
Chỉ mục hóa một năm dữ liệu video ngay trên MacBook 2021 với Gemma 4-31B
Tác giả đã xây dựng một hệ thống chỉ mục hóa video cục bộ sử dụng mô hình Gemma 4 31B trên chiếc MacBook Pro M1 Max đời 2021. Hệ thống này tự động tạo siêu dữ liệu và mô tả cho hàng nghìn đoạn clip mà không cần tải lên đám mây, giải quyết bài toán kho lưu trữ video khổng lồ.

Tôi dành một nửa năm sống tại Maasai Mara, mỗi lần kéo dài ba tháng. Đó là những khoảnh khắc của thiên nhiên hoang dã, những người bạn bản địa và những đứa trẻ thấy một chiếc drone là điều thú vị nhất thế giới. Một nửa còn lại của năm là 16 giờ mỗi ngày ngồi trước màn hình terminal, với tư duy của một lập trình viên thung lũng Silicon nhưng đang sống theo giờ Châu Phi. Cả hai đều là thật, cả hai đều chiếm toàn bộ sự chú ý của tôi.
Nửa năm đầu là một dòng chảy không ngừng của những thước phim từ iPhone, DJI Pocket, drone, Nikon Z8 và gần đây là kính Ray-Ban Meta. Luôn có thứ gì đó đang được ghi lại. Mọi nhiếp ảnh gia hay quay phim mà tôi biết đều đang gặp cùng một vấn đề: kho lưu trữ phát triển nhanh hơn khả năng chỉnh sửa của họ. Và nửa năm sau là lý do tại sao kho lưu trữ của tôi chưa bao giờ được chạm tới.
Ba tháng trước, các kênh mạng xã hội của khu nghỉ dưỡng (lodge) nơi tôi làm việc "chìm vào im lặng". Không phải vì thiếu nội dung — lodge có năm năm dữ liệu thô trải dài trên nhiều ổ SSD. Nút thắt cổ chai là thời gian chỉnh sửa, và thời gian của tôi đã biến mất. Vì vậy, một cuối tuần, tôi ngồi xuống để giải quyết vấn đề này. Cái tôi thử đầu tiên đã sai.
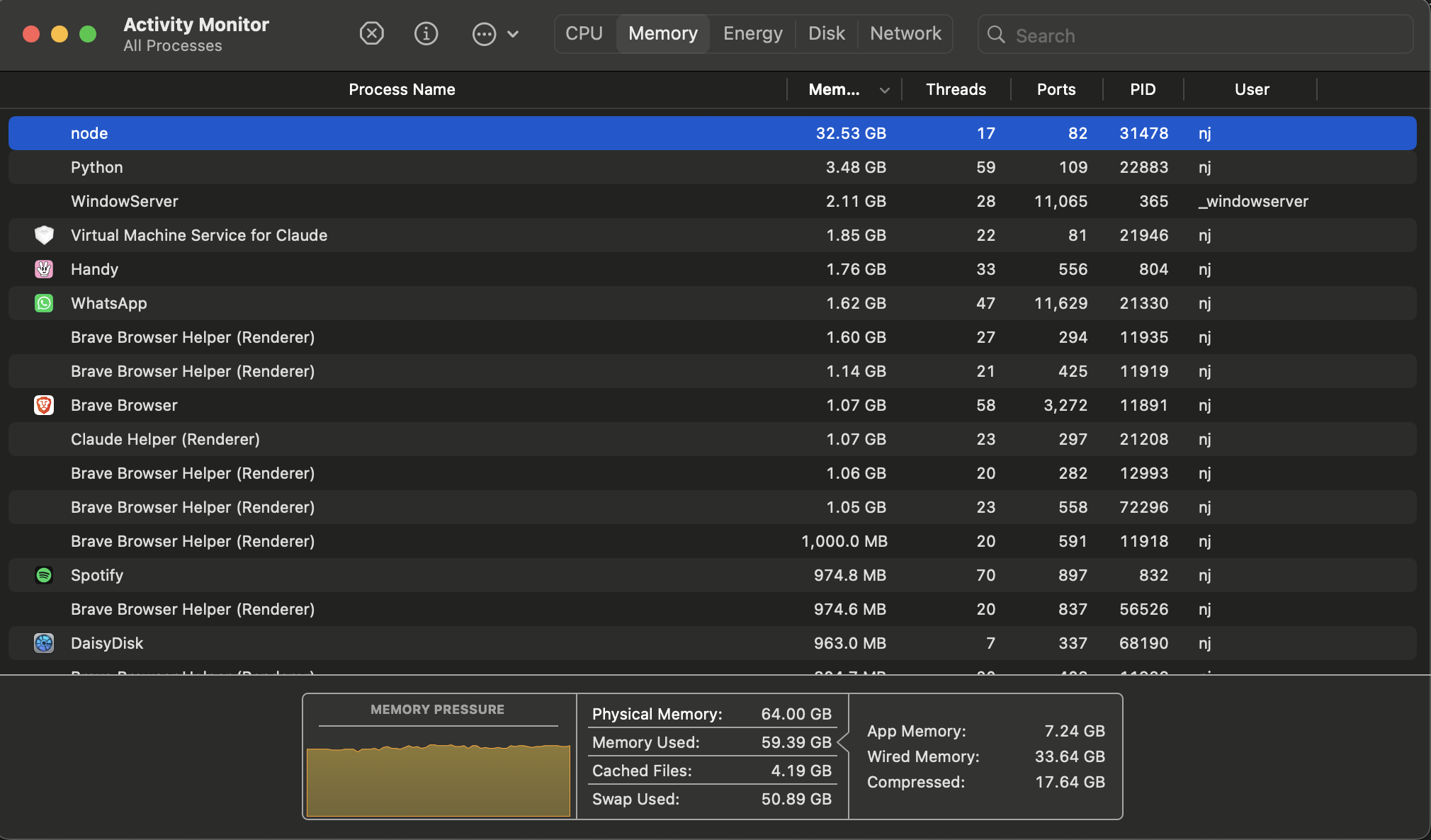 Gemma 4 31B đang chạy trên LM Studio
Gemma 4 31B đang chạy trên LM Studio
Lớp giải pháp sai lầm
Ban đầu, tôi định hướng tới một stack SaaS: Eddie AI để chỉnh sửa lặp lại, Higgsfield MCP để tạo B-roll, Submagic cho phụ đề... Tổng chi phí khoảng 140 USD/tháng. Trên giấy tờ, nó rất hào nhoáng.
