
Docling: Giải pháp phân tích PDF cục bộ cho RAG, bảo mật và không cần đám mây
Docling là công cụ mã nguồn mở của IBM giúp phân tích tài liệu PDF phức tạp (bảng, hình ảnh, OCR) ngay trên máy chủ riêng. Nó giải quyết vấn đề bảo mật dữ liệu doanh nghiệp mà không cần tải tài liệu lên đám mây như các dịch vụ trả phí khác.

Docling: Giải pháp phân tích PDF cục bộ cho RAG, bảo mật và không cần đám mây
Trong chuỗi bài xây dựng hệ thống RAG (Retrieval-Augmented Generation) cấp doanh nghiệp, việc phân tích tài liệu PDF đóng vai trò nền tảng. Bài viết trước đây đã giới thiệu cách sử dụng PyMuPDF (fitz) và Azure Document Intelligence. Tuy nhiên, khi đối mặt với các tài liệu mật hoặc môi trường mạng cách ly (air-gapped), việc tải dữ liệu lên đám mây là điều không thể. Đây chính là lúc Docling — công cụ mã nguồn mở của IBM Research — trở thành giải pháp thay thế hoàn hảo.
 So sánh các phương pháp phân tích tài liệu
So sánh các phương pháp phân tích tài liệu
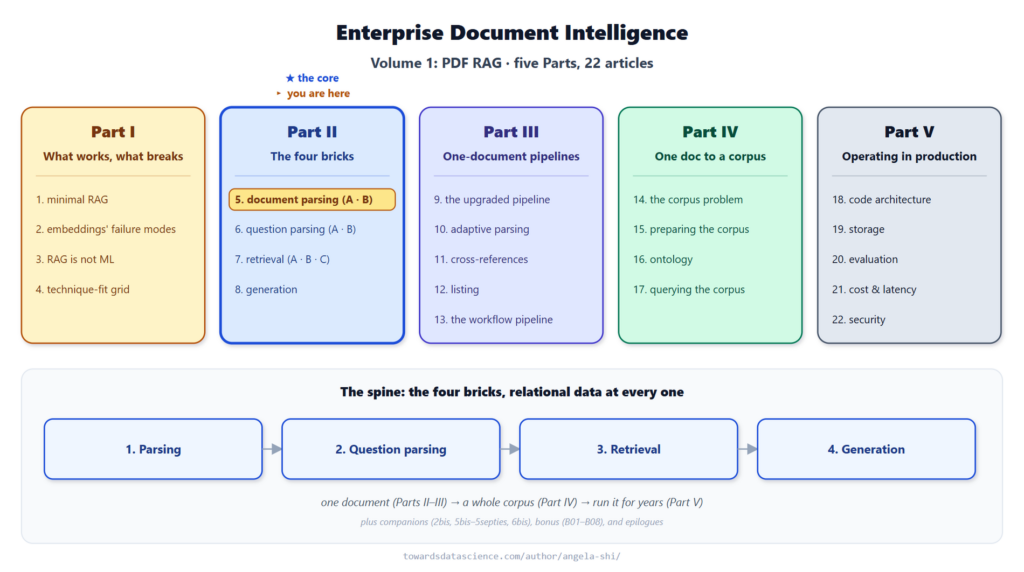
Docling cung cấp khả năng phân tích tài liệu sâu sắc (nhận diện bố cục, bảng biểu, OCR) nhưng chạy hoàn toàn trên máy của bạn (local). Không cần API key, không tính phí theo trang, và quan trọng nhất là dữ liệu không bao giờ rời khỏi cơ sở hạ tầng của bạn.
Tại sao việc xử lý cục bộ lại là rào cản?
