
Dữ liệu nhỏ, bản đồ lớn: Huấn luyện mô hình học máy địa không gian khi mẫu khan hiếm
Trong học máy địa không gian, nút thắt lớn nhất thường không phải là phần cứng mà là sự khan hiếm của dữ liệu thực địa. Bài viết này phân tích các chiến lược thực tế để xây dựng mô hình hiệu quả khi dữ liệu hạn chế, từ kỹ thuật đặc trưng đến xác thực không gian và quản lý độ bất định.

Trong lĩnh vực học máy địa không gian (geospatial machine learning), nút thắt lớn nhất hầu như không bao giờ là bộ nhớ GPU hay kích thước của mô hình. Thay vào đó, đó là số lượng mẫu thực địa hạn chế mà bạn có thể tiếp cận trên một vùng đất rộng lớn, đắt đỏ và phức tạp về hậu cần. Bài viết này được xây dựng từ các thảo luận và kinh nghiệm thực tế với dữ liệu từ Rừng rậm Amazon, nơi vấn đề này biểu hiện rõ nét nhất: rừng rậm dày đặc, khó tiếp cận và ngân sách không thể mở rộng theo quy mô cảnh quan.
Mục tiêu ở đây là thảo luận về cách xây dựng các mô hình học máy địa không gian khi việc thu thập thêm dữ liệu thực địa quá tốn kém, quá chậm, hoặc đơn giản là không khả thi. Và ở đây, "tốn kém" không phải là cách nói hoa mỹ: một ô kiểm kê rừng ở vùng sâu vùng xa có thể có giá trị ngang bằng một chiếc máy tính hiện đại dùng để huấn luyện mô hình. Trọng tâm không phải là một công thức có sẵn, mà là các sự đánh đổi thực tế: cái gì cần đơn giản hóa, đâu cần chuẩn hóa, cách xác thực như thế nào, và làm thế nào để truyền đạt độ bất định khi bộ dữ liệu nhỏ hơn nhiều so với mong muốn.
Vấn đề này thường gặp trong các ứng dụng môi trường, lâm nghiệp và cảm nhận từ xa, nhưng không giới hạn ở các bối cảnh đó. Logic này áp dụng cho bất kỳ biến số không gian liên tục nào mà ở đó hình ảnh, bản đồ khảm và khối dữ liệu (data cubes) tồn tại với số lượng dồi dào, nhưng nhãn thực địa lại đắt đỏ, hiếm hoi và không hoàn hảo.
Thách thức cấu trúc của dữ liệu địa không gian
Dữ liệu thực địa môi trường luôn tốn kém để thu thập. Nó đòi hỏi lập kế hoạch, hậu cần, thiết bị, nhân sự và thường phải thực hiện trong các khoảng thời gian mùa vụ hẹp. Ở các vùng xa xôi như Rừng rậm Amazon, chi phí tăng vọt: việc tiếp cận đòi hỏi thuyền, hành trình dài và các giấy phép phức tạp. Tất cả những điều này làm cho mỗi mẫu thêm vào trở nên rất đắt đỏ, điều này cũng áp dụng cho các khu rừng nhiệt đới, vùng khô cằn, đỉnh núi và đại dương. Các điểm ảnh vệ tinh và các dẫn xuất quang phổ tương đối dễ có được, nhưng các phép đo thực địa đáng tin cậy lại phức tạp về mặt hậu cần.
Kịch bản điển hình quen thuộc với bất kỳ ai làm việc với dữ liệu môi trường: một khu vực quan tâm khổng lồ, một bộ sưu tập lớn các hình ảnh, chỉ số, mô hình địa hình và các sản phẩm cảm nhận từ xa khác, nhưng chỉ có một số lượng hạn chế các điểm tham chiếu hoặc ô mẫu, được thu thập qua các chiến dịch khác nhau, đôi khi cách nhau nhiều năm.
Nhìn bề ngoài, con số từ 100 đến 200 mẫu có thể nghe ra hợp lý để xây dựng một mô hình hữu ích. Tuy nhiên, vấn đề là trong công việc địa không gian, kích thước mẫu thô gần như không bao giờ kể hết câu chuyện. Một bộ dữ liệu trông có vẻ khá thoải mái khi tổng hợp có thể hóa ra lại khá chật chội khi bắt đầu khám phá sự dị biệt môi trường.
