
Chạy mô hình AI cục bộ (Local LLM) giờ đây đã thực sự tuyệt vời
Các mô hình AI cục bộ đã có sự tiến bộ vượt bậc, cho phép thực hiện lập trình dạng tác nhân (agentic coding) với hiệu suất ấn tượng ngay trên máy cá nhân. Bài viết chia sẻ kinh nghiệm sử dụng Gemma 4, LM Studio và Docker để xây dựng môi trường phát triển an toàn và hiệu quả.

Chạy mô hình AI cục bộ (Local LLM) giờ đây đã thực sự tuyệt vời
Tôi đã làm việc với các mô hình AI cục bộ (local models) từ khi chúng mới bắt đầu xuất hiện, và cuối cùng, chất lượng của chúng giờ đây đã trở nên đáng kinh ngạc. Trên chiếc Mac M2 ra mắt năm 2022 với cấu hình 64GB RAM và 1TB lưu trữ, tôi đã trải nghiệm nhiều mô hình khác nhau như Mistral 7B, Gemma 3, OpenAI OSS-20B, Qwen 3 MOE cùng nhiều biến thể của Qwen như Qwen 2.5 Coder.
Tôi cũng đã thử nghiệm chúng trên nhiều hệ thống thiết lập khác nhau, từ llama.cpp thuần túy với Open WebUI, llama-cpp-python, Ollama, llamafiles cho đến LM Studio.
 Môi trường làm việc với LM Studio
Môi trường làm việc với LM Studio
Vị thế của các mô hình cục bộ hiện nay
Trong giai đoạn đầu, các mô hình này thường chậm chạp, khó sử dụng và không đủ chính xác cho hầu hết các tác vụ lập trình. Ý tưởng cho rằng các mô hình cục bộ bị tụt hậu so với các phiên bản đám mây là hoàn toàn có cơ sở, ít nhất là cho đến khi tôi trải nghiệm GPT-OSS. Mặc dù không có bằng chứng khoa học cụ thể, nhưng thước đo cá nhân của tôi về việc "mô hình có đủ tốt không" là "liệu tôi có phải kiểm tra lại kết quả của nó so với một mô hình API không", và GPT-OSS là mô hình đầu tiên mà tôi ít phải làm điều này hơn.
Kết quả là, tôi chủ yếu sử dụng các mô hình cục bộ như một công cụ tìm kiếm Google cá nhân hóa và tốc độ cao cho các câu hỏi phát triển phần mềm không yêu cầu tính cập nhật theo thời gian thực.
Tuy nhiên, với các bản phát hành gần đây của Google trong dòng Gemma 4, tôi cuối cùng đã có thể thực hiện lập trình dạng tác nhân (agentic coding) ngay tại địa phương với độ chính xác và tốc độ đạt khoảng 75% so với các mô hình tiên phong hàng đầu (frontier models) — một con số thực sự ấn tượng.
Trải nghiệm thực tế với Gemma 4
Cho đến nay, tôi đang sử dụng gemma-4-26b-a4b trên LM Studio làm mô hình cục bộ mặc định. Tôi đã sử dụng thiết lập này để tái cấu trúc (refactor) một script Python từ dạng notebook thành một kho chứa (repo) gồm 5-6 module, và kiểm tra code (lint) để sử dụng các gợi ý kiểu (type hints) chính xác cho generics.
 Tái cấu trúc code với sự hỗ trợ của mô hình
Tái cấu trúc code với sự hỗ trợ của mô hình
Tôi cũng đã sử dụng nó để biên tập một số bài viết blog, viết các bài kiểm thử đơn vị (unit tests), và khởi tạo một repo để xây dựng mô hình two-tower cho hệ thống gợi ý chỉ để xem tác nhân AI sẽ làm gì với một trang trắng. Môi trường được giới hạn vì tôi chạy tất cả các quy trình làm việc của tác nhân trong một container Docker với quyền truy cập thực thi bị hạn chế.
Tôi cũng đang xây dựng một ứng dụng hiển thị các chủ đề xu hướng từ các bài báo trên Arxiv. Vì tò mò, tôi đã yêu cầu Pi (một công cụ AI) xem qua các nhật ký phiên LM Studio của mình để xem tôi đang sử dụng nó để làm gì:
Không có nhiệm vụ nào trong số này là mang tính đột phá (rất nhiều trong số đó chỉ là tra cứu tài liệu cá nhân hóa), nhưng việc thực hiện chúng giúp GPU và RAM của tôi hoạt động hết công suất, bộ nhớ đệm K-V tăng lên đến 64GB RAM. Tuy nhiên, câu chuyện lớn hơn đối với tôi là những loại tác vụ này, dù đơn giản đến mức nào, đã từng là bất khả thi đối với các mô hình cục bộ chỉ cách đây 6 tháng.
