
Đừng Xử Lý Bộ Nhớ AI Như Một Vấn Đề Tìm Kiếm Cơ Bản
Các hệ thống bộ nhớ AI truyền thống thường mắc lỗi khi chỉ tập trung vào việc lưu và truy xuất dữ liệu mà không quản lý vòng đời của thông tin. Bài viết này phân tích cách áp dụng các cơ chế như suy giảm, phát hiện mâu thuẫn và nén dữ liệu để xây dựng một trí nhớ AI đáng tin cậy hơn, hoạt động giống não bộ con người hơn là một cơ sở dữ liệu thụ động.

Đừng Xử Lý Bộ Nhớ AI Như Một Vấn Đề Tìm Kiếm Cơ Bản
Vào tháng 10 năm ngoái, trợ lý AI của tôi đã lưu một ký ức với điểm quan trọng là 8/10. Nội dung: “Đang điều tra Bun.js như một giải pháp thay thế runtime.”
Thực tế tôi chưa bao giờ chuyển sang Bun. Nói thật, đó chỉ là sự tò mò kéo dài hai ngày rồi đi vào ngõ cụt. Nhưng ký ức này vẫn tồn tại suốt sáu tháng, cứ mỗi khi tôi hỏi về quy trình build, nó lại hiện ra và âm thầm thúc đẩy AI đề xuất giải pháp Bun với sự tự tin tuyệt đối.
Không có gì sai với hệ thống cả; nó đang làm đúng những gì được yêu cầu. Và đó chính là vấn đề.
Đây là chế độ thất bại mà ít người nói đến khi xây dựng hệ thống bộ nhớ cho AI. Bạn khiến nó hoạt động trơn tru. Nó nhớ mọi thứ, truy xuất mọi thứ, rất tuyệt vời. Và trong một thời gian, AI trông thông minh lắm.
Sau đó bạn bắt đầu sử dụng nó thực sự.
Ký ức chất đống. Quyết định bị đảo ngược. Sở thích thay đổi. Hệ thống không nhận ra.
Bạn nhắc đến một điều gì đó vào tháng 1, nó được lưu với độ quan trọng cao. Tuyệt.
Đến tháng 4, AI coi đó là sự thật hiện tại. Đôi khi, phải mất một lúc bạn mới nhận ra mình đang làm việc dựa trên dữ liệu đã lỗi thời.
Một hệ thống nhớ mọi thứ không có trí nhớ. Nó có một kho lưu trữ (archive). Và một kho lưu trữ phát triển mà không được dọn dẹp sẽ nhanh chóng trở nên lộn xộn hơn cả việc không có trí nhớ nào cả.
 So sánh hệ thống lưu trữ và vòng đời bộ nhớ
So sánh hệ thống lưu trữ và vòng đời bộ nhớ
Sự khác biệt mà tôi muốn xây dựng: một cách tiếp cận bộ nhớ hoạt động giống như não bộ, không phải như cơ sở dữ liệu. Ký ức sẽ suy giảm. Nó bị thay thế.
Một số ký ức không đáng tin cậy ngay từ đầu. Những cái khác hết hạn sau một khoảng thời gian nhất định. Não bộ quản lý tất cả những điều này tự động mà không cần bạn làm gì cả. Đó là mục tiêu của tôi.
Vấn đề của “Lưu và Truy xuất”
Hầu hết các hệ thống bộ nhớ thường giả định một quy trình hai bước: Ghi. Đọc. Xong việc.
Điều này ổn nếu bạn đang xây dựng một tủ hồ sơ. Nhưng không ổn nếu bạn đang cố gắng xây dựng một trợ lý mà bạn có thể dựa vào trong nhiều tháng.
Ký ức bạn viết vào tuần đầu tiên vẫn còn ở tuần thứ tám, tươi mới và có mức độ ưu tiên cao như ngày bạn tạo ra nó, mặc dù quyết định đó đã bị đảo ngược hai tuần trước.
Ký ức khác, mâu thuẫn với quyết định trước đó của bạn, lại được lưu một cách hời hợt và đơn giản là không bao giờ có đủ thời gian để trở thành ưu tiên vì nó không nhận được đủ lượt truy cập để đẩy mình lên hàng đợi.