Bước 1 – Trích xuất nhiều thông tin hơn từ mỗi mẫu
Khi nhãn dữ liệu khan hiếm, con đường hiệu quả nhất hiếm khi là nhảy ngay đến mô hình phức tạp nhất có sẵn. Lợi ích tốt nhất thường đến từ việc tăng nội dung thông tin của mỗi mẫu thông qua tích hợp dữ liệu và kỹ thuật đặc trưng (feature engineering).
Trong thực tế, điều này có nghĩa là cố gắng biểu diễn mỗi điểm tham chiếu bằng một tập hợp nhỏ nhưng giàu thông tin các tín hiệu bổ sung. Thay vì dựa vào một nguồn duy nhất, đáng để kết hợp các chỉ số từ cảm biến quang học, thông tin cấu trúc từ LiDAR hoặc radar, các biến số địa hình xuất phát từ DEM (Mô hình độ cao kỹ thuật số), và bối cảnh thời gian khi động lực mùa vụ quan trọng, chẳng hạn như lũ lụt và hạn hán ở Amazon.
Ý tưởng không phải là phình to ma trận đặc trưng với mọi thứ có sẵn. Với ít dữ liệu, điều này hầu như luôn làm tăng khả năng mô hình học được các mối quan hệ giả tạo. Mục tiêu là cô đọng các chiều vật lý khác nhau của cảnh quan thành một tập hợp các biến hữu ích và gọn gàng.
Bước 2 – Lựa chọn mô hình tôn trọng quy mô thực tế của vấn đề
Với các bộ dữ liệu nhỏ, việc lựa chọn mô hình ít liên quan đến việc "ai thắng trong điểm chuẩn" mà nhiều hơn là kiểm soát phương sai (variance control). Các mô hình linh hoạt cao có thể hấp dẫn, nhưng với ít ví dụ được gán nhãn, nguy cơ ghi nhớ tiếng ồn địa phương và các mẫu không gian ngẫu nhiên tăng lên rất nhanh.
Vì lý do này, các thuật toán dựa trên cây (tree-based algorithms) vẫn là điểm cân bằng mạnh mẽ trong nhiều trường hợp: Random Forest làm đường cơ sở vững chắc, gradient boosting như XGBoost khi cần nhiều kiểm soát và linh hoạt hơn, và các ensemble phức tạp hơn chỉ khi có bằng chứng thực sự về lợi ích ổn định. Ưu điểm của chúng không phải là phép thuật, mà là khả năng hợp lý để xử lý các phi tuyến tính, tương tác và đa cộng tuyến vừa phải trong khi cung cấp các cơ chế chuẩn hóa rõ ràng.
Trong bối cảnh này, một số sự đánh đổi xuất hiện liên tục: mô hình sâu hơn nắm bắt nhiều chi tiết hơn nhưng ghi nhớ nhiều tiếng ồn hơn; nhiều đặc trưng hơn tăng khả năng mô tả nhưng làm tăng nguy cơ quá khớp (overfitting). Với ít dữ liệu, mục tiêu không phải là tối đa hóa hiệu suất trên một lần chia tách thuận lợi, mà là tìm một cấu hình đủ ổn định để vẫn có ý nghĩa khi mô hình chuyển ra khỏi khu vực lân cận của các điểm mẫu.