Nhưng hai vấn đề đã nảy sinh ngay lập tức. Thứ nhất, video AI tạo sinh không có chỗ trong một thương hiệu du lịch thực tế. Khách hàng trả 300 USD một đêm để nhìn thấy nơi thật, và những cảnh quay AI bị dán nhãn sai sẽ dẫn đến thảm họa trên TripAdvisor. Thứ hai, tần suất đăng bài 3-5 bài/tuần là quá áp lực đối với tôi.
Sau đó, tôi nhớ ra mình đã sở hữu DaVinci Resolve Studio, và phiên bản Resolve 21 có IntelliSearch (tìm kiếm clip ngữ nghĩa), Smart Bins và Voice to Subtitle. Đó là khoảng 70% những gì Eddie bán, vì vậy Eddie cũng bị loại.
Điều còn lại là Claude Code điều khiển Resolve thông qua DaVinci Resolve MCP mã nguồn mở, với ElevenLabs xử lý lồng tiếng. Chi phí đã giảm từ 140 USD xuống còn 22 USD. Nhưng vấn đề sâu hơn vẫn nằm ở chỗ: Mọi trình chỉnh sửa video AI trên thị trường đều giả định rằng cảnh quay của bạn đã được gắn nhãn. Của tôi thì chỉ là IMG_.mov và DJI_.mp4 nằm trong các thư mục có tên kiểu "Mara june 2024 backup final FINAL".
Trình chỉnh sửa AI đang giải quyết sai vấn đề. Hoặc chính xác hơn, nó đang giải quyết vấn đề thứ hai; vấn đề đầu tiên là chỉ mục.
Câu hỏi lớn
Tôi đã tự hỏi: Làm thế nào tác nhân (agent) biết được nội dung của mỗi clip?
Không có câu trả lời cho một kho lưu trữ chưa được gắn nhãn. Bạn có thể ném bản ghi âm, tọa độ GPS, tên tệp vào đó, nhưng không cái nào cho bạn biết "cảnh quay rộng lúc bình minh với hươu cao cổ trong khung hình" trừ khi có thứ gì đó thực sự nhìn vào các điểm ảnh.
Đòn bẩy nằm ở thượng nguồn. Hãy xây dựng chỉ mục trước, biến kho lưu trữ thành thứ có thể truy vấn bằng tiếng Anh, và trình chỉnh sửa ở trên sẽ trở thành một lớp mỏng thực hiện đúng nhiệm vụ của nó.
Vì vậy, tôi đã xây dựng chỉ mục, hoàn toàn cục bộ (local).