Và thế là, không do dự, trợ lý của bạn kéo ra một quyết định mà bạn đã hủy bỏ. Mãi đến lần thử thứ ba, bạn mới nhận ra mẫu số: trợ lý đã dựa vào thông tin lỗi thời suốt thời gian qua.
Vấn đề không phải là nhớ, mà là không biết cách buông bỏ.
Nền tảng của giải pháp
Thay vì mã hóa ký ức và chạy tìm kiếm độ tương đồng cosine (cosine similarity), chúng ta có thể giữ chúng dưới dạng văn bản thuần túy bên trong cơ sở dữ liệu SQLite, mà LLM có thể tham khảo để lấy chỉ mục ngắn gọn cho mỗi yêu cầu.
Không cần quy trình nhúng (embedding), API bên thứ ba hay tệp bổ sung. Khả năng hiểu ngôn ngữ của LLM thực hiện nhiệm vụ truy xuất. Nó nghe có vẻ quá đơn giản, nhưng thực tế hoạt động surprisingly tốt ở mức độ cá nhân.
Lược đồ của tôi xây dựng dựa trên nền tảng đó với các trường vòng đời (lifecycle fields): importance, confidence, decay_score, status, contradicted_by, expires_at. Mỗi trường trả lời một câu hỏi về sức khỏe của ký ức mà câu hỏi “nó có tồn tại không?” không thể làm được.
Sự suy giảm của ký ức (Memory Decay)
Vấn đề đầu tiên khá đơn giản: ký ức cũ không tự dọn dẹp được.
Mỗi ký ức trong cơ sở dữ liệu được gán một decay_score từ 0 đến 1. Nó bắt đầu ở mức 1.0 tại thời điểm tạo và suy giảm theo thời gian, tùy thuộc vào lần cuối cùng ký ức đó được truy cập là bao lâu trước đây.
Những ký ức bạn thường xuyên tham khảo vẫn tươi mới. Trong khi những ký ức không được consulted trong vài tháng sẽ mờ dần về mức 0.
Khi chúng rơi xuống dưới ngưỡng liên quan, chúng được lưu trữ (archived), không phải xóa, vì mờ dần không có nghĩa là chúng sai, chỉ là không còn hữu ích nữa.
Đây chính là cơ chế sẽ bắt được vấn đề Bun.js trong phần mở đầu của bài viết này. Ký ức bị lãng quên của tôi sẽ mờ dần trong vòng hai tháng, thậm chí tôi không cần xóa nó.
Phát hiện mâu thuẫn
Đây là phần mà ít người xây dựng và là nguyên nhân gây thiệt hại lớn nhất khi thiếu vắng nó.
Hãy xem xét kịch bản này: bạn nói với AI rằng bạn đang dùng PostgreSQL. Sau đó ba tháng sau, bạn chuyển sang MySQL và nhắc ngắn gọn trong cuộc trò chuyện.
Bây giờ, bạn có mười bốn ký ức liên quan đến PostgreSQL với độ quan trọng cao, trong khi ký ức duy nhất liên quan đến MySQL của bạn có độ quan trọng thấp.
Vì vậy, khi hỏi về thiết lập cơ sở dữ liệu sáu tháng sau, AI tự tin nói “bạn đang dùng PostgreSQL”, và bạn mất mười phút để bối rối trước khi nhận ra chuyện gì đang xảy ra.
Giải pháp: khi một ký ức mới được tạo, hãy kiểm tra xem nó có mâu thuẫn với bất kỳ thứ gì đã lưu chưa và chủ động đánh dấu các ký ức cũ hơn là đã bị thay thế (superseded).
