
Chạy Google Gemma 4 cục bộ: Tận dụng LM Studio Headless CLI và Claude Code
Bài viết khám phá cách vận hành mô hình Google Gemma 4 26B cục bộ thông qua công cụ dòng lệnh (CLI) không giao diện mới của LM Studio 0.4.0. Với kiến trúc MoE tối ưu hóa hiệu năng, người dùng có thể kết hợp Gemma 4 với Claude Code để thực hiện các tác vụ lập trình offline một cách mượt mà và tiết kiệm chi phí.
Việc phụ thuộc vào các API đám mây (Cloud AI) đôi khi gặp phải những rào cản như giới hạn tốc độ (rate limit), chi phí sử dụng cao, lo ngại về quyền riêng tư hoặc độ trễ mạng. Đối với các tác vụ nhanh như xem xét mã nguồn (code review), soạn thảo nháp hoặc kiểm tra prompt, việc chạy một mô hình AI trực tiếp trên phần cứng của bạn mang lại lợi thế vượt trội: chi phí API bằng 0, không có dữ liệu nào rời khỏi máy và tính sẵn sàng luôn cao.
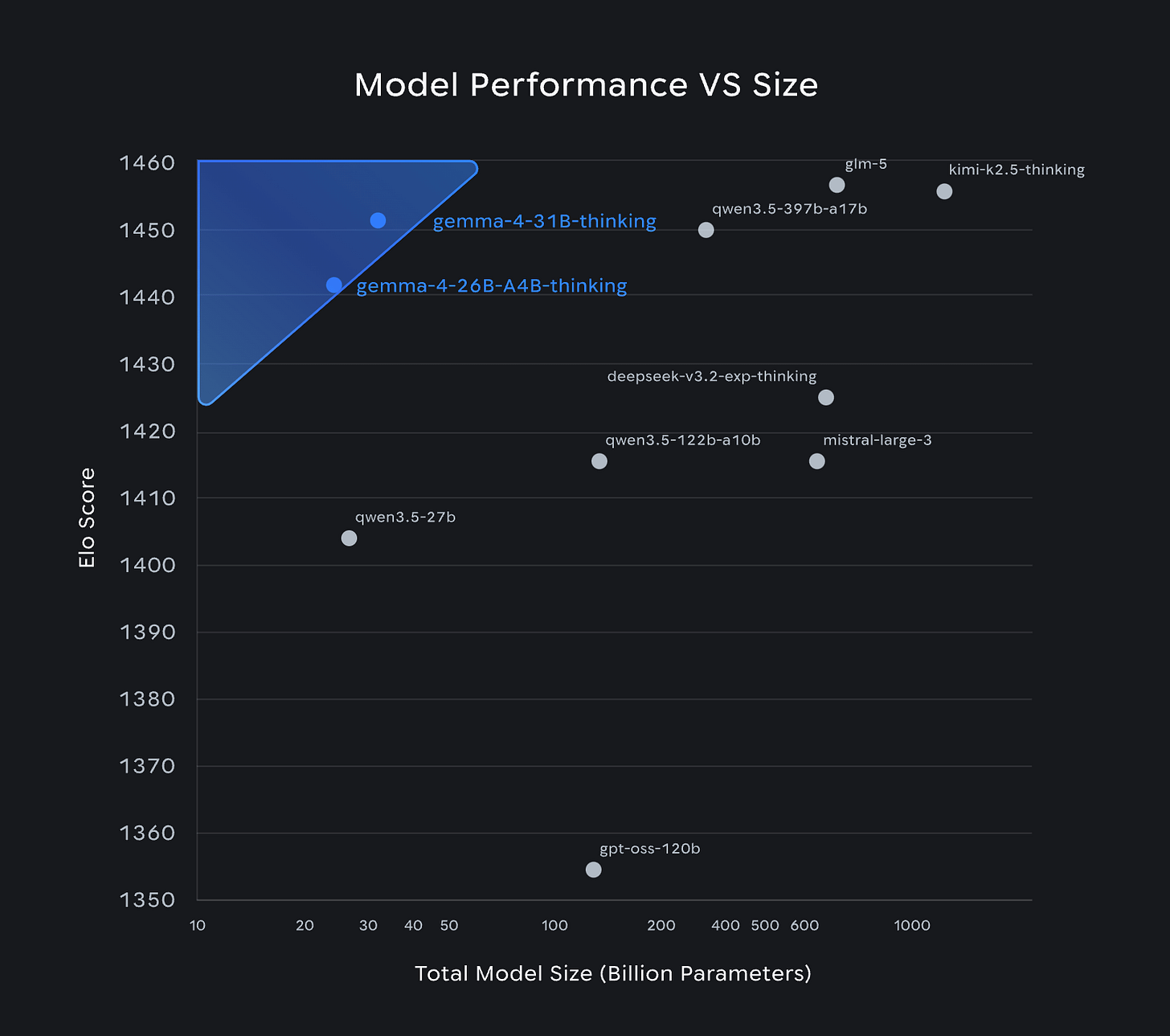
Google Gemma 4 là một ứng cử viên sáng giá cho việc sử dụng cục bộ nhờ kiến trúc Mixture-of-Experts (MoE - Hỗn hợp các chuyên gia). Mô hình 26B tham số (Gemma 4 26B-A4B) chỉ kích hoạt khoảng 4B tham số cho mỗi lần suy luận tiến lên, cho phép nó vận hành mượt mà trên phần cứng mà thông thường không thể xử lý được mô hình dày đặc 26B. Trên chiếc MacBook Pro M4 Pro 14 inch với 48GB bộ nhớ thống nhất, tác giả đã đạt được tốc độ tạo 51 token mỗi giây.
