
Chạy Gemma 4 trên Apple Silicon đạt tốc độ 85 tok/s chỉ với một lệnh cài đặt
Google vừa ra mắt Gemma 4, và giờ đây bạn có thể chạy mô hình này ngay trên máy Mac với tốc độ ấn tượng 85 token/giây. Công cụ Rapid-MLX hỗ trợ đầy đủ tính năng gọi công cụ (tool calling), streaming và API tương thích OpenAI.
Tuần trước, Google đã chính thức phát hành Gemma 4 — dòng mô hình AI mã nguồn mở mạnh mẽ nhất của họ đến nay. Chỉ trong vài giờ, tôi đã có thể chạy Gemma 4 ngay trên máy Mac cá nhân với tốc độ lên tới 85 token/giây, đi kèm đầy đủ tính năng gọi công cụ (tool calling), truyền dữ liệu (streaming) và một API tương thích OpenAI hoạt động với mọi khung AI chính.
Dưới đây là cách thực hiện và những con số hiệu năng thực tế.
Thiết lập: Chỉ với 2 lệnh
pip install rapid-mlx
rapid-mlx serve gemma-4-26b
Chỉ có vậy thôi. Máy chủ sẽ tự động tải xuống mô hình Gemma 4 26B đã được lượng tử hóa 4-bit trên nền tảng MLX (khoảng 14 GB) và khởi động một API tương thích OpenAI tại địa chỉ http://localhost:8000/v1.
 Demo Rapid-MLX
Demo Rapid-MLX
Đo hiệu năng: Gemma 4 26B trên M3 Ultra
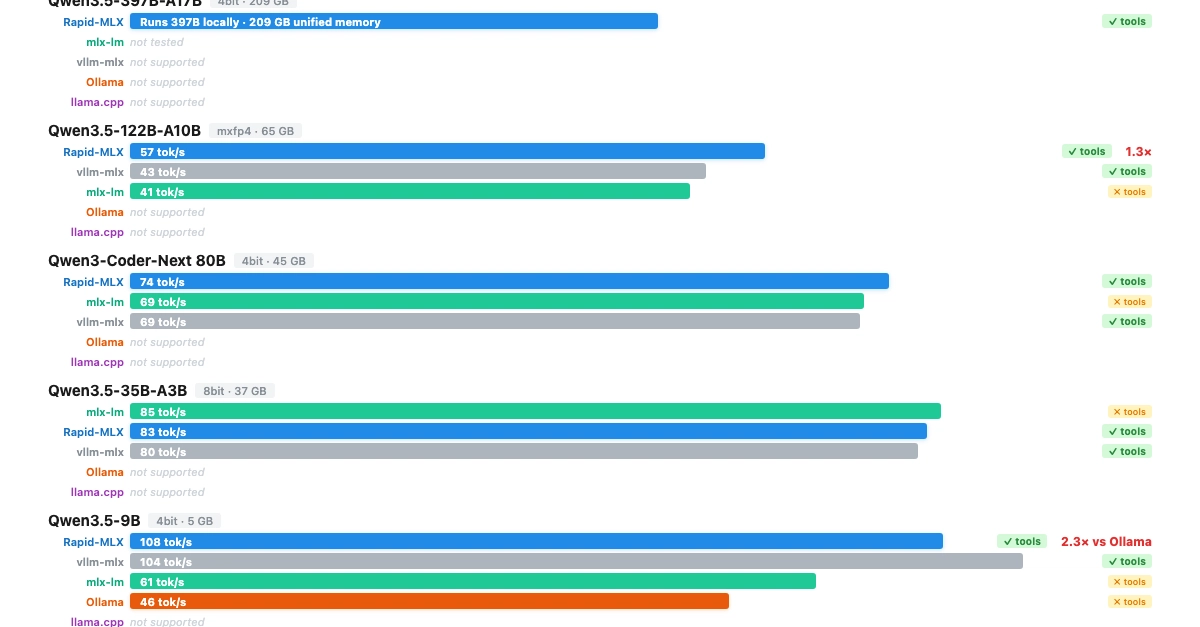
Tôi đã chạy benchmark trên cùng một máy (M3 Ultra, 192GB RAM), cùng một mô hình (Gemma 4 26B-A4B 4-bit) và cùng một câu lệnh (prompt) với ba engine khác nhau:
| Engine | Decode (tok/s) | TTFT | Ghi chú |
|---|---|---|---|
| Rapid-MLX | 85 tok/s | 0.26s | Native MLX, có prompt cache |
| mlx-vlm | 84 tok/s | 0.31s | Thư viện VLM (không có tool calling) |
| Ollama | 75 tok/s | 0.08s | Backend llama.cpp |
Rapid-MLX nhanh hơn Ollama 13% về tốc độ giải mã (decode). Mặc dù Ollama có tốc độ TTFT nhanh hơn (do sử dụng Metal kernels của llama.cpp cho prefill), nhưng đối với trải nghiệm tương tác thực tế, tốc độ decode mới là yếu tố người dùng cảm nhận rõ nhất.