Quy trình xây dựng
Tôi đặt ra bốn ràng buộc:
- Ưu tiên cục bộ (Local-first): Dữ liệu trên SSD vật lý, không tải lên đám mây vì chi phí và quyền riêng tư.
- Sử dụng file sidecar, không phải cơ sở dữ liệu trung tâm: Một file .description.md đi kèm mỗi clip, dạng văn bản thuần.
- Một cuộc gọi vision (thị giác) nắm bắt tất cả: Mọi thứ tôi muốn biết sau này đều phải lấy từ một lần gọi vision tốn kém này.
- Ba backend thị giác: Claude CLI, Anthropic API và một backend cục bộ chạy LM Studio. Backend cục bộ là quan trọng nhất.
Quy trình cho mỗi clip bao gồm: ffprobe để lấy metadata, exiftool để lấy GPS, ffmpeg để trích xuất khung hình, WhisperX để chuyển đổi giọng nói thành văn bản, insightface để nhận diện khuôn mặt, và cuối cùng là mô hình Vision đọc khung hình để trả về YAML frontmatter và mô tả văn bản.
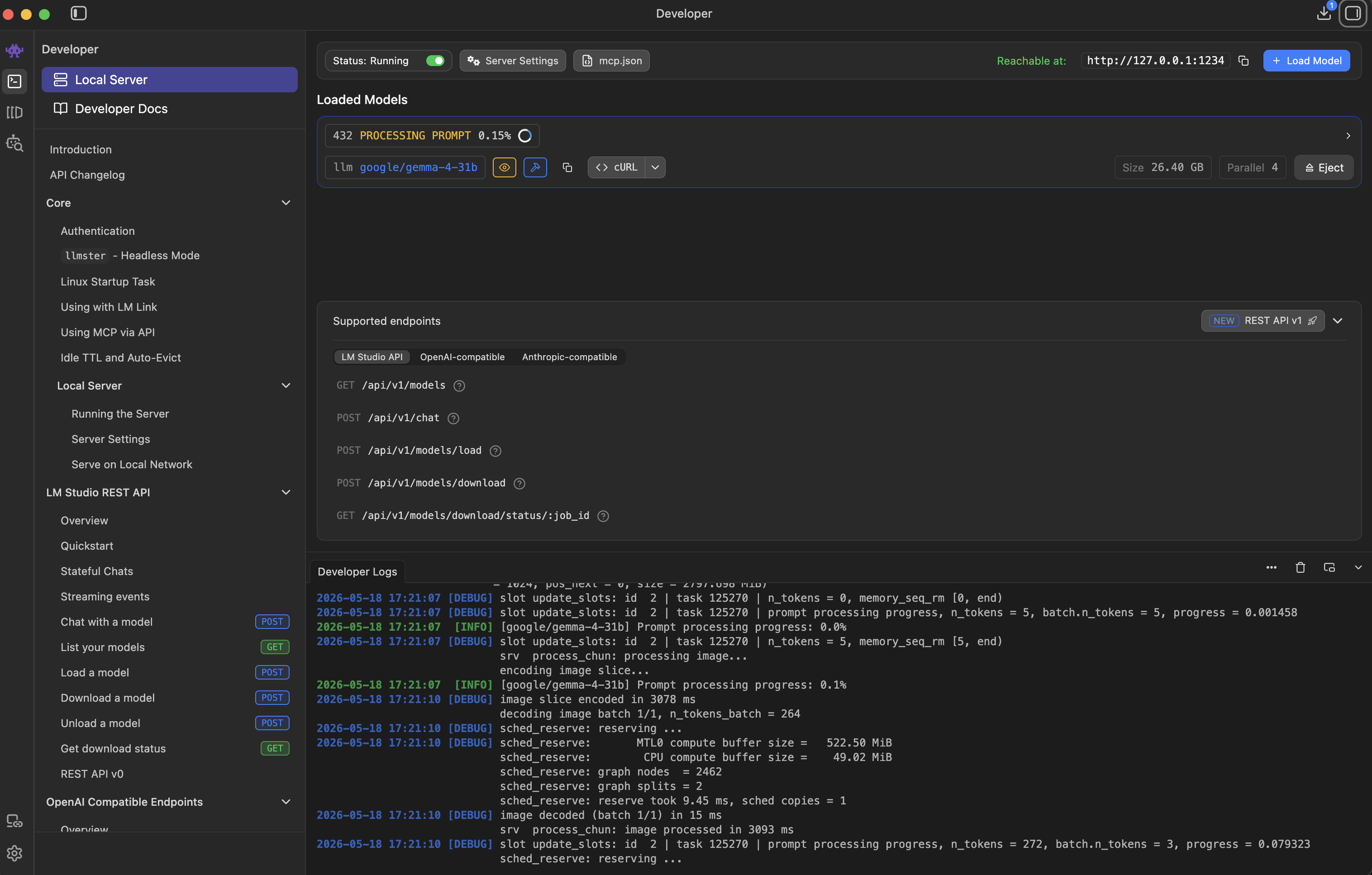 Màn hình Activity Monitor cho thấy việc sử dụng RAM và Swap
Màn hình Activity Monitor cho thấy việc sử dụng RAM và Swap
Sự phi lý của phần cứng
Đây là phần thực sự gây ngạc nhiên cho tôi. Tôi đã mua MacBook Pro M1 Max 16 inch với 64GB RAM vào năm 2021. Lý do lúc đó hoàn toàn không liên quan đến LLM. Năm năm sau, chiếc laptop cùng đang chạy mô hình Gemma 4 31B Q4 trong LM Studio để xử lý một năm dữ liệu video.