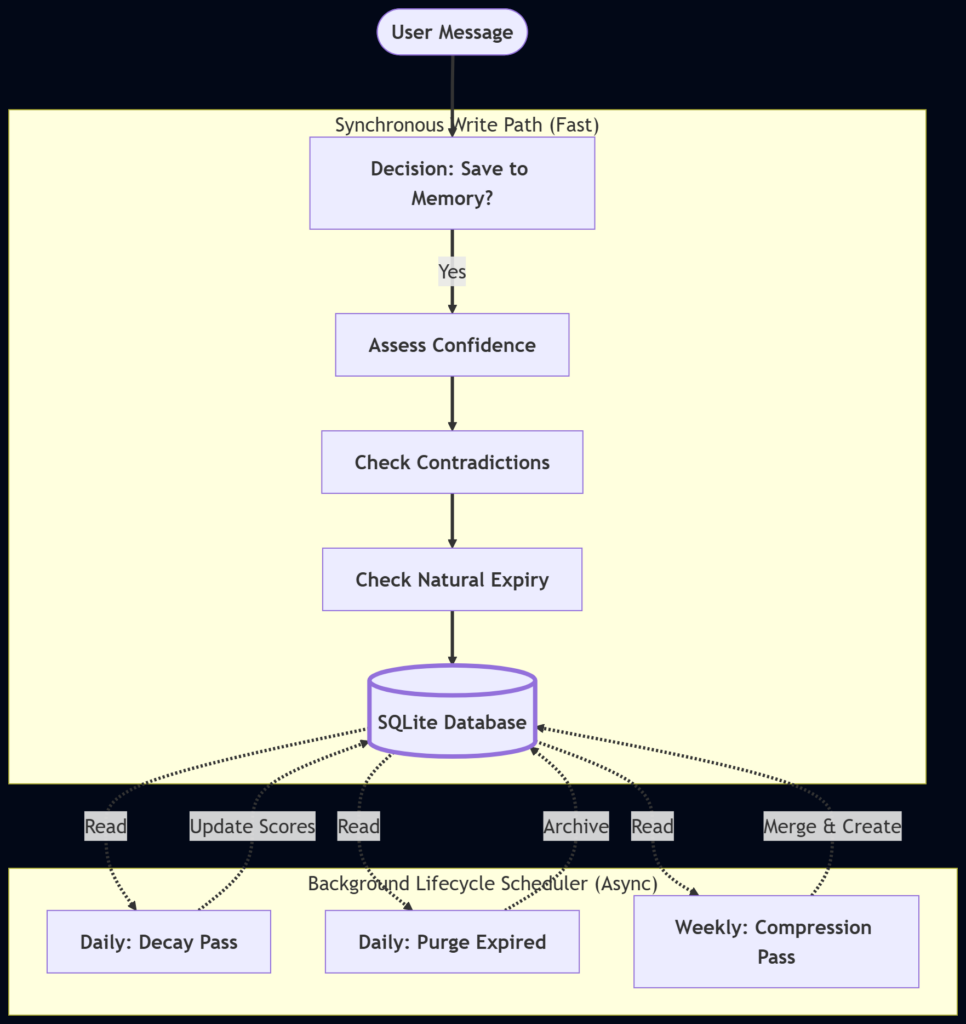 Quy trình xử lý vòng đời bộ nhớ
Quy trình xử lý vòng đời bộ nhớ
Trường contradicted_by đáng được nhắc đến thêm. Khi một ký ức bị thay thế bởi một ký ức mới hơn, nó không bị xóa ngay. Thay vào đó, một tham chiếu đến bản thay thế được thêm vào nó, cho phép bạn truy ngược từ ký ức đã cập nhật về bản gốc khi cần.
Nếu bạn đang debug lý do tại sao AI nói điều kỳ lạ, bạn có thể kéo ký ức nó đã sử dụng và truy tìm lịch sử của nó qua memory_events.
Đánh giá độ tin cậy (Confidence Scoring)
Hai ký ức có thể cùng về một sự thật. Trong một trường hợp, tuyên bố được đưa ra rõ ràng: “Tôi dùng FastAPI, luôn luôn vậy.” Trong trường hợp khác, thông tin được suy ra (“họ có vẻ thích các khung async”). Những điều này không nên được cân nhắc như nhau.