 So sánh hiệu năng mô hình AI
So sánh hiệu năng mô hình AI
Tại sao chọn Gemma 4 26B-A4B?
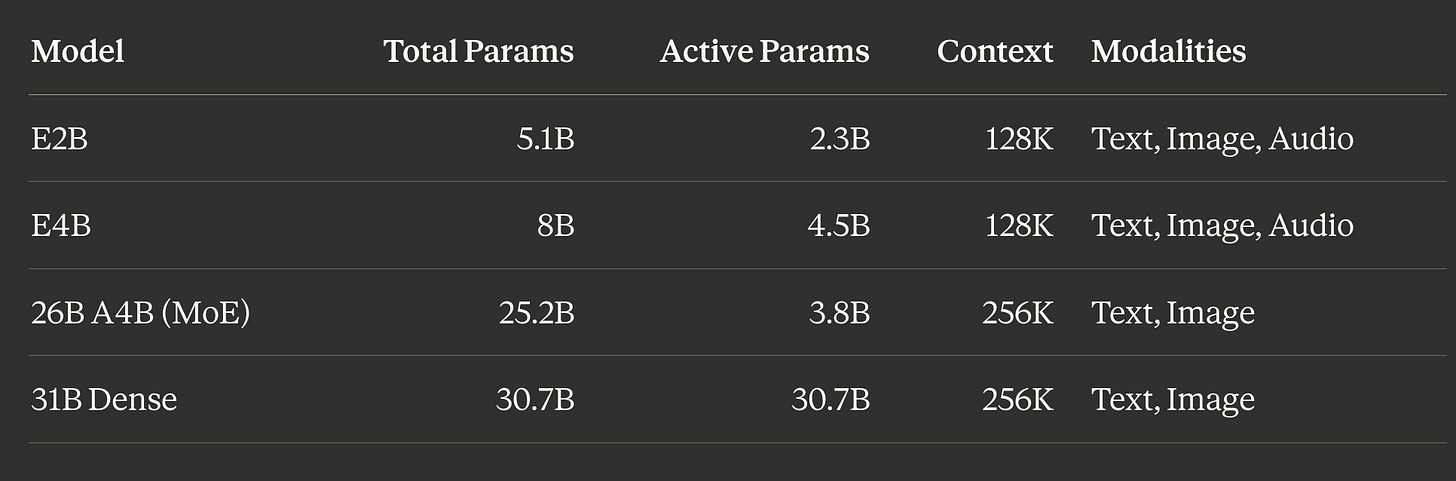
Gemma 4 được Google phát hành dưới dạng một gia đình gồm bốn mô hình. Trong đó, biến thể 26B-A4B sử dụng kiến trúc MoE với 128 chuyên gia và 1 chuyên gia chia sẻ, nhưng chỉ kích hoạt 8 chuyên gia (khoảng 3,8B tham số) cho mỗi token.
Theo kinh nghiệm thực tế, mô hình này mang lại chi phí suy luận tương đương với mô hình dày đặc 4B nhưng chất lượng lại vượt xa phân khúc trọng lượng đó. Các bài kiểm tra benchmark cho thấy Gemma 4 26B-A4B đạt 82,6% trên MMLU Pro và 88,3% trên AIME 2026, rất gần với biến thể dày đặc 31B (85,2% và 89,2%) nhưng chạy nhanh hơn đáng kể. Đây là điểm ngọt (sweet spot) cho máy tính cá nhân có 48GB RAM, cân bằng giữa hiệu suất mạnh mẽ và khả năng xử lý của phần cứng.
LM Studio 0.4.0: Kỷ nguyên của Headless CLI
LM Studio từ lâu đã là ứng dụng desktop phổ biến để chạy mô hình cục bộ. Tuy nhiên, phiên bản 0.4.0 đã thay đổi hoàn toàn kiến trúc bằng cách giới thiệu llmster - động cơ suy luận cốt lõi được trích xuất từ ứng dụng desktop và đóng gói thành một máy chủ độc lập.