Với các mô hình nhỏ hơn, khoảng cách hiệu năng còn rộng hơn — Rapid-MLX đạt tới 168 tok/s trên Qwen3.5-4B so với khoảng 70 tok/s của Ollama (gấp 2.4 lần).
Tính năng Gọi Công cụ (Tool Calling) Hoạt động Thực tế
Đây là điểm thú vị nhất. Hầu hết các máy chủ suy luận (inference server) cục bộ hiện nay要么 không hỗ trợ tool calling,要么 chỉ hỗ trợ cho một dòng mô hình duy nhất. Rapid-MLX tích hợp sẵn 18 trình phân tích cú pháp tool call, bao gồm:
- Qwen 3 / 3.5 (định dạng hermes)
- Gemma 4 (định dạng gốc
<|tool_call>) - GLM-4.7, MiniMax, GPT-OSS
- Llama 3, Mistral, DeepSeek
- Và nhiều mô hình khác
Tính năng tool calling hoạt động ngay lập tức — không cần cờ (flag) bổ sung nào cho các mô hình được hỗ trợ:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "default",
"messages": [{"role": "user", "content": "Thời tiết ở Tokyo thế nào?"}],
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Lấy thời tiết cho một thành phố",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}]
}'
Kết quả trả về:
{
"choices": [{
"message": {
"tool_calls": [{
"function": {
"name": "get_weather",
"arguments": "{\"city\": \"Tokyo\"}"
}
}]
}
}]
}
Các đối số của tool call được phân tích cú pháp chính xác — bao gồm cả các giá trị số thô như {a: 3, b: 4} mà Gemma 4 tạo ra mà không có dấu ngoặc kép JSON.
Tương thích với Mọi Nền tảng
Vì nó tương thích với OpenAI, bạn có thể kết nối bất kỳ khung AI nào với nó:
PydanticAI
from pydantic_ai import Agent
from pydantic_ai.models.openai import OpenAIChatModel
from pydantic_ai.providers.openai import OpenAIProvider
model = OpenAIChatModel(
model_name="default",
provider=OpenAIProvider(
base_url="http://localhost:8000/v1",
api_key="not-needed",
),
)
agent = Agent(model)
result = agent.run_sync("2 cộng 2 bằng bao nhiêu?")
print(result.output) # "4"
Tôi đã xác minh quá trình này từ đầu đến cuối với đầu ra có cấu trúc (output_type=BaseModel), streaming, hội thoại đa vòng và quy trình đa công cụ.
LangChain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="default",
base_url="http://localhost:8000/v1",
api_key="not-needed",
)
# Tool calling hoạt động
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Nhân hai số."""
return a * b
result = llm.bind_tools([multiply]).invoke("6 nhân 7 bằng bao nhiêu?")
print(result.tool_calls) # [{"name": "multiply", "args": {"a": 6, "b": 7}}]
Aider (Lập trình cặp với AI)
export OPENAI_API_BASE=http://localhost:8000/v1
export OPENAI_API_KEY=not-needed
aider --model openai/gemma-4-26b
Toàn bộ quy trình chỉnh sửa và commit (edit-and-commit) của Aider hoạt động trơn tru — tôi đã kiểm tra việc sửa đổi một tệp Python bằng Gemma 4.
