
Deep Evidential Regression: Khi mạng nơ-ron học cách thừa nhận "tôi không biết"
Các mô hình học máy thường quá tự tin, ngay cả khi gặp dữ liệu lạ. Bài viết giới thiệu Deep Evidential Regression (DER), một phương pháp giúp mạng nơ-ron biểu thị độ bất định một cách nhanh chóng và hiệu quả.

Deep Evidential Regression (DER) là một chủ đề thú vị đang phát triển trong lĩnh vực trí tuệ nhân tạo, tập trung vào việc giải quyết một vấn đề cốt lõi của các mô hình học máy hiện đại: sự tự tin thái quá.
Trong bài viết này, chúng ta sẽ khám phá khái niệm Evidential Deep Learning (EDL) và cụ thể là DER, một phương pháp cho phép các mạng nơ-ron không chỉ đưa ra dự đoán mà còn biểu thị được mức độ "chắc chắn" hoặc "không chắc chắn" của mình trong một lần tính toán duy nhất (one-shot).
Độ bất định là gì và tại sao nó lại quan trọng?
Việc ra quyết định là một quá trình phức tạp. Con người thường sử dụng trực giác, mà thực chất là một cách biểu thị ngược lại của sự không chắc chắn (uncertainty). Trong y khoa hay các lĩnh vực kỹ thuật cao, việc đánh giá rủi ro là cực kỳ quan trọng.
Tuy nhiên, đối với máy móc, điều này không hề đơn giản. Các thuật toán Học sâu (Deep Learning) thường được triển khai để tự động hóa việc ra quyết định. Một vấn đề lớn nằm ở lớp cuối cùng của hầu hết các mô hình phân loại, nơi hàm Softmax được sử dụng.
Nhiều người lầm tưởng rằng đầu ra của Softmax là xác suất thể hiện độ tin cậy của mô hình. Nhưng thực tế không phải vậy. Hãy tưởng tượng một mô hình chỉ được huấn luyện với dữ liệu về "chó đen" và "mèo trắng". Nếu nó gặp một "chó trắng", mô hình vẫn buộc phải đưa ra một phân loại dựa trên những gì nó đã biết, mà không có cơ chế nào để báo hiệu rằng nó đang gặp một dữ liệu lạ (Out-of-distribution - OOD).
Các nhà nghiên cứu thường chia độ bất định thành hai loại chính:
- Epistemic (Độ bất định tri thức): Xuất phát từ việc thiếu dữ liệu hoặc kiến thức về dữ liệu. Ví dụ: mô hình chưa từng thấy vùng dữ liệu nào đó.
- Aleatoric (Độ bất định ngẫu nhiên): Xuất phát từ bản chất ồn ào (noise) của chính dữ liệu. Ví dụ: cảm biến đo lường có độ sai số nhất định.
