
DiffusionGemma: Mô hình AI tạo văn bản nhanh hơn 4 lần nhờ kỹ thuật Diffusion
Google vừa công bố DiffusionGemma, một mô hình ngôn ngữ thử nghiệm áp dụng kỹ thuật khuếch tán (diffusion) để tạo văn bản theo khối thay vì tuần tự. Với khả năng suy luận nhanh gấp 4 lần trên GPU chuyên dụng, mô hình này mở ra cơ hội cho các ứng dụng AI tương tác thời gian thực ngay trên máy cá nhân.

DiffusionGemma: Mô hình AI tạo văn bản nhanh hơn 4 lần nhờ kỹ thuật Diffusion
Google vừa giới thiệu DiffusionGemma, một mô hình ngôn ngữ mở (open model) mang tính thử nghiệm, khám phá khả năng tạo văn bản thông qua kỹ thuật khuếch tán (text diffusion) — một phương pháp tiếp cận mang lại tốc độ xử lý vượt trội. Được phát hành theo giấy phép Apache 2.0, mô hình này là một phiên bản Mixture of Experts (MoE) với 26 tỷ tham số, phá vỡ giới hạn của việc xử lý tuần tự token-by-token vốn đặc trưng của các Mô hình Ngôn ngữ Lớn (LLM) tự hồi quy truyền thống. Thay vào đó, DiffusionGemma tạo ra các khối văn bản hoàn chỉnh cùng một lúc, mang lại tốc độ tạo văn bản nhanh hơn gấp 4 lần trên các GPU chuyên dụng.
 Biểu đồ so sánh hiệu suất
Biểu đồ so sánh hiệu suất
Tốc độ suy luận vượt trội cho các tác vụ thời gian thực
DiffusionGemma được xây dựng dựa trên nền tảng trí tuệ nhân tạo của dòng Gemma 4 và các nghiên cứu tiên tiến về Gemini Diffusion. Mô hình tích hợp một "diffusion head" mới được thiết kế để tối đa hóa tốc độ tạo nội dung. Trong khi các mô hình Gemma 4 tự hồi quy vẫn là tiêu chuẩn vàng cho các đầu ra chất lượng cao trong môi trường sản xuất, DiffusionGemma nhắm đến đối tượng là các nhà nghiên cứu và nhà phát triển đang tìm kiếm các quy trình làm việc cục bộ (local workflows) đòi hỏi tốc độ cao và tính tương tác, chẳng hạn như chỉnh sửa văn bản trực tiếp (in-line editing), lặp lại nhanh chóng hoặc tạo cấu trúc văn bản phi tuyến tính.
Điểm mạnh lớn nhất của DiffusionGemma nằm ở việc giải quyết các nút thắt độ trễ (latency bottlenecks) thường gặp khi suy luận AI cục bộ. Bằng cách chuyển nút thắt giải mã từ băng thông bộ nhớ sang sức mạnh tính toán, mô hình này có thể tạo ra hơn 1000 token mỗi giây trên một NVIDIA H100 và hơn 700 token mỗi giây trên NVIDIA GeForce RTX 5090.
 So sánh Trí tuệ và Độ trễ
So sánh Trí tuệ và Độ trễ
Tối ưu hóa phần cứng và cơ chế hoạt động mới
Về mặt phần cứng, DiffusionGemma hoạt động như một mô hình MoE 26B tham số nhưng chỉ kích hoạt 3.8B tham số trong quá trình suy luận. Điều này giúp mô hình hoạt động thoải mái trong giới hạn VRAM 18GB của các GPU tiêu dùng cao cấp khi được định lượng (quantized), giúp các nhà phát triển có thể chạy mô hình mạnh mẽ ngay trên máy tính của mình mà không cần hạ tầng đám mây khổng lồ.
Khác với các mô hình ngôn ngữ truyền thống hoạt động giống như một chiếc máy đánh chữ — tạo ra từng từ một từ trái sang phải — DiffusionGemma hoạt động giống như một máy in khối lớn. Nó soạn thảo cả một đoạn văn bản gồm 256 token cùng một lúc. Bằng cách cung cấp cho bộ xử lý một khối công việc lớn hơn, DiffusionGemma tận dụng tối đa phần cứng của bạn.