Điểm tin cậy giúp hệ thống phân biệt giữa những gì bạn nói với nó và những gì nó tự suy ra về bạn. Nó bắt đầu tại thời điểm đánh giá, ngay khi ký ức được lưu, với một cuộc gọi LLM nhỏ.
Độ tin cậy ảnh hưởng trực tiếp đến việc sắp xếp truy xuất. Một ký ức có độ quan trọng 8 nhưng độ tin cậy chỉ 0.3 sẽ xếp sau một ký ức có độ quan trọng 6 và độ tin cậy 0.9.
Đây chính là ý tưởng. Độ tin cậy cao trong một ký ức yếu hơn sẽ đánh bại độ tin cậy thấp trong một ký ức có vẻ mạnh khi câu hỏi là “AI thực sự biết điều gì?”.
Nén và Nâng cấp (Compression and Elevation)
Sau vài tháng làm việc với một trợ lý cá nhân, bạn sẽ có khá nhiều ký ức trùng lặp. “Người dùng thích tên hàm ngắn” từ tháng 1. “Người dùng nhắc đến việc giữ code dễ đọc hơn là thông minh” từ tháng 2. “Người dùng yêu cầu tránh one-liners trong việc refactor” từ tháng 3.
Đây là cùng một sở thích. Nó nên được gộp lại thành một ký ức duy nhất.
Thay vì chỉ nhóm các ký ức, chúng ta viết lại chúng thành một phiên bản sạch hơn của sự thật. Quy trình này tìm các nhóm ký ức cơ bản lặp lại mình trong các cuộc trò chuyện khác nhau và thay thế chúng bằng một mục tốt hơn.
Hết hạn ký ức (Expiring Memories)
Một số thứ không nên tồn tại mãi mãi theo thiết kế. Một hạn chót. Một chặn tạm thời. “Đang chờ phản hồi từ Alice về thông số API.” Đó là ngữ cảnh hữu ích hôm nay. Ba tuần sau, nó chỉ là nhiễu.
Hệ thống có thể kiểm tra tại thời điểm ghi xem ký ức này có ngày kết thúc tự nhiên không. Nếu có, nó sẽ đặt trường expires_at. Một công việc hàng ngày sẽ lưu trữ bất kỳ thứ gì đã quá hạn.
Kết luận
Việc thêm các lớp logic này có phải là quá mức (overkill) không? Không. Nhưng tôi đã nghĩ vậy trong một thời gian dài.
Tôi cứ tự nhủ mình sẽ thêm những thứ này “sau này, khi hệ thống lớn hơn”. Nhưng điều đó không đúng. Vấn đề không phải là hệ thống lớn đến mức nào, mà là nó tồn tại bao lâu. Chỉ ba tháng sử dụng hàng ngày là quá đủ.
Chi phí thêm vào là có thật, nhưng nhỏ. Sự suy giảm và hết hạn là SQLite thuần túy, tính bằng mili-giây. Phát hiện mâu thuẫn thêm một cuộc gọi gpt-4o-mini mỗi lần ghi. Nén gọi gpt-4o nhưng chạy một lần một tuần.
Nếu bạn đang xây dựng một hệ thống dùng trong hai tuần rồi bỏ, hãy quên mọi thứ ở trên. Lưu và truy xuất là đủ. Nhưng nếu bạn đang làm việc trên thứ gì đó có ý định tìm hiểu về bạn, thì những gì chúng ta thảo luận là không thể thương lượng.
Nick Lawson đã chỉ ra rằng pipeline nhúng có thể là tùy chọn ở quy mô cá nhân. Điều này mở ra khả năng của một kiến trúc đơn giản hơn. Bài viết này cung cấp khung hoạt động khiến kiến trúc đó hoạt động được sau tháng đầu tiên.
Và điều đó quan trọng hơn tôi mong đợi. Không chỉ để debug. Mà để tạo niềm tin. Một trợ lý AI có thể kiểm toán là một trợ lý bạn sẽ tin tưởng. Niềm tin là thứ biến một công cụ thành thứ bạn thực sự dựa vào.
Và điều đó chỉ xảy ra khi hệ thống của bạn biết không chỉ cách nhớ, mà còn biết khi nào cần quên.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026