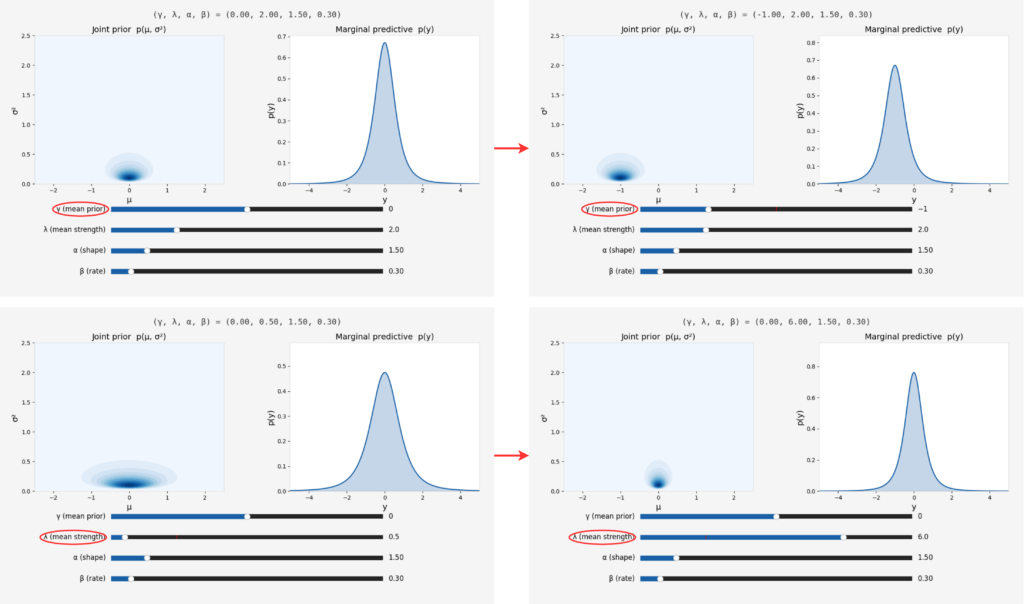 Hiệu quả của việc điều chỉnh các tham số trong phân phối
Hiệu quả của việc điều chỉnh các tham số trong phân phối
Các phương pháp định lượng độ bất định truyền thống
Trước khi đi vào DER, hãy nhìn nhanh các phương pháp hiện có. Các kỹ thuật như Deep Ensembles (huấn luyện nhiều mô hình độc lập), Variational Inference (cho các mạng nơ-ron Bayesian) hay Conformal Prediction đều có thể định lượng độ bất định.
Tuy nhiên, điểm chung của chúng là tính toán rất tốn kém. Chúng thường yêu cầu nhiều lần truyền dữ liệu (forward passes) trong quá trình suy luận hoặc các bước hiệu chuẩn (calibration) phức tạp sau khi huấn luyện.
Lý thuyết về Deep Evidential Regression
DER ra đời để giải quyết vấn đề hiệu năng này. Thay vì huấn luyện nhiều mô hình hay thực hiện các phép tính phức tạp, DER huấn luyện một mô hình duy nhất để xuất ra các tham số của một phân phối xác suất bậc cao hơn.
Cụ thể, trong DER, chúng ta mô hình hóa một trung bình không biết $\mu$ và phương sai không biết $\sigma^2$. Chúng ta giả định rằng các tham số này được phân phối theo một cách nhất định. Để làm điều này, DER dự đoán các tham số của phân phối Normal Inverse Gamma (NIG) cho mỗi mẫu dữ liệu.
Phân phối NIG là tích lũy xác suất giữa phân phối Chuẩn (Normal) và phân phối Inverse Gamma. Nó được định nghĩa bởi 4 tham số: $\gamma, \lambda, \alpha, \beta$.
- $\gamma, \lambda$: Mô tả trung bình kỳ vọng và độ масштаб của nó.
- $\alpha, \beta$: Mô tả hình dạng và độ масштаб của phương sai.
Từ các tham số này, chúng ta có thể tính toán độ bất định Epistemic và Aleatoric ngay lập tức mà không cần lấy mẫu nhiều lần.
Ví dụ thực tế: Xấp xỉ hàm khối (Cubic Function)
Để minh họa, hãy xem xét ví dụ từ bài báo gốc về việc ước lượng hàm khối $y = x^3$. Mạng nơ-ron được cung cấp dữ liệu huấn luyện giới hạn trong khoảng $[-4, 4]$ và có thêm nhiễu (noise).
Mục tiêu là xem mô hình hoạt động như thế nào khi dự đoán các giá trị nằm ngoài khoảng huấn luyện này (ví dụ: $x = 6$ hoặc $x = -6$).