Mô hình Gemma-4-12b-qat vừa ra mắt gần đây và tôi cũng thực sự ấn tượng với hiệu suất của nó so với kích thước của nó. Kiến trúc của mô hình này rất thú vị và đặt ra nhiều câu hỏi hay ho, chẳng hạn như "nếu bị giới hạn về hiệu suất và giá cả, chúng ta cần phải đánh đổi kiến trúc như thế nào?" — một câu hỏi cho đến nay vẫn chưa thực sự được đặt ra trong cuộc chạy đua token điên rồ.
Thiết lập và chạy mô hình tác nhân cục bộ
Đừng chỉ nghe tôi nói, hãy tự thử nghiệm! Để chạy các quy trình tác nhân cục bộ, bạn sẽ cần một engine suy luận mô hình cục bộ, một bộ điều khiển tác nhân (agent harness), và tệp artifact của mô hình cục bộ. Bạn sẽ cần thiết lập bộ điều khiển để trỏ đến endpoint suy luận cục bộ của mình, nơi phục vụ tệp mô hình đã tải xuống thông qua engine suy luận.
Đối với thiết lập của mình, tôi hiện đang sử dụng Pi làm bộ điều khiển tác nhân và LM Studio làm máy chủ suy luận, mặc dù có lẽ sẽ nhanh hơn nếu tôi sử dụng llama.cpp trực tiếp.
Cấu hình bảo mật và Agent Harness
Vì tôi chạy mọi thứ trong Docker, tôi đã chỉnh sửa models.json của Pi để Pi có thể giao tiếp với mô hình.
"lmstudio": {
"baseUrl": "http://host.docker.internal:1234/v1",
"api": "openai-completions",
"apiKey": "not-needed",
"models": [
{
"id": "google/gemma-4-12b-qat",
"input": [
"text",
"image"
]
}
]
}
Tôi chạy mọi phiên Pi trong một container Docker và chỉ cấp quyền truy cập vào bash để nó không thể chạy mã Python hoặc duyệt web, mặc dù tôi có kế hoạch cho phép curl trong một image khác cho một số công việc nghiên cứu.
Dưới đây là cấu hình Docker Compose tóm tắt:
services:
pi:
build:
context: .
dockerfile: Dockerfile
image: pi-agent:0.74.0
init: true
stdin_open: true
tty: true
extra_hosts:
- "host.docker.internal:host-gateway"
environment:
ANTHROPIC_API_KEY: ${ANTHROPIC_API_KEY:-}
OPENAI_API_KEY: ${OPENAI_API_KEY:-not-needed}
GEMINI_API_KEY: ${GEMINI_API_KEY:-}
OPENAI_API_BASE: ${OPENAI_API_BASE:-http://host.docker.internal:1234/v1}
volumes:
- ${HOME}/.pi/agent/models.json:/config/models.json
- ${WORKSPACE:-.}:/workspace
- pi-config:/config
- pi-sessions:/sessions
working_dir: /workspace
Tôi xây dựng container Docker và thực hiện các thay đổi đối với các tệp trong repo của chính nó. Sau đó, tôi chạy Pi trong repo mà tôi đang làm việc, việc này sẽ khởi động Docker để Pi không thể xóa các tệp hoặc thư mục bằng cách tác động trực tiếp vào ổ cứng vật lý của tôi. Điều này cũng cho phép Pi đang chạy trong container nhìn thấy cấu hình mô hình json tùy chỉnh của tôi bằng cách đưa nó vào container.
Lợi ích và thách thức
Vẫn còn những vấn đề với các mô hình cục bộ: suy luận có thể chậm, cửa sổ ngữ cảnh (context windows) nhỏ và bị giới hạn bởi phần cứng của bạn, và hệ sinh thái, mặc dù đã dễ dàng hơn rất nhiều nhờ các công cụ như LM Studio và nút "Use This Model" của HuggingFace, vẫn có những khó khăn ban đầu như sự không khớp mẫu prompt (prompt template mismatches). Tuy nhiên, những vấn đề này thường được khắc phục cực kỳ nhanh chóng.
Không cần phải nói, tôi không chắc điều này đã sẵn sàng cho phát triển phần mềm sản xuất (production software development) hay chưa.
Tuy nhiên, những lợi ích mang lại là rất nhiều và hệ sinh thái này rất đáng để đầu tư, đặc biệt là vào lúc này. Một phần rất thú vị của các mô hình cục bộ là bạn có thể quan sát (introspect) hầu hết mọi thứ, từ việc xem trực tiếp quá trình suy luận token, đến việc theo dõi token vào/ra.