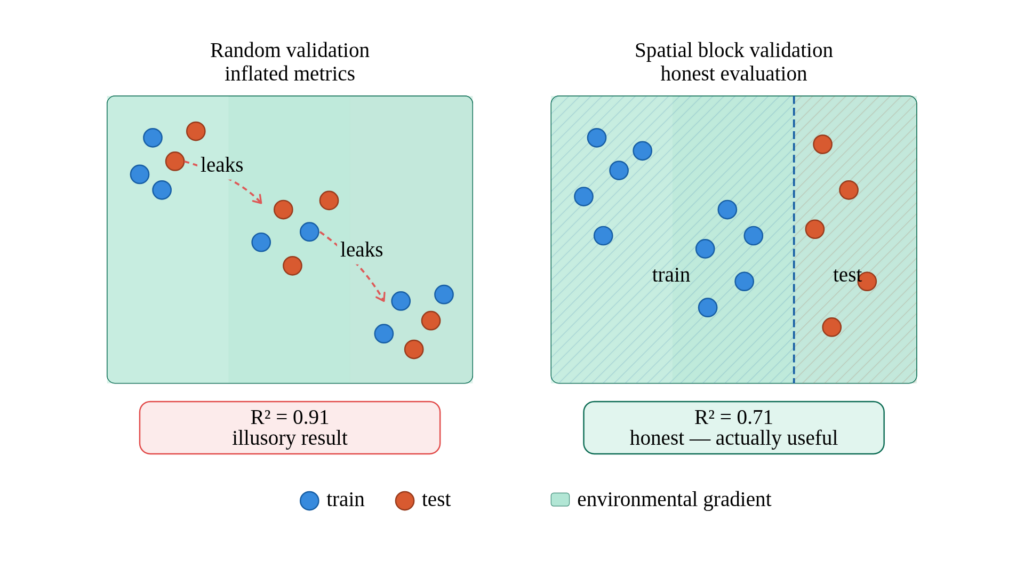 Minh họa so sánh giữa xác thực ngẫu nhiên và xác thực theo khối không gian
Minh họa so sánh giữa xác thực ngẫu nhiên và xác thực theo khối không gian
Bước 3 – Xác thực không gian trung thực
Cách dễ nhất để tự lừa dối mình trong học máy địa không gian là áp dụng kiểm định chéo ngẫu nhiên (random cross-validation) cho một vấn đề có tự tương quan không gian (spatially autocorrelated). Khi các điểm lân cận chia sẻ môi trường, lịch sử và tạo tác của cảm biến, việc chia tách các mẫu lân cận giữa tập huấn luyện và kiểm tra có xu hướng làm thổi phồng các chỉ số một cách nhân tạo.
Đây là loại sai lầm tạo ra các chỉ số xác thực xuất sắc trong phòng thí nghiệm nhưng các bản đồ hoàn toàn bị méo mó trong thực tế. Trên giấy tờ, trông có vẻ như mô hình khái quát hóa tốt; trong thực tế, nó đơn giản là đang nội suy trong một khu vực đã rất giống với những gì nó đã thấy trong quá trình huấn luyện.
Do đó, xác thực không gian là bắt buộc. Định dạng chính xác có thể khác nhau, nhưng logic thì đơn giản: các khối không gian gần nhau phải giữ lại với nhau, để tập kiểm tra thực sự đại diện cho các khu vực mà mô hình chưa nhìn thấy gián tiếp. Sự thay đổi này hầu như luôn làm giảm các chỉ số so với xác thực ngẫu nhiên, nhưng sự lùi bước apparent đó thực sự là một sự tăng trưởng về tính trung thực.
Bước 4 – Vấn đề mất cân bằng lớp ẩn giấu
Ngay cả sau khi áp dụng xác thực không gian, vẫn có một chi tiết thường bị bỏ qua. Khối lượng ban đầu từ 100 đến 200 mẫu có thể dường như đủ miễn là khu vực nghiên cứu được coi là đồng nhất.
Nhưng khi phân tích môi trường trở nên cẩn thận hơn, một lớp phức tạp khác xuất hiện: cảnh quan không hoạt động như một hệ thống duy nhất. Trong thực tế, lãnh thổ được cấu thành từ các tầng môi trường hoặc các kiểu thảm thực vật (phytophysiognomies) khác nhau, mỗi cái có cấu trúc, động lực và chữ ký không gian riêng.
