
Benders’ Decomposition: Chìa khóa giải quyết bài toán tối ưu hóa quy mô lớn
Benders’ Decomposition là kỹ thuật thuật toán quan trọng giúp xử lý các bài toán lập trình ngẫu nhiên phức tạp bằng cách chia nhỏ chúng thành các bài toán con dễ quản lý hơn. Bài viết này sẽ đi sâu vào cơ chế hoạt động, từ việc phân tích cấu trúc ma trận ràng buộc đến việc sử dụng các "cắt" (cuts) để hội tụ về nghiệm tối ưu.

Trong lĩnh vực khoa học dữ liệu và tối ưu hóa, chúng ta thường gặp những bài toán quá lớn để giải quyết trực tiếp. Bài viết này sẽ khám phá Benders’ Decomposition — một phương pháp cổ điển nhưng vô cùng mạnh mẽ để "nứt vỡ" các bài toán lập trình ngẫu nhiên (stochastic program) khổng lồ thành các phần có thể giải quyết được.
Vấn đề: Khi mô hình trở nên quá cồng kềnh
Trong bài viết trước về lập trình ngẫu nhiên, chúng ta đã thảo luận về mô hình hai giai đoạn (two-stage recourse models). Về lý thuyết, chúng rất gọn gàng: bạn đưa ra quyết định đầu tiên, chờ đợi sự bất ngờ xảy ra, sau đó đưa ra quyết định điều chỉnh.
Tuy nhiên, trong thực tế, khi số lượng kịch bản (scenarios) tăng lên, mô hình "tương đương xác định" (deterministic equivalent) sẽ bùng nổ về kích thước. Các trình giải (solver) như Gurobi hay HiGHS bắt đầu "kêu cứu" vì thời gian chạy tăng siêu tuyến tính so với kích thước bài toán.
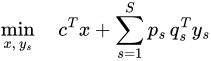 Cấu trúc ma trận khối-góc
Cấu trúc ma trận khối-góc
Ma trận ràng buộc của các bài toán này thường có dạng "khối-góc" (block-angular). Mỗi kịch bản tạo ra một khối riêng biệt, nhưng tất cả đều bị trói buộc bởi cùng một biến quyết định đầu tiên. Cấu trúc này là chìa khóa để giải quyết vấn đề.
Quan sát then chốt: Tách biệt các biến
Hãy nhìn vào cấu trúc ma trận một lần nữa. Nếu chúng ta cố định biến quyết định đầu tiên ($x$), phần còn lại của bài toán sẽ tách rời hoàn toàn. Mỗi kịch bản trở thành một bài toán quy hoạch tuyến tính (LP) nhỏ độc lập.
Đây chính là ý tưởng cốt lõi của Benders’ Decomposition:
- Đưa ra phỏng đoán cho quyết định đầu tiên ($x$).
- Giải các bài toán con cho từng kịch bản dựa trên $x$ đó.
- Sử dụng thông tin từ các bài toán con để cập nhật phỏng đoán $x$.
- Lặp lại cho đến khi không còn cải thiện.
Cơ chế toán học: Các "Cắt" (Cuts) và Tính đối ngẫu
Phần khó nhất là bước 3: Làm thế nào các bài toán con nói cho chúng ta biết gì về $x$? Câu trả lời nằm ở tính đối ngẫu tuyến tính (LP duality).
Hàm chi phí dự phòng $Q(x)$ là một hàm lồi từng khúc (piecewise-linear convex). Một đặc tính tuyệt vời của các hàm này là tại bất kỳ điểm nào, chúng ta có thể tìm được một cận dưới tuyến tính (một đường thẳng) chạm vào hàm số tại điểm đó và nằm dưới nó ở mọi nơi khác.
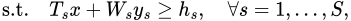 Hàm giá trị và các cắt tối ưu
Hàm giá trị và các cắt tối ưu
Mỗi lần chúng ta giải các bài toán con tại một điểm $x$, chúng ta nhận được một "cắt tối ưu" (optimality cut). Đây là một bất đẳng thức tuyến tính đóng vai trò là cận dưới cho chi phí thực sự. Chúng ta thêm các cắt này vào bài toán chính (Master Problem) để buộc nó tìm ra nghiệm tốt hơn.
Thuật toán Benders hoạt động như thế nào?
Thuật toán lặp đi lặp lại theo quy trình sau:
- Giải bài toán chính: Tìm cặp $(x, \theta)$ tốt nhất hiện tại, trong đó $\theta$ là ước lượng chi phí dự phòng.
- Giải bài toán con: Với $x$ vừa tìm được, giải từng bài toán con cho tất cả các kịch bản để lấy giá trị thực và các biến đối ngẫu.
- Tạo cắt mới: Dựa trên kết quả bài toán con, tạo ra một bất đẳng thức mới (cắt) và thêm vào bài toán chính.
- Kiểm tra: Nếu ước lượng $\theta$ đã đủ sát với thực tế, dừng lại. Nếu không, quay lại bước 1.
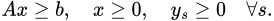 Minh họa một vòng lặp của thuật toán
Minh họa một vòng lặp của thuật toán
Quá trình này đảm bảo hội tụ trong hữu hạn số bước vì số lượng cắt (đỉnh của đa diện) là hữu hạn.
Các biến thể và Thách thức
Có hai biến thể chính: Uni-cut (tổng hợp thông tin thành một cắt) và Multi-cut (giữ riêng từng cắt cho từng kịch bản). Multi-cut thường hội tụ nhanh hơn nhưng làm bài toán chính phức tạp hơn.
Tuy nhiên, Benders không phải là công cụ thần thánh. Nó có thể hội tụ chậm trong thực tế, và bài toán chính có thể trở thành nút thắt (bottleneck). Các kỹ sư thường phải sử dụng các mẹo như loại bỏ các cắt cũ, giải bài toán chính không hoàn toàn tối ưu ở các vòng lặp đầu, hoặc song song hóa các bài toán con.
Kết luận
Benders’ Decomposition là minh chứng cho sức mạnh của việc tận dụng cấu trúc bài toán. Thay vì cố gắng nuốt chửng một bài toán khổng lồ, chúng ta chia nhỏ nó, giải quyết từng phần và khâu nối chúng lại với nhau bằng ngôn ngữ toán học.
Phương pháp này được ứng dụng rộng rãi trong lập kế hoạch chuỗi cung ứng, điều hành thủy điện và nhiều lĩnh vực khác nơi sự bất ngờ là một phần tất yếu của mô hình.
Nếu bạn có thể viết lại một bài toán tối ưu hóa sao cho việc cố định một số biến làm cho phần còn lại tách biệt, hãy thử Benders. Đó có thể là sự khác biệt giữa việc giải được bài toán và việc bó tay.
Bài viết liên quan

Phần mềm
Tối ưu hóa hệ thống gợi ý bằng LLM và Python: Cách cân bằng giữa tốc độ và độ chính xác
08 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026

Công nghệ
Amazon ra mắt tính năng Sleep Studio giúp trẻ em đi ngủ dễ dàng hơn trên loa Echo
10 tháng 6, 2026