Quá trình chạy hàng loạt đã đẩy laptop vượt quá giới hạn 64GB RAM. Activity Monitor báo cáo việc sử dụng swap lên tới 50,89 GB tại đỉnh điểm. Tôi đã tìm hiểu xem điều này có làm hỏng SSD không, và dường như trong một hoặc hai ngày thì vẫn ổn. Quạt máy quay rất to, máy chạy nóng, nhưng nó vẫn tiếp tục sản xuất các file sidecar trong khi tôi làm việc khác.
M1 Max 16 inch thực sự huyền thoại. Năm năm sau, nó vẫn chạy các mô hình 31 tỷ tham số ở tốc độ sử dụng được với phần dư dự phòng mà lẽ ra không nên tồn tại trên phần cứng cũ kỹ này. Tôi kỳ vọng nó sẽ dùng thêm được 3-5 năm nữa.
Bốn lỗi và bốn bài học
Quá trình xây dựng chủ yếu do Claude Code thực hiện, nhưng có 4 lần nó gần như xuất bản sai thứ gì đó:
- WhisperX thay đổi API: Thư viện này thay đổi cách gọi diarization (phân vùng loa). Bài học: Khi gọi các thư viện AI thay đổi nhanh, các lệnh gọi hàm phòng thủ là bảo hiểm rẻ.
- Lỗi quyền của Claude CLI: Trong chế độ không tương tác, CLI trả về văn bản từ chối quyền truy cập thay vì báo lỗi, khiến script tưởng rằng thành công. Bài học: Luôn kiểm tra kỹ các lỗi "im lặng" trong luồng quyền.
- Gemma trả về chuỗi thay vì số nguyên: Mô hình trả về "many" thay vì số lượng người. Bài học: Đừng dùng kiểu union (số hoặc chuỗi) cho schema. Hãy chọn luôn số hoặc luôn chuỗi.
- Loại bỏ nhầm đoạn clip xe máy: Tiêu chí ban đầu quá khắt khe về độ mờ và rung, khiến nó loại bỏ một đoạn kỷ niệm vui về đêm. Bài học: Kho ảnh loại bỏ thẳng tay, nhưng video kỷ niệm cần loại bỏ nương nhẹ.
Kết luận và hướng đi
Ba điều tôi tin mạnh mẽ hơn một tuần trước:
- Ràng buộc Enum tốt hơn hướng dẫn: Mô hình có thể bịa ra trong văn bản, nhưng nếu bắt buộc chọn từ một danh sách liệt kê (enum), nó không thể tự tạo ra giá trị mới.
- Local 31B với prompt có cấu trúc thu hẹp khoảng cách với Cloud: Gemma 4 31B Q4 tạo ra kết quả khó phân biệt với Sonnet 4.6 trên hầu hết các đoạn clip thử nghiệm.
- Trình chỉnh sửa video AI đang nhắm sai tầng: Tầng có giá trị thực sự là chỉ mục. Khi kho lưu trữ có thể truy vấn bằng tiếng Anh, trình chỉnh sửa ở trên trở nên đơn giản.
