
Bluesky giải thích nguyên nhân sự cố "Death Spiral" gây mất mạng 8 giờ vào tháng 4/2026
Bluesky vừa công bố báo cáo sau sự cố (post-mortem) về việc mất mạng kéo dài 8 giờ vào tháng 4/2026. Nguyên nhân chính là do một lỗi trong mã nguồn Go thiếu giới hạn đồng thời, dẫn đến việc cạn kiệt cổng mạng (port exhaustion) và tạo ra một vòng lặp tử thần (death spiral) do ghi log quá mức. Đội ngũ kỹ thuật đã chia sẻ chi tiết về quy trình khắc phục và các bài học đắt giá về khả năng quan sát hệ thống (observability).
Bluesky vừa công bố báo cáo sau sự cố (post-mortem) về việc mất mạng kéo dài 8 giờ vào tháng 4/2026. Nguyên nhân chính là do một lỗi trong mã nguồn Go thiếu giới hạn đồng thời, dẫn đến việc cạn kiệt cổng mạng (port exhaustion) và tạo ra một vòng lặp tử thần (death spiral) do ghi log quá mức. Đội ngũ kỹ thuật đã chia sẻ chi tiết về quy trình khắc phục và các bài học đắt giá về khả năng quan sát hệ thống (observability).
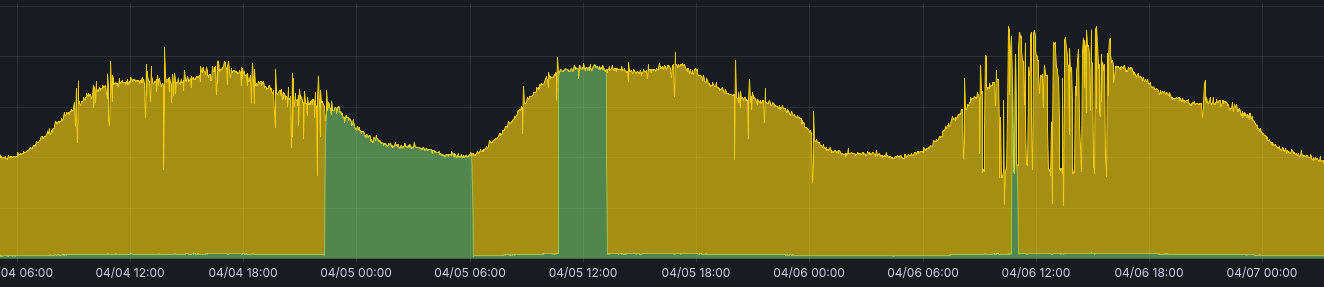
 Biểu đồ lưu lượng truy cập Bluesky
Biểu đồ lưu lượng truy cập Bluesky
Jim Calabro, kỹ sư hệ thống tại Bluesky, đã mở đầu bằng lời xin lỗi chân thành đến người dùng về sự cố gián đoạn dịch vụ này. Ông nhận định đây là đợt mất mạng tồi tệ nhất trong thời gian ông làm việc tại đây và khẳng định tình trạng này là không thể chấp nhận được.
Vấn đề bắt đầu từ đâu
Vấn đề thực tế đã bắt đầu từ cuối tuần trước sự cố chính. Biểu đồ yêu cầu (requests) tới AppView của Bluesky cho thấy những sự sụt giảm nghiêm trọng vào thứ Bảy, đại diện cho thời gian chết mà người dùng phải đối mặt.
Đội ngũ kỹ thuật nhận được cảnh báo vào thứ Bảy ngày 4 tháng 4. Ban đầu, họ nghi ngờ đây là vấn đề về truyền tải mạng (transit issue) vì hệ thống giám sát mạng vẫn hoạt động bình thường. Tuy nhiên, Jim Calabro phát hiện một sự gia tăng đột biến trong các dòng log lỗi tại backend dữ liệu AppView (gọi là "data plane") với thông báo:
"error": "dial tcp 127.32.0.1:0->127.0.0.1:11211: bind: address already in use"
Thời điểm của các đợt tăng log này trùng khớp với sự sụt giảm lưu lượng truy cập, cho thấy mối liên hệ mật thiết. Data plane của Bluesky sử dụng memcached rộng rãi để giảm tải cho cơ sở dữ liệu chính Scylla, và việc cạn kiệt các cổng (ports) là một vấn đề cực kỳ lớn.
Nguyên nhân gốc rễ
Mất khá nhiều thời gian để tìm ra nguyên nhân thực sự do khả năng quan sát (observability) chưa tối ưu. Vấn đề nằm ở một lệnh gọi RPC cụ thể tên là GetPostRecord. Lệnh này nhận một loạt URI bài đăng, tra cứu chúng trong memcached và sau đó là Scylla nếu không tìm thấy trong cache.