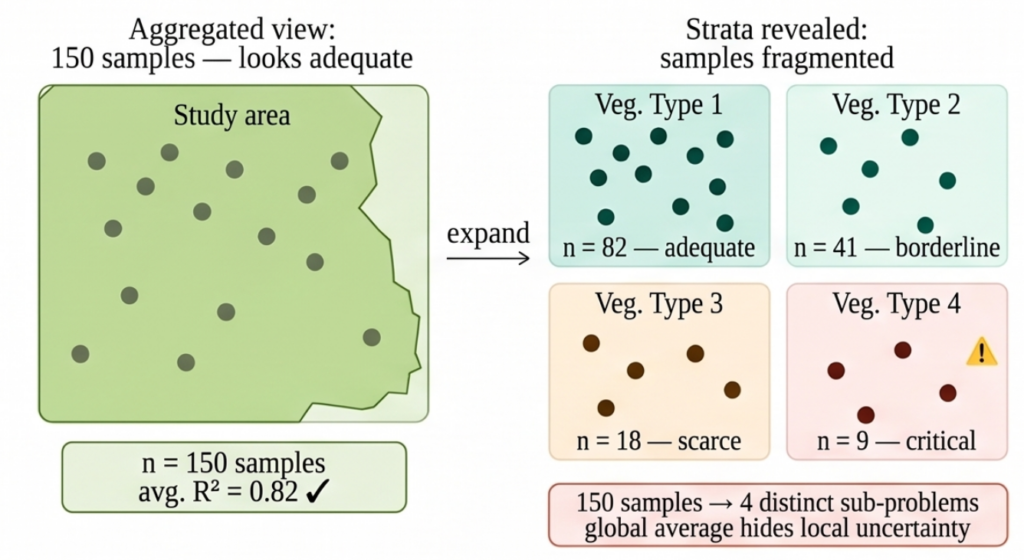 Phân phối mẫu theo tầng thảm thực vật
Phân phối mẫu theo tầng thảm thực vật
Điều này thay đổi hoàn toàn cách kích thước mẫu được diễn giải. Khối lượng dữ liệu đó không còn đại diện cho một vấn đề duy nhất; nó được phân phối trên nhiều miền sinh thái với các hành vi riêng biệt. Mô hình không học từ hàng trăm ví dụ tương đương, mà từ các tập con nhỏ hơn, mất cân bằng và rất dị biệt.
Đây là nơi cảm giác an toàn về phương pháp luận bị phá vỡ. Một số tầng được đại diện hợp lý, trong khi những tầng khác nằm ở rìa của những gì tối thiểu đáng tin cậy để huấn luyện và xác thực. Hiệu suất trung bình tổng hợp có thể trông vẫn chấp nhận được, nhưng độ bất định tăng lên chính xác nơi độ phủ mẫu yếu nhất hoặc nơi hành vi sinh thái khác biệt nhất. Nhìn vào các chỉ số trung bình là gây hiểu lầm: trong các kịch bản dị biệt, một mức trung bình toàn cầu tốt không đảm bảo hành vi ổn định trên tất cả các phần của bản đồ.
Bước 5 – Coi độ bất định là sản phẩm chính (và truyền đạt các giới hạn)
Nếu tính dị biệt không gian làm phân mảnh kích thước mẫu hiệu quả, độ bất định sẽ ngừng là một chú thích phương pháp luận và trở thành một phần trung tâm của sản phẩm giao hàng. Giả vờ rằng có độ chính xác đồng nhất là bỏ qua sự biến thiên thực tế của sai số trên không gian.
Do đó, bản đồ độ bất định phải được coi là sản phẩm chính, không phải là một phụ lục tùy chọn. Nó là công cụ cho thấy nơi mô hình được hỗ trợ bằng bằng chứng đủ và nơi nó đang ngoại suy vượt quá những gì dữ liệu có thể duy trì. Tùy thuộc vào quy trình, độ bất định này có thể được xấp xỉ bằng sự biến thiên giữa các cây, sự phân tán trên các lần gấp xác thực, hoặc phân tích không gian của phần dư out-of-fold.
