nhưng xử lý tác vụ với độ trễ gấp 20 lần bình thường sẽ được phát hiện trước khi nó trở thành vấn đề lớn.
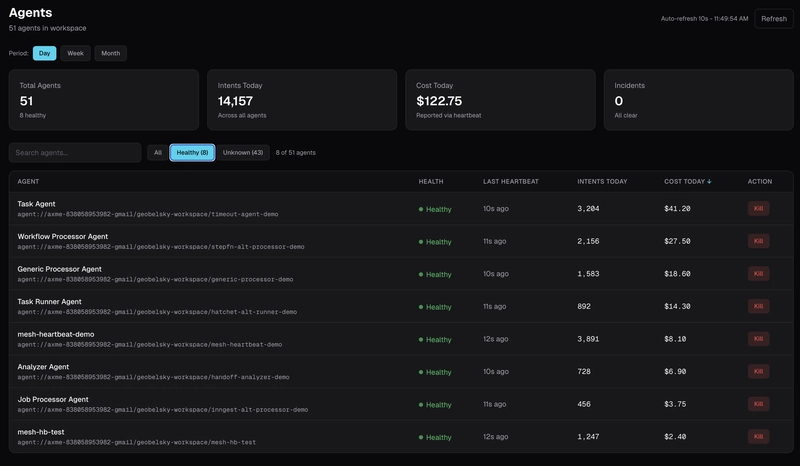 Dashboard giám sát Fleet Agent
Dashboard giám sát Fleet Agent
Chặn và Tiếp tục (Kill và Resume)
Đôi khi bạn cần dừng một agent. Không phải vì crash — mà là chặn một cách có chủ đích. Có thể nó hoạt động sai lệch. Có thể bạn đang bảo trì. Có thể nó đang ngốn ngân sách API của bạn quá nhanh.
# Từ code (lấy address_id từ list_agents)
client.mesh.kill("addr_abc123")
Một agent bị chặn sẽ进入 trạng thái killed. Ngay cả khi luồng nhịp tim vẫn chạy, cổng gateway (gateway) vẫn giữ nó ở trạng thái bị chặn. Không có intent nào được giao tiếp. Nó vẫn ở đó cho đến khi được tiếp tục một cách rõ ràng:
client.mesh.resume("addr_abc123")
Hoặc bạn có thể chặn/tiếp tục từ dashboard tại mesh.axme.ai chỉ bằng một cú click.
Điều này khác với việc agent bị crash. Crash dẫn đến unreachable (không thể tiếp cận). Còn chặn (kill) là có chủ đích. Sự phân biệt này rất quan trọng cho việc cảnh báo — bạn không muốn thông báo (page) cho người trực vận hành (on-call) về một agent mà bạn đã tự ý dừng.
Tầm nhìn Toàn cảnh cho Fleet (Fleet Visibility)
Khi bạn có 20 agent trải dài trên 4 máy chủ, dashboard quan trọng hơn bất kỳ nhịp tim đơn lẻ nào.
Dashboard AXME Mesh tại mesh.axme.ai hiển thị sức khỏe hoàn chỉnh của fleet theo thời gian thực:
Mở nó bằng lệnh:
axme mesh dashboard
report-generator killed (manual)
Summary: 2 healthy, 1 degraded, 1 unreachable, 1 killed
Một lệnh duy nhất. Sức khỏe fleet hoàn chỉnh. Không cần SSH. Không cần Grafana. Không cần pipeline tổng hợp log.
Chi phí Thực tế của Các Lỗi Thầm lặng (Silent Failures)
Mọi đội ngũ vận hành agent ở quy mô đều có câu chuyện giống nhau. Một agent bị xuống vào chiều thứ Sáu. Không ai nhận ra cho đến sáng thứ Hai. 60 tiếng xử lý bị bỏ lỡ. Khách hàng phàn nàn. Các công việc tồn đọng mất thêm 8 tiếng để giải quyết.
Giải pháp không hề phức tạp. Nó chỉ là một lời gọi hàm. Phần khó khăn là nhớ rằng việc container vượt qua các bài kiểm tra sức khỏe không đồng nghĩa với việc agent đang làm việc.
client.mesh.start_heartbeat()
Đó là toàn bộ giải pháp.
Hãy Thử Ngay
Ví dụ thực tế — khởi động một agent với nhịp tim, giết tiến trình, và quan sát trạng thái chuyển từ healthy sang degraded rồi unreachable:
github.com/AxmeAI/ai-agent-heartbeat-monitoring
Được xây dựng với AXME — nhịp tim, phát hiện sức khỏe và giám sát fleet cho các AI Agent. Phiên bản Alpha — rất mong nhận được phản hồi từ bạn.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Google tung ra Antigravity 2.0: Ứng dụng lập trình thế hệ mới với công cụ CLI và gói đăng ký AI Ultra
19 tháng 5, 2026