Bạn có thể thay đổi cửa sổ ngữ cảnh cục bộ và xem hiệu suất cải thiện hoặc suy giảm, thực sự đào sâu vào cách token của bạn được xử lý trên GPU. Bạn có thể thay đổi system prompt, các lượng tử hóa (quantizations). Bạn có thể cho các mô hình đối đầu với nhau. Bạn cũng có thể thay đổi và quan sát phía bộ điều khiển (harness).
Các khả năng là vô tận, và các công cụ chỉ ngày càng trở nên tốt hơn.
Bài viết liên quan

Phần mềm
Tấn công Cache Poisoning biến các gói npm TanStack thành mối đe dọa nguy hiểm
12 tháng 5, 2026

Phần mềm
Google ra mắt Wear OS 7: Cập nhật trực tiếp theo thời gian thực và pin "trâu" hơn
16 tháng 6, 2026
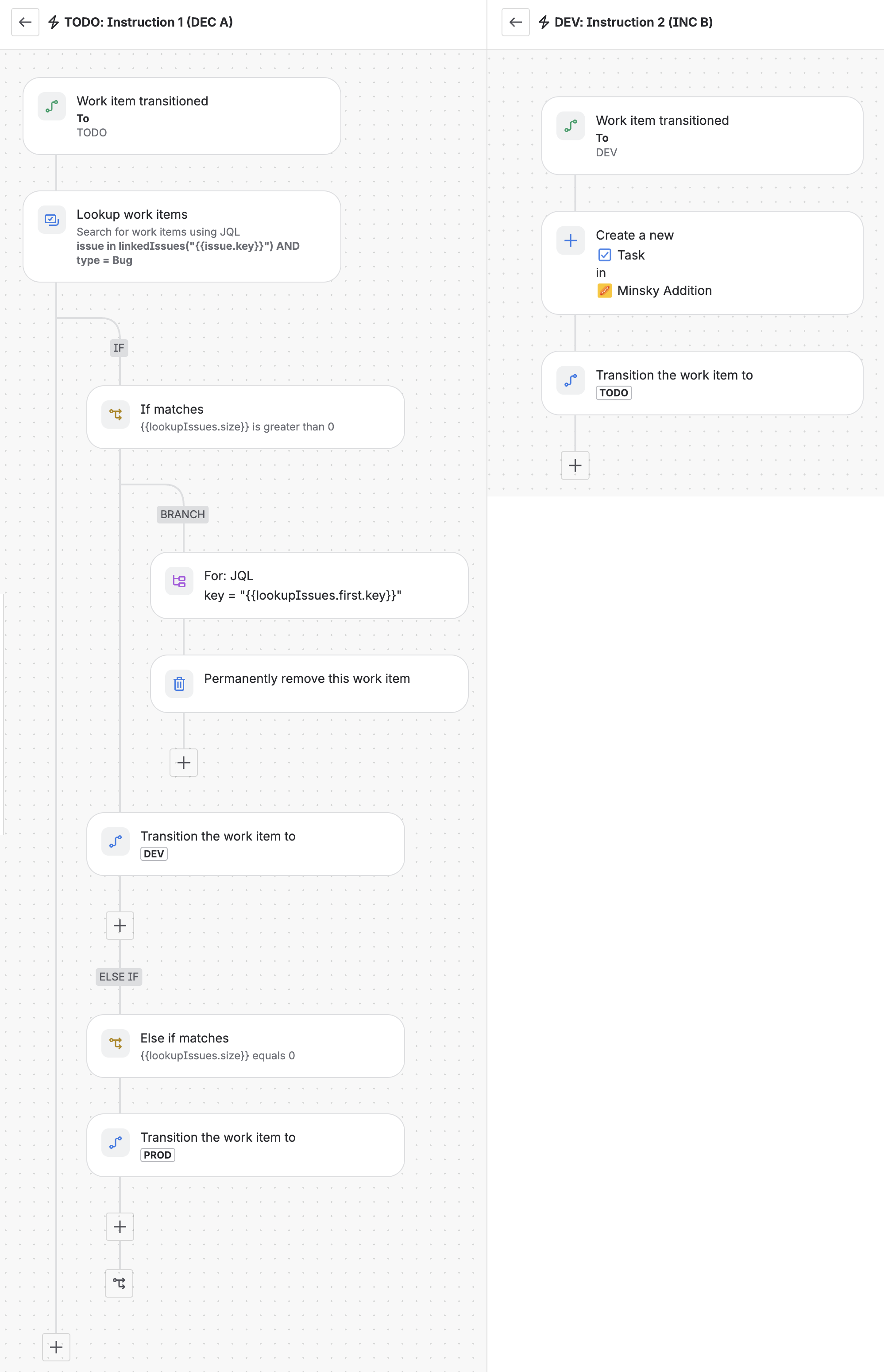
Phần mềm
Jira là Turing-Complete: Chứng minh khả năng tính toán của công cụ quản lý dự án
25 tháng 5, 2026