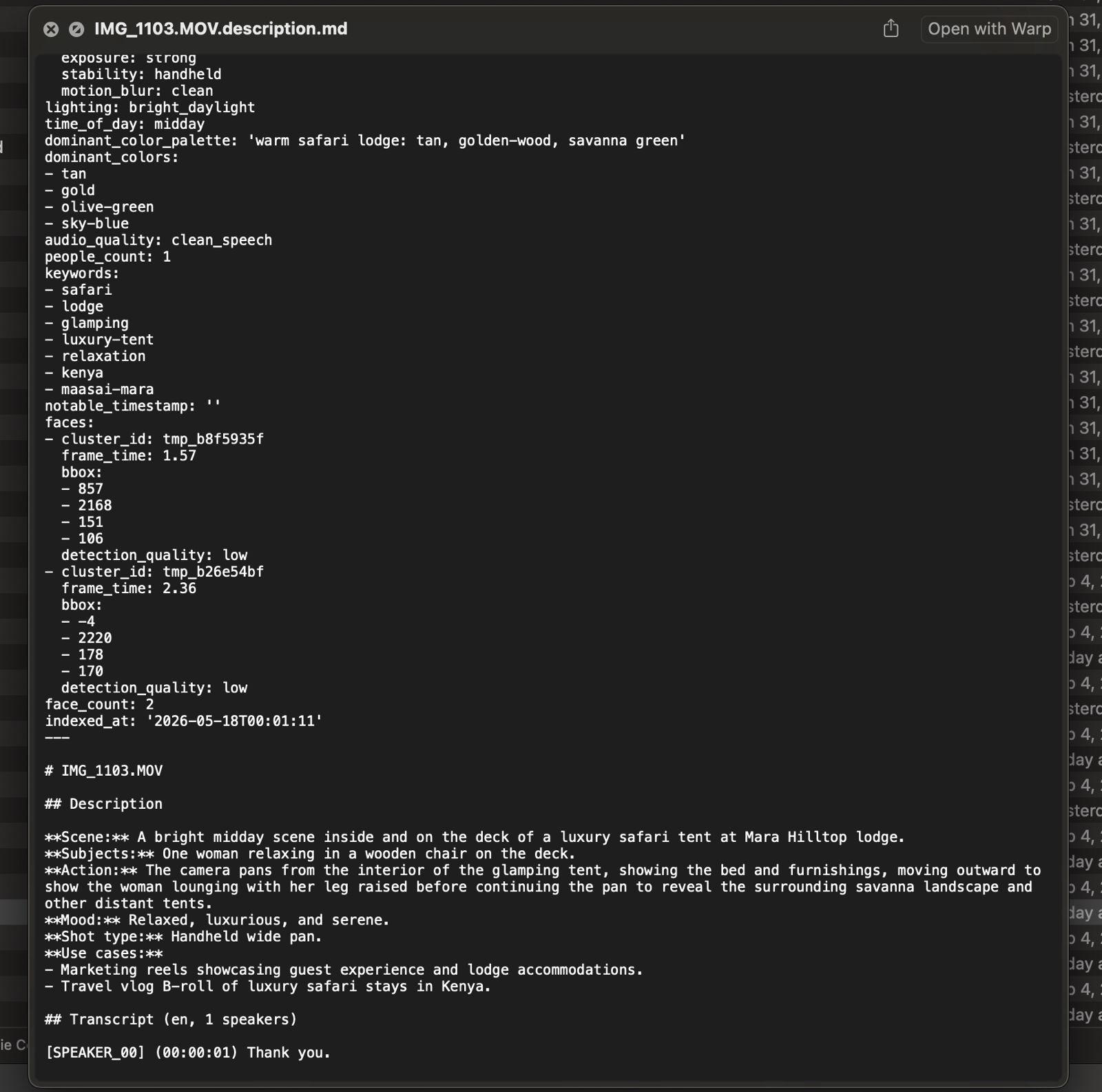 Ví dụ về file sidecar được tạo ra tự động
Ví dụ về file sidecar được tạo ra tự động
Hiện tại, một năm dữ liệu video của Mara Hilltop đã có thể truy vấn bằng tiếng Anh trên một chiếc laptop năm năm tuổi. Chi phí là một cuối tuần thời gian và 50GB swap. Các năm dữ liệu còn lại trên các ổ SSD cũ hơn là mục tiêu tiếp theo.
Chỉ mục làm cho mọi thứ trở nên khả thi. Nếu không có nó, tôi vẫn sẽ đang lướt qua 47GB footage của DJI Pocket để tìm kiếm cảnh bình minh rộng. Nếu bạn đang làm việc trên một dự án tương tự (chỉ mục hóa kho lưu trữ cá nhân, chạy mô hình cục bộ), tôi rất sẵn lòng trao đổi kinh nghiệm.
Bài viết liên quan

Phần mềm
Tối ưu hóa hệ thống gợi ý bằng LLM và Python: Cách cân bằng giữa tốc độ và độ chính xác
08 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026

Công nghệ
Amazon ra mắt tính năng Sleep Studio giúp trẻ em đi ngủ dễ dàng hơn trên loa Echo
10 tháng 6, 2026