Tuần trước, Bluesky đã triển khai một dịch vụ nội bộ mới. Dịch vụ này chỉ gửi dưới 3 yêu cầu GetPostRecord mỗi giây, nhưng mỗi yêu cầu lại chứa các lô (batch) khổng lồ từ 15.000 đến 20.000 URI. Trong khi đó, thông thường họ chỉ xử lý từ 1 đến 50 tra cứu bài đăng cho mỗi yêu cầu.
Mọi trình xử lý RPC trong data plane đều sử dụng tính năng đồng thời có giới hạn (bounded concurrency), ngoại trừ điểm cuối (endpoint) này! Đây là lỗ hổng chết người.
Điều này có nghĩa là hệ thống sẽ khởi chạy 15.000 đến 20.000 goroutine cho một yêu cầu duy nhất, "tấn công" memcached bằng hàng loạt kết nối, sau đó đóng và trả lại cho hệ điều hành. Do kích thước tối đa của pool kết nối rảnh là 1000, các kết nối này sẽ tích tụ trong trạng thái TCP TIME_WAIT và làm cạn kiệt tất cả các cổng khả dụng.
 Mã nguồn Go bị thiếu giới hạn đồng thời
Mã nguồn Go bị thiếu giới hạn đồng thời
Đoạn mã Go bị thiếu dòng quan trọng: // group.SetLimit(50). Nếu có dòng này, số lượng goroutine đồng thời sẽ bị giới hạn, ngăn chặn việc tạo quá nhiều kết nối cùng lúc.
Vòng lặp tử thần (Death Spiral)
Mặc dù dịch vụ đã ổn định vào thứ Hai, nhưng nguyên nhân gốc rễ thực sự chỉ được tìm thấy vào thứ Tư. Vậy điều gì đã xảy ra vào thứ Hai để gây ra sự cố lớn?
Hệ thống đã rơi vào một "vòng lặp tử thần" với phản hồi tiêu cực. Mỗi khi nhận được lỗi từ memcache, hệ thống lại ghi log. Với hàng triệu yêu cầu mỗi giây, Bluesky đã cố gắng thực hiện hàng triệu thao tác ghi log mỗi giây.
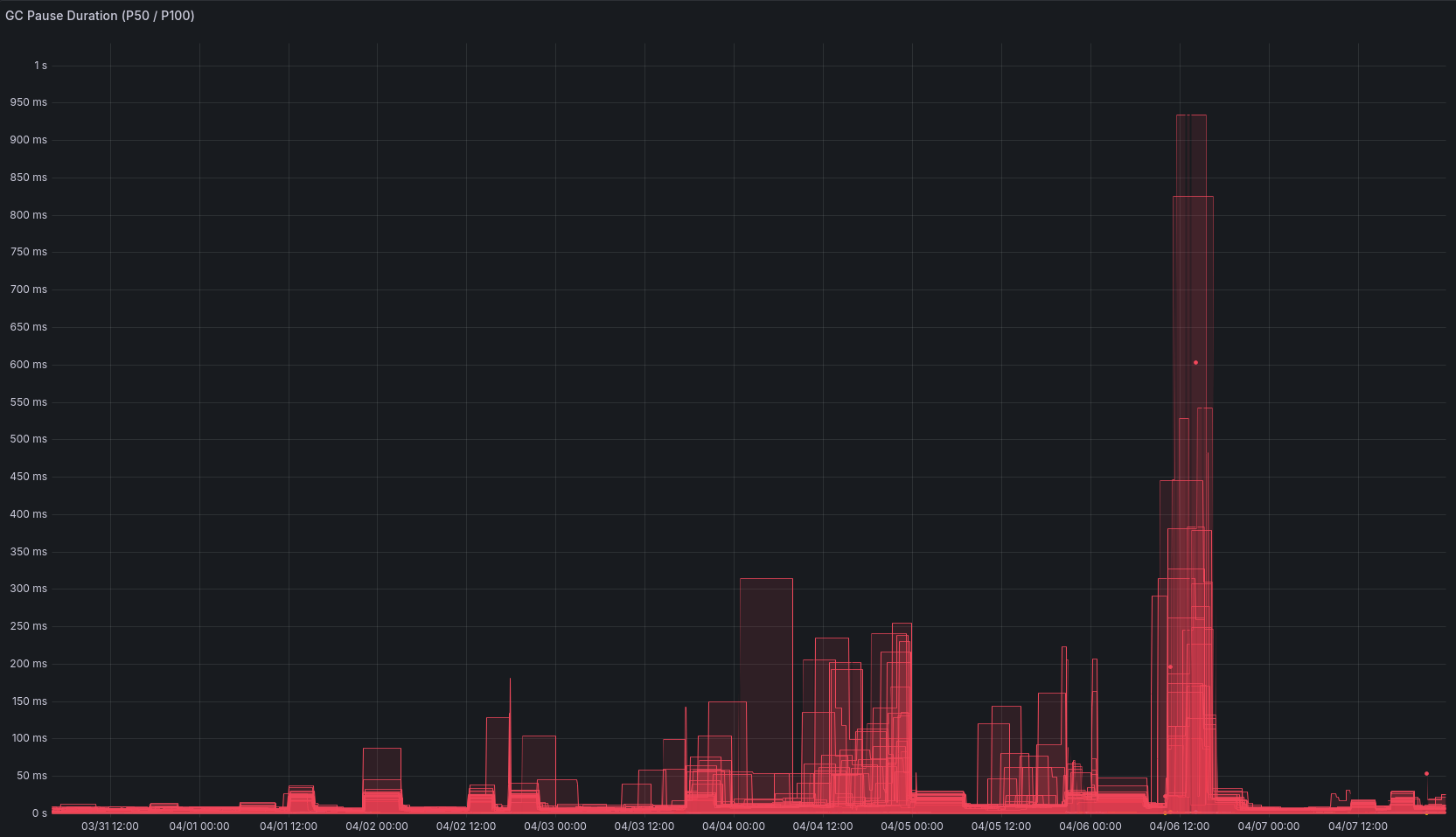
Việc ghi log trong Go sử dụng syscall write(2) dạng chặn (blocking). Số lượng syscall chặn khổng lồ này, kết hợp với việc cố gắng phục vụ hàng triệu yêu cầu, đã khiến Go runtime khởi tạo nhiều luồng hệ điều hành (OS threads - M's) hơn bình thường. Con số này tăng gấp 10 lần so với mức khỏe mạnh (từ 150 lên tới 1500).
Sự gia tăng các luồng này lại gây áp lực lên Bộ thu gom rác (Garbage Collector - GC). Những khoảng dừng lớn trong thời gian dừng thế giới (stop-the-world GC duration) khiến các yêu cầu bị treo.