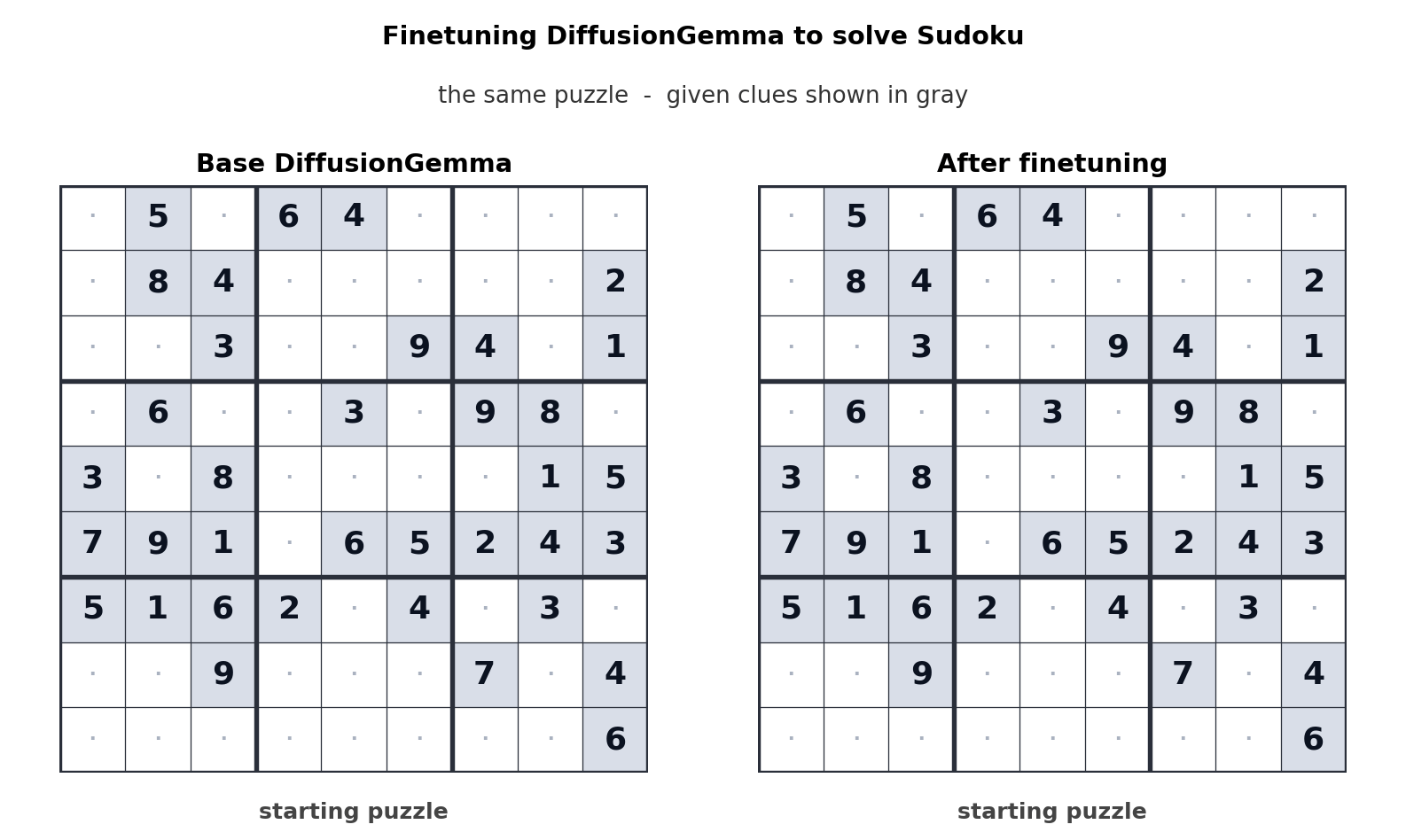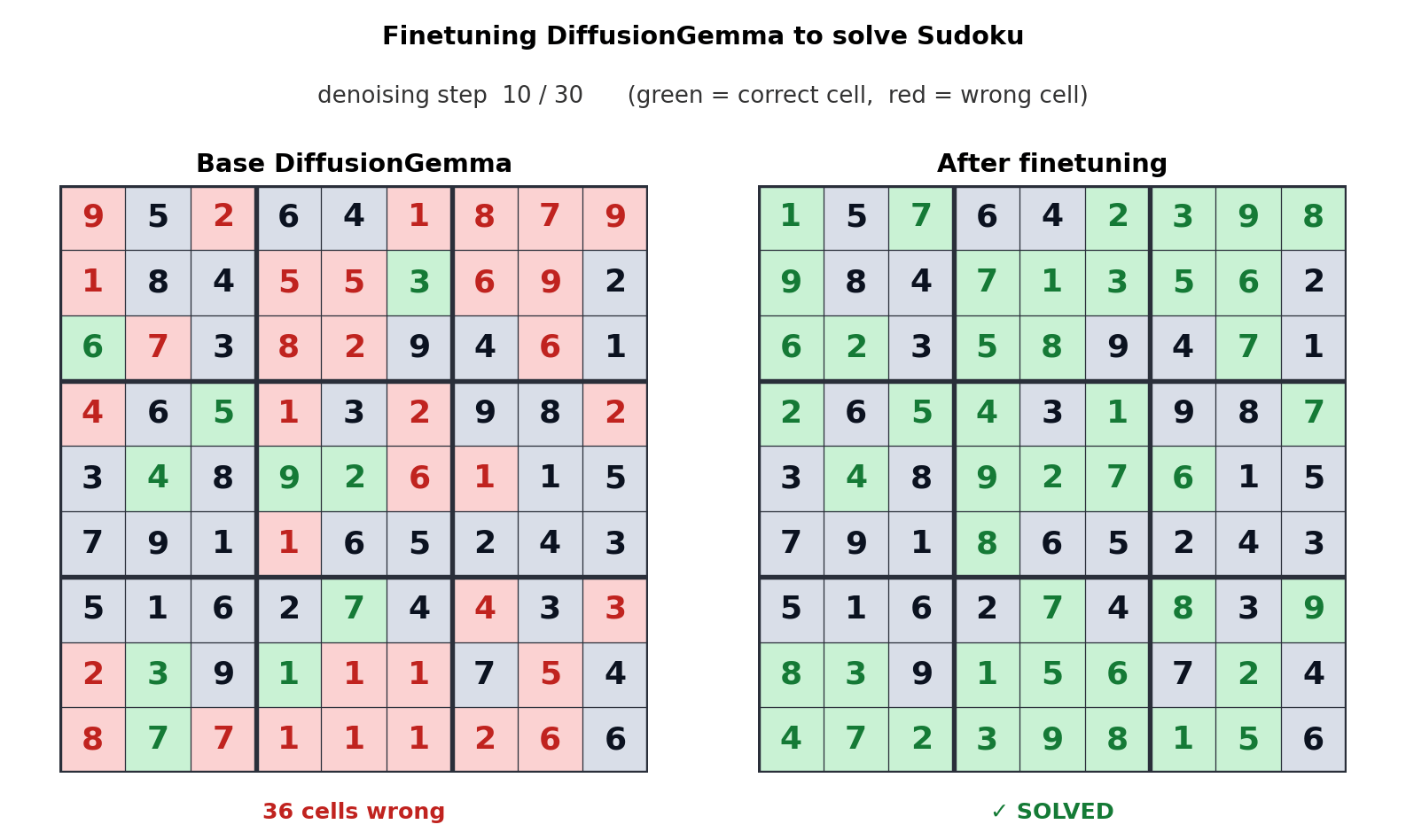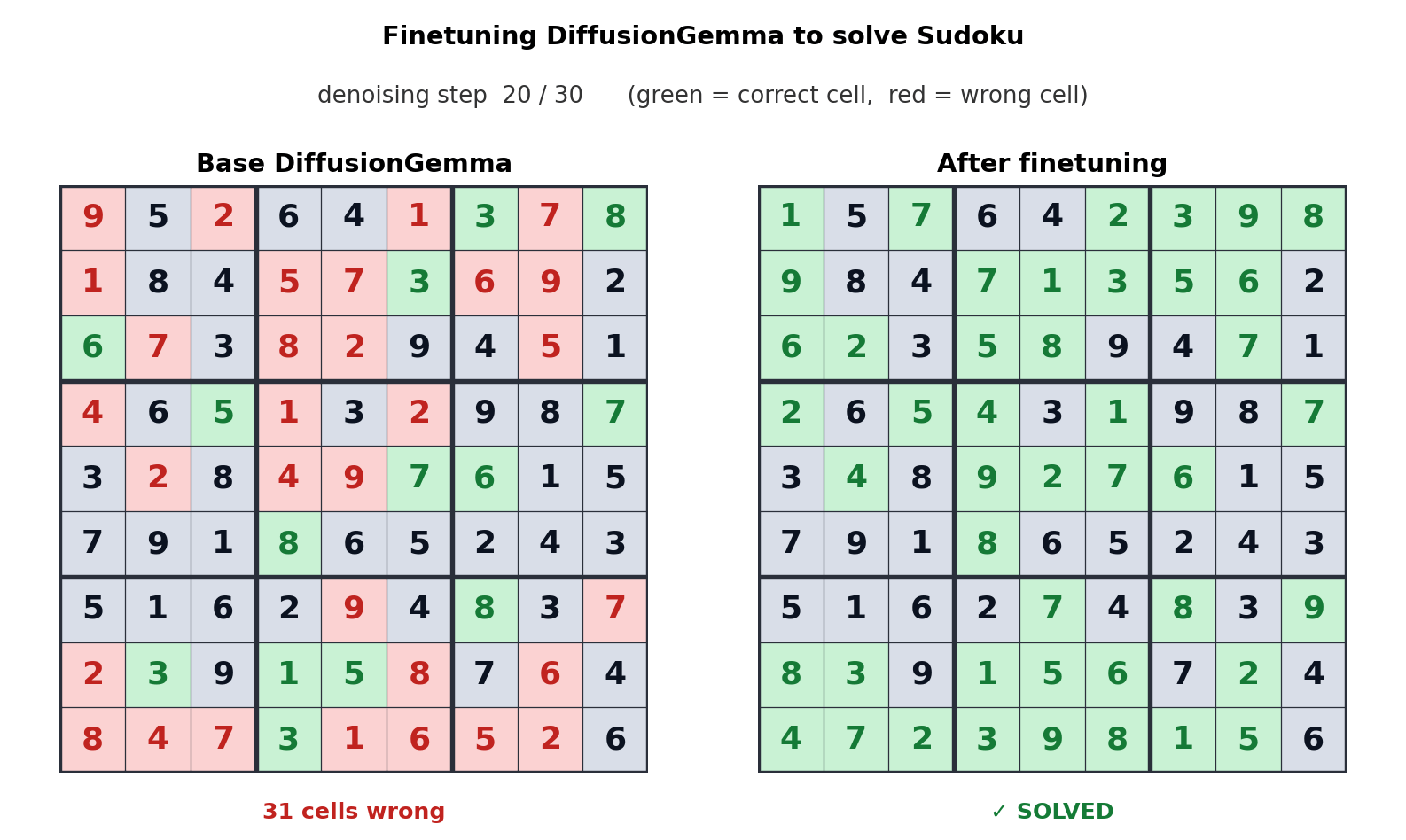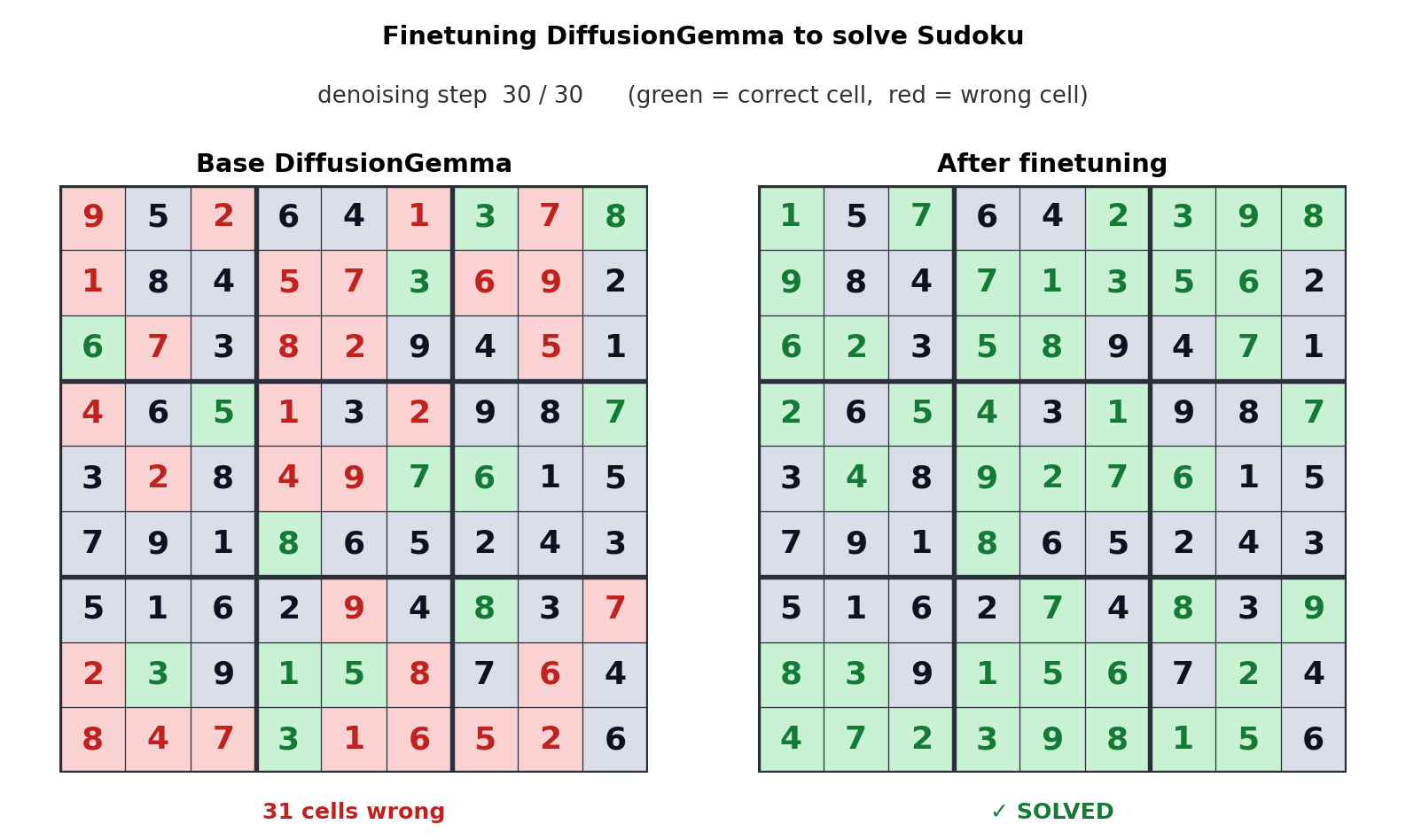 DiffusionGemma giải quyết Sudoku
DiffusionGemma giải quyết Sudoku
Cơ chế chú ý hai chiều (bi-directional attention) cho phép mỗi token trong 256 token được tạo song song có thể "chú ý" đến tất cả các token khác. Điều này mang lại lợi thế to lớn cho các lĩnh vực phi tuyến tính như chỉnh sửa mã nguồn (code infilling), trình tự axit amin hoặc