Người dùng không nên chỉ nhận được một bề mặt liên tục của các giá trị dự đoán. Cách tiếp cận có trách nhiệm hơn là minh bạch và làm rõ rằng:
- Mô hình đã được xác thực theo cách không gian hợp lý
- Các tầng môi trường khác nhau trình bày các mức sai số riêng biệt
- Độ phủ mẫu ảnh hưởng trực tiếp đến độ tin cậy cục bộ
- Độ bất định là một phần của sản phẩm, không phải là chú thích
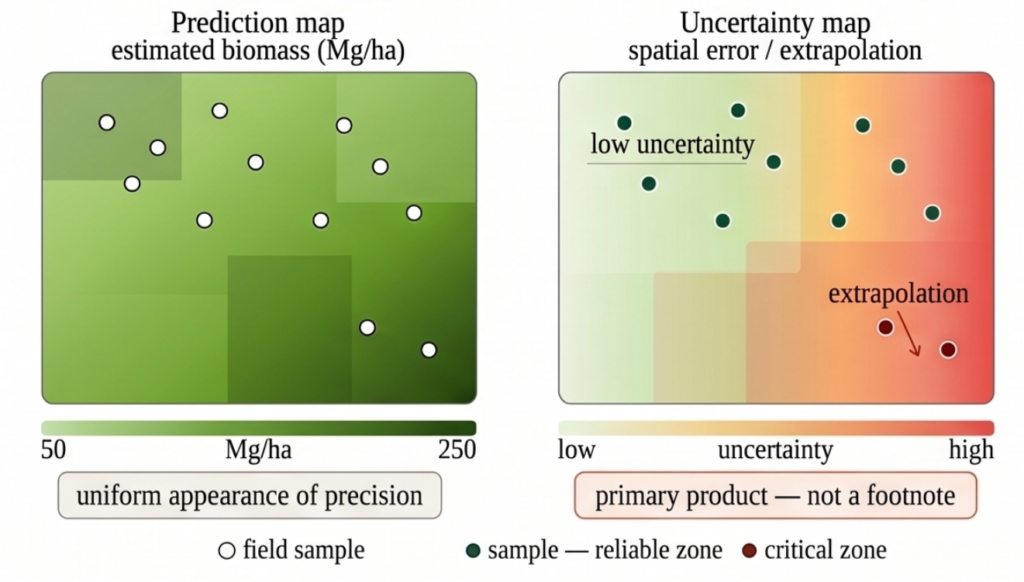 Bản đồ dự đoán sinh khối ước tính và bản đồ độ bất định không gian
Bản đồ dự đoán sinh khối ước tính và bản đồ độ bất định không gian
Thái độ này củng cố cách giải thích kỹ thuật và ngăn chặn việc sử dụng sai các bản đồ trông có vẻ chính xác nhưng thực sự độ tin cậy không đồng đều.
Khi không thể thu thập thêm dữ liệu
Khuyến nghị "thu thập thêm dữ liệu" là đúng về mặt phương pháp luận nhưng vô dụng về mặt vận hành trong nhiều bối cảnh. Ở các vùng xa xôi, chi phí, thời gian và hậu cần áp đặt các giới hạn khó khăn hơn nhiều so với bất kỳ hướng dẫn mô hình hóa nào muốn thừa nhận.
Chính vì vậy, các vấn đề địa không gian đòi hỏi sự thực dụng. Khi việc mở rộng bộ dữ liệu không khả thi, sự thay thế là làm việc tốt hơn với những gì đã có: xác thực trung thực, giảm độ phức tạp nơi cần thiết, trích xuất nhiều hơn từ các biến số đồng biến, và truyền đạt độ bất định một cách rõ ràng. Dữ liệu nhỏ trong công việc địa không gian không chỉ là vấn đề về số lượng; nó là một thách thức của số lượng, tính dị biệt và phân bố không gian cùng một lúc.
Bài học kinh nghiệm
- Kích thước mẫu là ảo ảnh: Điều quan trọng là kích thước mẫu hiệu quả trong mỗi tầng hoặc môi trường con thực tế của vấn đề.
- Xác thực không gian là không thể thương lượng: Xác thực ngẫu nhiên che giấu việc quá khớp bằng cách bỏ qua tự tương quan không gian.
- Kỹ thuật đặc trưng vượt qua sự phức tạp: Tích hợp cảm biến thông minh mang lại nhiều giá trị hơn các kiến trúc phức tạp trên các bộ dữ liệu nhỏ.
- Độ bất định hướng dẫn việc sử dụng bản đồ: Nó phải được giao hàng cùng với dự đoán để đánh dấu các vùng ngoại suy và các khoảng trống mẫu.
Khi dữ liệu không thể tăng lên, con đường trung thực duy nhất là làm cho độ bất định trở nên hữu hình — và để nó trở thành một phần của câu trả lời, không phải là một cái cớ cho nó.
Bài viết liên quan

Phần mềm
Pyroscope 2.0 của Grafana: Đưa Continuous Profiling trở nên thực tế ở quy mô lớn
13 tháng 5, 2026
Phần mềm
Mô hình Diffusion "Training-Free": Tạo ảnh chất lượng cao từ một mẫu duy nhất trong tích tắc
07 tháng 6, 2026

Phần mềm
Plugin Checkmarx Jenkins bị xâm phạm trong cuộc tấn công chuỗi cung ứng
11 tháng 5, 2026