Các trình phân tích tài liệu mạnh mẽ nhất hiện nay thường là các dịch vụ đám mây quản lý (managed cloud services). Chúng yêu cầu bạn gửi dữ liệu đi để nhận lại cấu trúc có sẵn. Điều này hoạt động tốt với các bài báo khoa học công khai, nhưng lại là "vùng cấm" đối với nhiều doanh nghiệp vì các lý do sau:
- Tính bảo mật: Hợp đồng bảo hiểm, hồ sơ y tế, dữ liệu M&A hoặc thỏa thuận nhân sự chứa dữ liệu cá nhân. Phòng pháp chế thường không cho phép các byte dữ liệu này rời khỏi tòa nhà, chưa nói đến việc vượt biên giới sang đám mây của bên thứ ba.
- Quy định lưu trữ dữ liệu (Data Residency): Nhiều ngành công nghiệp yêu cầu dữ liệu phải nằm trong một khu vực địa lý cụ thể. Một trình phân tích trên đám mây ở khu vực sai có thể vi phạm hợp đồng.
- Môi trường cách ly: Một số mạng nội bộ không có kết nối Internet ra ngoài. Lời gọi API đám mây lúc đó không chỉ là chậm, mà là bất khả thi.
- Chi phí ở quy mô lớn: Vài xu cho mỗi trang không đáng kể với hàng nghìn trang, nhưng lại thành một khoản chi phí lớn khi xử lý hàng triệu trang.
Docling giải quyết cả bốn vấn đề trên bằng cách chạy mô hình ngay tại nơi dữ liệu đang lưu trữ. Sự đánh đổi chuyển từ tiền và niềm tin sang tài nguyên tính toán và thiết lập ban đầu.
Docling là gì?
Docling là trình phân tích tài liệu mã nguồn mở của IBM Research (giấy phép MIT). Nó đóng gói mọi thứ cần thiết trong một lệnh pip install:
- Nhận diện bố cục (Layout detection): Tìm các vùng bảng, hình ảnh, tiêu đề và nội dung chính.
- TableFormer: Mô hình deep-learning của IBM chuyên phát hiện cấu trúc bảng (hàng, cột, tiêu đề) mà không cần dùng regex phức tạp.
- OCR: Đọc văn bản từ các trang được quét (scan).
- Thứ tự đọc: Xác định trình tự logic của văn bản trong tài liệu.
Lần gọi đầu tiên sẽ tải các mô hình về bộ nhớ đệm cục bộ; tất cả các lần gọi sau đó đều diễn ra ngoại tuyến (offline).
 Quy trình xử lý của Docling
Quy trình xử lý của Docling
Cấu trúc đầu ra thống nhất
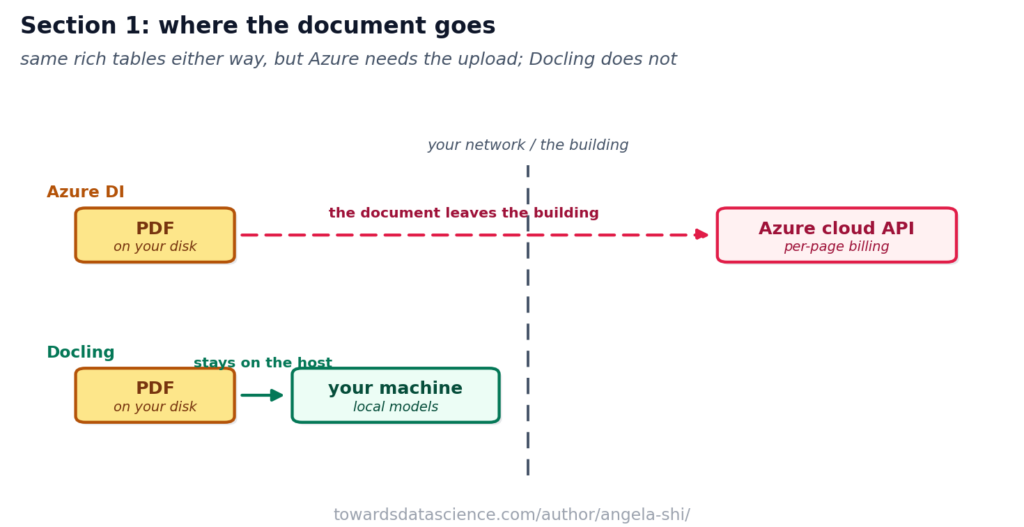
Một ưu điểm lớn của Docling là nó tuân thủ "hợp đồng" đầu ra giống hệt như các trình phân tích khác trong chuỗi bài này (PyMuPDF hay Azure). Đầu ra là một tập hợp các bảng quan hệ (DataFrame) mà các quy trình hạ lưu (downstream pipeline) có thể tiêu thụ mà không cần quan tâm engine nào đã tạo ra chúng.