các đồ thị toán học. Ví dụ, khi được tinh chỉnh (fine-tuned) để chơi Sudoku, DiffusionGemma thể hiện khả năng vượt trội so với các mô hình tự hồi quy nhờ khả năng nhìn thấy toàn bộ bảng toán cùng lúc.
Hiệu suất và khuyến nghị sử dụng
Tuy nhiên, người dùng cần lưu ý rằng DiffusionGemma là một mô hình thử nghiệm và có sự đánh đổi. Do ưu tiên tốc độ và tạo bố cục song song, chất lượng đầu ra tổng thể của DiffusionGemma thấp hơn so với tiêu chuẩn Gemma 4. Google khuyến nghị triển khai Gemma 4 tiêu chuẩn cho các ứng dụng yêu cầu chất lượng cao nhất.
Mô hình này tự động sửa lỗi thông qua quá trình tinh chỉnh lặp lại, cho phép nó đánh giá toàn bộ khối văn bản một lúc để sửa lỗi theo thời gian thực. Hiệu suất của DiffusionGemma được tối ưu hóa tốt nhất cho suy luận cục bộ và có độ trễ thấp (low-concurrency). Trong môi trường đám mây với QPS cao, các mô hình tự hồi quy vẫn hiệu quả hơn.
Bắt đầu với DiffusionGemma
Các nhà phát triển có thể tải xuống trọng số mô hình thử nghiệm (giấy phép Apache 2.0) ngay bây giờ trên Hugging Face. Google cũng cung cấp hướng dẫn dành cho nhà phát triển và các công cụ để phục vụ mô hình hiệu quả bằng MLX, vLLM và Hugging Face Transformers.
Để thử nghiệm nhanh, có các hướng dẫn tinh chỉnh sử dụng Hackable Diffusion, Unsloth và NVIDIA NeMo. Google cũng đã hợp tác với NVIDIA để tối ưu hóa trên toàn bộ ngăn xếp phần cứng của họ, đảm bảo tính tương thích với các thiết lập tiêu dùng (GPU GeForce RTX 5090 và 4090) cũng như các hệ thống doanh nghiệp (Hopper và Blackwell).