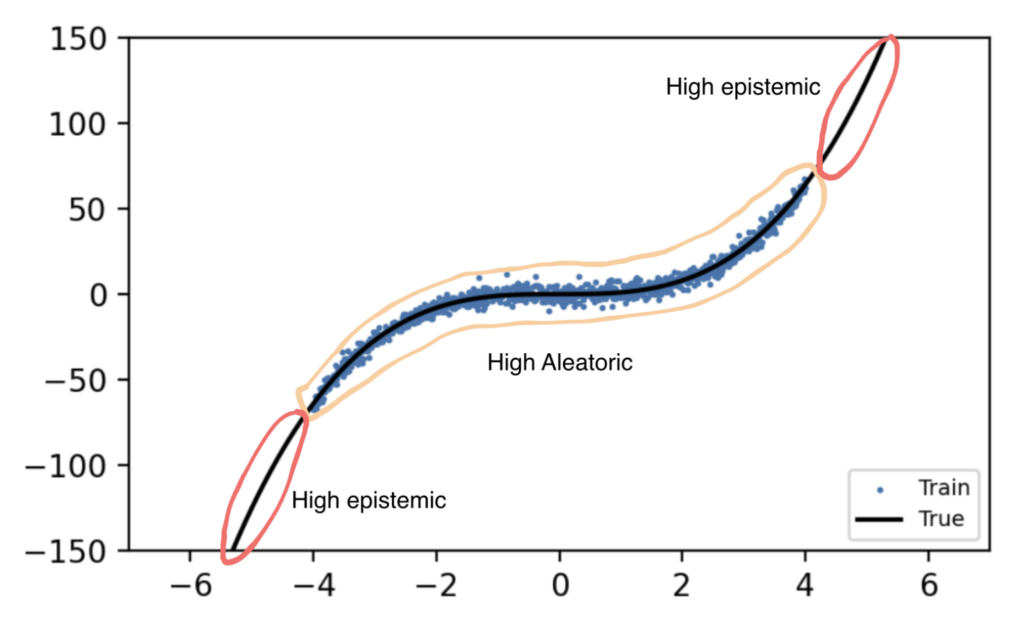 Kết quả dự đoán của DER trên hàm khối
Kết quả dự đoán của DER trên hàm khối
Kết quả cho thấy DER hoạt động rất ấn tượng. Trong vùng dữ liệu đã huấn luyện (giữa khoảng $[-4, 4]$), độ bất định tổng thể thấp. Tuy nhiên, khi đi ra khỏi vùng này, vùng dự đoán (màu xanh lá) mở rộng ra đáng kể, cho thấy độ bất định tăng cao. Điều này có nghĩa là mô hình "thừa nhận" rằng nó không biết gì về những vùng dữ liệu đó.
Triển khai và Thách thức
Việc triển khai DER thực sự khá đơn giản. Chúng ta chỉ cần một lớp tuyến tính xuất ra 4 tham số cho mỗi chiều đầu ra và áp dụng hàm kích hoạt softplus để đảm bảo các tham số này dương.
Tuy nhiên, DER không phải là một giải pháp hoàn hảo. Nó có những thách thức riêng:
- Tối ưu hóa khó khăn: Hàm mất mát (loss function) là sự kết hợp giữa Negative Log Likelihood và một số hạng điều chuẩn (regularization). Việc cân bằng siêu tham số điều chỉnh này rất nhạy cảm.
- Tách biệt độ bất định: Đôi khi việc tách biệt hoàn toàn độ bất định Epistemic và Aleatoric vẫn còn khó khăn.
Kết luận
Deep Evidential Regression là một khung lý thuyết mới nổi và đầy hứa hẹn cho việc định lượng độ bất định. Nó cho phép các mạng nơ-ron học cách nói "tôi không biết" một cách hiệu quả.
Những ưu điểm chính bao gồm tốc độ huấn luyện và suy luận cực nhanh so với các phương pháp Bayesian truyền thống, cùng với cách biểu diễn nhỏ gọn. Mặc dù vẫn còn những thách thức về tối ưu hóa, đây chắc chắn là một lĩnh vực mà những người làm công nghệ và AI cần theo dõi sát sao trong tương lai.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026