Kết quả thực tế là bạn giờ đây có thể chạy LM Studio hoàn toàn từ dòng lệnh bằng công cụ lms CLI. Không cần giao diện đồ họa (GUI). Điều này cực kỳ hữu ích cho các máy chủ không có đầu (headless servers), đường ống CI/CD, phiên SSH hoặc cho các lập trình viên thích làm việc trong terminal.
Cài đặt và thiết lập
Bạn có thể cài đặt lms CLI chỉ với một lệnh duy nhất:
# Linux/Mac
curl -fsSL https://lmstudio.ai/install.sh | bash
# Windows
irm https://lmstudio.ai/install.ps1 | iex
Sau khi cài đặt, hãy khởi chạy daemon chạy ngầm:
lms daemon up
Trên macOS, bạn nên cập nhật cả hai runtime suy luận:
lms runtime update llama.cpp
lms runtime update mlx
Tải và chạy Gemma 4
Với daemon đang chạy, bạn có thể tải mô hình Google Gemma 4 26B:
lms get google/gemma-4-26b-a4b
Hệ thống sẽ mặc định tải xuống phiên bản lượng tử hóa Q4_K_M (khoảng 17,99 GB). Sau khi tải xong, bạn có thể bắt đầu một phiên chat tương tác để kiểm tra hiệu suất:
lms chat google/gemma-4-26b-a4b --stats
 Giao diện dòng lệnh LM Studio
Giao diện dòng lệnh LM Studio
Với tùy chọn --stats, bạn sẽ thấy các chỉ số hiệu suất sau mỗi phản hồi. Trên phần cứng M4 Pro, tốc độ đạt khoảng 51 tokens/giây là một con số rất ấn tượng cho một mô hình kích cỡ này.
Tối ưu hóa bộ nhớ và hiệu suất
Bộ nhớ là yếu tố quan trọng nhất khi chạy LLM cục bộ. Mô hình cơ bản Gemma 4 chiếm khoảng 17,6 GiB. Mỗi lần tăng gấp đôi độ dài ngữ cảnh (context length) sẽ tiêu tốn thêm khoảng 3-4 GiB.
Trước khi tải mô hình, bạn có thể ước tính nhu cầu bộ nhớ ở các độ dài ngữ cảnh khác nhau bằng lệnh:
lms load google/gemma-4-26b-a4b --estimate-only --context-length 48000
Lệnh này sẽ giúp bạn lập kế hoạch khả năng, đảm bảo không bị quá tải bộ nhớ (OOM) khi chạy mô hình song song với các ứng dụng khác. Bạn cũng có thể điều chỉnh các tham số như độ dài ngữ cảnh (--context-length) hoặc tỷ lệ tải lên GPU (--gpu) để phù hợp với phần cứng của mình.
Tích hợp Gemma 4 với Claude Code
Một trong những tính năng thú vị nhất của LM Studio 0.4.0 là điểm cuối API tương thích với Anthropic (tại POST /v1/messages). Điều này mở ra khả năng sử dụng Claude Code với mô hình cục bộ thay vì API của Anthropic, mang lại trợ lý lập trình hoàn toàn ngoại tuyến với chi phí bằng 0.
Bạn có thể thiết lập một bí danh (alias) trong tệp ~/.zshrc:
claude-lm() {
export ANTHROPIC_BASE_URL=http://localhost:1234
export ANTHROPIC_AUTH_TOKEN=lmstudio
export ANTHROPIC_MODEL="google/gemma-4-26b-a4b"
export CLAUDE_CODE_MAX_OUTPUT_TOKENS="8000"
# ... các cấu hình khác
claude "$@"
}
Sau khi chạy source ~/.zshrc, bạn chỉ cần gõ claude-lm để bắt đầu một phiên Claude Code hoàn toàn cục bộ. Mọi yêu cầu sẽ được xử lý bởi Gemma 4 chạy trên máy của bạn thông qua server của LM Studio.
 Giám sát hệ thống khi chạy mô hình cục bộ
Giám sát hệ thống khi chạy mô hình cục bộ
Kết luận
Kiến trúc Mixture-of-Experts là chìa khóa cho suy luận cục bộ hiệu quả. Gemma 4 26B-A4B mang lại chất lượng tương đương mô hình 10B dày đặc nhưng với chi phí tính toán của mô hình 4B.
Sự ra đời của chế độ headless daemon trong LM Studio đã thay đổi quy trình làm việc, cho phép các nhà phát triển tích hợp AI cục bộ vào quy trình làm việc của mình một cách chuyên nghiệp hơn thông qua CLI hoặc API. Việc tích hợp này đặc biệt hữu ích cho các tác vụ nhạy cảm về quyền riêng tư, làm việc ngoại tuyến hoặc tiết kiệm chi phí API cho các phiên khám phá mã nguồn.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026