Cụ thể, hàm parse_pdf_docling trả về các bảng:
line_df: Chứa các dòng văn bản, ô bảng và checkbox.image_df: Hình ảnh, văn bản OCR bên trong và phân loại.toc_df: Mục lục được tái tạo từ các nhãn bố cục.object_registry: Các chú thích (caption) được phát hiện.cross_ref_df: Các tham chiếu chéo trong văn bản.
Những cải tiến cụ thể trên từng bảng dữ liệu
Để minh họa, chúng ta hãy xem Docling xử lý bài báo nổi tiếng "Attention Is All You Need" (15 trang, 4 bảng, 6 hình) như thế nào so với PyMuPDF.
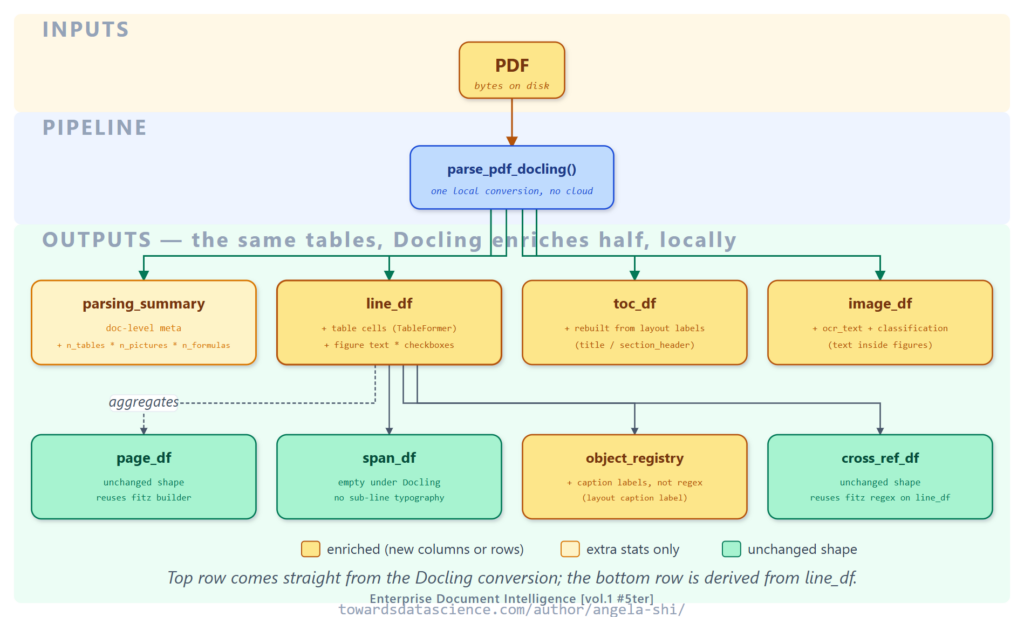
1. line_df: Bảng biểu và văn bản trong hình
Mô hình TableFormer của Docling phát hiện từng bảng dưới dạng lưới ô với chỉ số hàng/cột. Chúng ta làm phẳng lưới này thành các dòng Markdown để lưu vào line_df. Điều này cho phép trình truy xuất (retriever) tìm kiếm dựa trên từ khóa trong nội dung bảng.
Ngoài ra, văn bản nằm trong vùng hình (figure) cũng được khôi phục thông qua OCR, giúp các nhãn trong biểu đồ trở nên có thể tìm kiếm được. Các ô checkbox cũng được chuyển thành dòng văn bản [x] hoặc [ ].