Danh sách Tương thích Đầy đủ
| Client | Trạng thái | Ghi chú |
|---|---|---|
| PydanticAI | Đã kiểm tra (6/6) | Streaming, đầu ra cấu trúc, multi-tool |
| LangChain | Đã kiểm tra (6/6) | Tools, streaming, đầu ra cấu trúc |
| smolagents | Đã kiểm tra (4/4) | CodeAgent + ToolCallingAgent |
| Anthropic SDK | Đã kiểm tra (5/5) | Thông qua endpoint /v1/messages |
| Aider | Đã kiểm tra | Quy trình edit-and-commit trên CLI |
| LibreChat | Đã kiểm tra (4/4) | Docker E2E với librechat.yaml |
| Open WebUI | Đã kiểm tra (3/4) | Docker, tải model, streaming |
| Cursor | Tương thích | Cấu hình UI Settings |
| Claude Code | Tương thích | Biến môi trường OPENAI_BASE_URL |
| Continue.dev | Tương thích | Cấu hình YAML |
Mọi mục "Đã kiểm tra" đều có kịch bản kiểm thử tự động trong kho lưu trữ — không chỉ là "tôi đã thử một lần".
Nên chạy Mô hình nào?
Phụ thuộc vào lượng RAM của máy Mac bạn:
| Mac | Mô hình | Tốc độ | Trường hợp sử dụng |
|---|---|---|---|
| 16 GB MacBook Air | Qwen3.5-4B | 168 tok/s | Chat, lập trình, công cụ |
| 32 GB MacBook Pro | Gemma 4 26B-A4B | 85 tok/s | Đa dụng, gọi công cụ |
| 64 GB Mac Mini/Studio | Qwen3.5-35B | 83 tok/s | Cân bằng thông minh và nhanh |
| 96+ GB Mac Studio/Pro | Qwen3.5-122B | 57 tok/s | Trí tuệ cấp cao nhất |
Bạn có thể xem nhanh danh sách bí danh (alias) bằng lệnh:
rapid-mlx models
Cơ chế hoạt động "Bên trong"
Một vài yếu tố giúp hệ thống này hoạt động hiệu quả:
Prompt cache (Bộ nhớ đệm prompt) — Các system prompt lặp lại (thường gặp trong các khung agent) được lưu vào bộ nhớ cache. Trong các cuộc hội thoại đa vòng, chỉ có các token mới được xử lý. Điều này giúp giảm TTFT xuống 2-10 lần ở các tin nhắn tiếp theo.
OutputRouter — Một máy trạng thái cấp token (token-level state machine) tách đầu ra của mô hình thành các kênh (nội dung / lý luận / tool calls) theo thời gian thực. Không cần xử lý hậu kỳ bằng regex, không bị rò rỉ thẻ <think> hay đánh dấu công cụ vào luồng nội dung.
Tự động phát hiện — Họ mô hình, trình phân tích công cụ và trình phân tích lý luận được tự động phát hiện từ tên mô hình. Không cần cờ thủ công như --tool-parser hermes (mặc dù bạn vẫn có thể ghi đè).
Hãy thử ngay
# Homebrew
brew install raullenchai/rapid-mlx/rapid-mlx
# hoặc pip
pip install rapid-mlx
# Phục vụ Gemma 4
rapid-mlx serve gemma-4-26b
# Trỏ bất kỳ ứng dụng tương thích OpenAI nào tới http://localhost:8000/v1
Kho lưu trữ: github.com/raullenchai/Rapid-MLX
Xây dựng dựa trên khung MLX và mlx-lm của Apple. Giấy phép Apache 2.0.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026