Kết hợp với việc thiết lập các biến môi trường GOGC và GOMEMLIMIT quá tích cực, data plane đã rơi vào tình trạng hết bộ nhớ (OOM) định kỳ. Dịch vụ hoạt động được 30 phút rồi sập, sau đó lại hoạt động và lặp lại chu trình.
Khi data plane khởi động lại, nó không thể tạo các kết nối memcached mới vì các kết nối cũ vẫn bị kẹt trong trạng thái TIME_WAIT, dẫn đến việc cạn kiệt cổng nghiêm trọng hơn. Đó chính là vòng lặp tử thần!
Giải pháp khắc phục
Giải pháp tạm thời (band-aid fix) được áp dụng là điên rồ nhưng lại hiệu quả. Đội ngũ đã sử dụng một bộ quay số (dialer) tùy chỉnh chọn một địa chỉ IP loopback ngẫu nhiên cho mỗi kết nối. Điều này giúp tránh việc cạn kiệt cổng tạm thời (ephemeral port) trên một địa chỉ IP duy nhất khi container khởi động lại.
memcachedClient.DialContext = func(ctx context.Context, network, address string) (net.Conn, error) {
ip := net.IPv4(127, byte(1+rand.IntN(254)), byte(rand.IntN(256)), byte(1+rand.IntN(254)))
d := net.Dialer{LocalAddr: &net.TCPAddr{IP: ip}}
return d.DialContext(ctx, network, address)
}
Biện pháp này đã giúp họ thoát khỏi vòng lặp tử thần bằng cách mở rộng không gian IP+port của máy khách. Sau khi tìm ra nguyên nhân gốc rễ (thêm dòng group.SetLimit), giải pháp tạm thời này đã được gỡ bỏ.
Bài học rút ra
Jim Calabro chia sẻ một số bài học quan trọng từ sự cố này:
- Observability là chìa khóa: Cần thêm khả năng quan sát theo từng máy khách (per-client o11y) cũng như các chỉ số tốt hơn về việc máy khách gửi số lượng nhỏ các yêu cầu lớn như thế nào.
- Logging quá nhiều không tốt: Việc ghi log ở khắp nơi thì ổn, nhưng ở quy mô lớn, nên ưu tiên sử dụng các chỉ số Prometheus hoặc OTEL tracing vì chúng được thiết kế tốt hơn cho các hệ thống quy mô lớn.
- Kỷ luật tư duy: Cần có kỷ luật tinh thần và độ chi tiết cao trong các chỉ số để có thể cắt qua tiếng ồn và tìm ra nguyên nhân thực sự.
Đội ngũ Bluesky cũng xin lỗi vì thông báo sai lệch trên trang trạng thái (status page) ban đầu đổ lỗi cho nhà cung cấp bên thứ ba. Thực tế, đây hoàn toàn là một lỗi nội bộ.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Google tung ra Antigravity 2.0: Ứng dụng lập trình thế hệ mới với công cụ CLI và gói đăng ký AI Ultra
19 tháng 5, 2026