 Cấu trúc bảng được phát hiện bởi Docling
Cấu trúc bảng được phát hiện bởi Docling
2. image_df: OCR và Phân loại
Docling không chỉ trích xuất hình ảnh mà còn thu thập các mục văn bản nằm trong vùng hình (ít nhất 50% diện tích) để tạo thành cột ocr_text. Nó cũng cung cấp cột classification để gắn thẻ loại hình ảnh (biểu đồ, logo, v.v.), một tính năng mà Azure hay PyMuPDF không có hoặc hạn chế.
3. toc_df: Tái tạo mục lục từ bố cục
Bài báo "Attention" không có bookmark (dấu trang) gốc. PyMuPDF sẽ trả về mục lục rỗng. Tuy nhiên, Docling gán nhãn từng tiêu đề (title, section_header) trong quá trình phân tích bố cục. Nhờ đó, nó có thể tái tạo một mục lục đầy đủ với 28 tiêu đề mà PyMuPDF đã bỏ lỡ.
4. object_registry: Phát hiện chú thích chính xác
Thay vì dùng regex để tìm chú thích (caption) — cách dễ bị lỗi khi văn bản xuống dòng hoặc viết tắt (ví dụ "Fig. 2") — Docling gán nhãn trực tiếp các khối chú thích trong giai đoạn phân tích bố cục. Điều này tăng độ chính xác và khả năng thu hồi (recall) đáng kể.
Chi phí, độ trễ và thiết lập
Docling miễn phí để sử dụng (free to run), nhưng không miễn phí vận hành (not free to operate).
- Độ trễ: Trên CPU, xử lý một trang qua toàn bộ pipeline (layout + TableFormer + OCR) mất khoảng 1 đến 5 giây. Bài báo 15 trang mất dưới 2 phút trên laptop CPU. GPU sẽ giúp giảm thời gian này đáng kể. So với PyMuPDF (dưới 1 giây), Docling chậm hơn nhưng đổi lại là chất lượng cấu trúc cao hơn.
- Thiết lập: Lần chuyển đổi đầu tiên sẽ tải các mô hình (hàng trăm MB) về bộ nhớ đệm cục bộ. Cần dung lượng ổ đĩa và thời gian tải về ban đầu. Sau đó, hệ thống hoạt động hoàn toàn ngoại tuyến.
- Chi phí tính toán: Không có phí theo trang. Chi phí nằm ở máy chủ bạn chạy. Với hàng triệu trang tài liệu mật, việc sở hữu tài nguyên tính toán thường rẻ hơn và an toàn hơn nhiều so với thuê dịch vụ đám mây.
Khi nào nên sử dụng công cụ nào?
Chiến lược tối ưu là "phân tích thích ứng" (adaptive parsing):
- PyMuPDF (fitz): Mặc định cho mọi tài liệu. Phù hợp với PDF số có văn bản chọn được và bố cục đơn giản. Nhanh, miễn phí, ngoại tuyến.
- Docling: Khi PyMuPDF thất bại (thiếu bảng, tài liệu quét, không có bookmark) và tài liệu là mật hoặc môi trường bị cách ly. Chạy cục bộ, miễn phí phí dịch vụ, dữ liệu không rời khỏi máy.
- Azure Document Intelligence: Khi PyMuPDF thất bại và việc tải tài liệu lên đám mây là chấp nhận được. Phí theo trang, không cần bảo trì hạ tầng mô hình.
Docling lấp đầy khoảng trống quan trọng giữa các công cụ đơn giản nhưng hạn chế và các dịch vụ đám mây mạnh mẽ nhưng rủi ro về bảo mật. Với các doanh nghiệp xây dựng hệ thống RAG nội bộ, Docling là công cụ giúp cân bằng giữa khả năng hiểu tài liệu sâu và sự tuân thủ quy định bảo mật dữ liệu.

