
Giải quyết game Connect Four bằng Deep Q-Learning: Từ lý thuyết đến thực hành
Bài viết này khám phá việc áp dụng Deep Q-Learning để giải quyết trò chơi Connect Four, chuyển đổi từ các phương pháp bảng sang xấp xỉ hàm. Bằng cách sử dụng bộ đệm kinh nghiệm và cập nhật theo lô, mô hình đã học được chiến lược vượt qua ngẫu nhiên, dù vẫn còn hạn chế trong lối chơi phòng thủ.

Trong các bài viết trước, chúng ta đã khám phá cách mở rộng Học tăng cường (Reinforcement Learning - RL) vượt ra ngoài thiết lập dạng bảng (tabular) bằng cách sử dụng xấp xỉ hàm. Mặc dù điều này cho phép chúng ta khái quát hóa qua các trạng thái, các thí nghiệm cũng chỉ ra một hạn chế quan trọng: trong các môi trường đơn giản như GridWorld, các phương pháp xấp xỉ thường gặp khó khăn để đạt được sự ổn định và hiệu quả tương tự các phương pháp bảng. Lý do chính là việc học một biểu diễn tốt bản thân nó đã là một bài toán khó—và điều này có thể lấn át lợi ích của việc khái quát hóa khi không gian trạng thái vẫn còn tương đối nhỏ.
Để thực sự khai phá sức mạnh của xấp xỉ hàm, chúng ta cần chuyển sang các môi trường mà ở đó các phương pháp bảng không còn khả thi. Điều này dẫn chúng ta đến với các trò chơi nhiều người chơi, nơi không gian trạng thái tăng lên theo cấp số nhân và việc khái quát hóa trở nên thiết yếu. Trong bài viết này, chúng ta sẽ xem xét trò chơi kinh điển Connect Four và điều tra cách học các chính sách mạnh mẽ bằng Deep Q-Learning.
Từ Sarsa đến Deep Q-Learning
Để giải quyết nhiệm vụ này, chúng ta mở rộng khung làm việc theo một số chiều quan trọng.
Đầu tiên, chúng ta chuyển từ cập nhật trực tuyến (online updates) sang thiết lập đào tạo theo lô (batched training). Trong triển khai Sarsa trước đây, chúng ta cập nhật mô hình sau mỗi lần chuyển tiếp. Mặc dù trung thành với thuật toán gốc, cách tiếp cận này kém hiệu quả về mặt tính toán. Để giải quyết vấn đề này, chúng ta giới thiệu bộ đệm kinh nghiệm (replay buffer). Thay vì cập nhật ngay lập tức, chúng ta lưu trữ các chuyển tiếp và sau đó thực hiện cập nhật theo lô trên kinh nghiệm đã thu thập. Điều này không chỉ cải thiện hiệu quả tính toán mà còn ổn định việc học bằng cách giảm phương sai của các cập nhật riêng lẻ.
Tại thời điểm này, một sự thay đổi khái niệm quan trọng xảy ra. Bằng cách lấy mẫu từ kinh nghiệm quá khứ thay vì tuân thủ nghiêm ngặt chính sách hiện tại, chúng ta chuyển dịch từ Sarsa (phương pháp on-policy) sang Q-learning (phương pháp off-policy). Sự kết hợp giữa bộ đệm kinh nghiệm và Q-learning tạo thành nền tảng của Deep Q-Networks (DQN).
Cuối cùng, chúng ta chuyển sang khả năng mở rộng. Học tăng cường vốn đòi hỏi nhiều dữ liệu, do đó tăng cường thông lượng (throughput) là rất quan trọng. Chúng ta triển khai một trình bao bọc môi trường vector hóa cho phép mô phỏng nhiều trò chơi Connect Four song song. Trong thực tế, việc đạt được tính song song thực sự trong Python là không dễ dàng do Khóa thông dịch toàn cầu (GIL), nhưng sự kết hợp giữa cập nhật theo lô và vector hóa môi trường vẫn mang lại cải thiện đáng kể về hiệu suất.
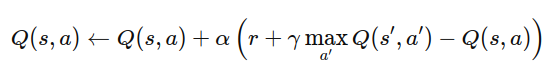 Mô phỏng môi trường vector hóa
Mô phỏng môi trường vector hóa
Triển khai và Tái khám phá Q-Learning
Trong bài viết này, tôi sẽ tập trung vào các khía cạnh RL thay vì đi sâu vào chi tiết vector hóa. Cấu trúc vector hóa ở đây là một phần mở rộng của khung làm việc trước đó cho nhiều trò chơi chạy song song.
Hãy xem xét lại Q-learning và kết nối nó với triển khai của chúng ta. Quy tắc cập nhật cốt lõi sử dụng toán tử max trên tất cả các hành động tiếp theo có thể thực hiện được, khiến nó trở thành phương pháp off-policy. Khi kết hợp với mạng nơ-ron, cách tiếp cận này thường được gọi là Deep Q-Learning. Thay vì duy trì bảng giá trị, chúng ta huấn luyện một mạng nơ-ron để xấp xỉ hàm giá trị hành động.
Trong triển khai của chúng ta, điều này tương ứng trực tiếp với hàm batch_update. Đối với một lô chuyển tiếp, chúng ta tính toán các giá trị Q dự đoán, xây dựng mục tiêu bằng cách sử dụng giá trị Q tối đa của trạng thái tiếp theo (chỉ xem xét các nước đi hợp pháp), và huấn luyện mạng bằng cách giảm thiểu hàm mất mát Huber.
 Biểu đồ kết quả huấn luyện
Biểu đồ kết quả huấn luyện
Kết quả và Đánh giá
Với những công cụ trên, hãy xem xét kết quả. Để so sánh, hãy nhớ lại rằng các phương pháp bảng trước đó hầu như không vượt qua được ngẫu nhiên sau 100.000 bước. Trong thí nghiệm này, chúng ta tập trung vào hai tác nhân: DQN và đường cơ sở ngẫu nhiên.
Chúng ta quan thấy một số hiệu ứng thú vị. Tỷ lệ thắng của chính sách ngẫu nhiên giảm nhanh hơn nhiều so với thiết lập bảng—bằng chứng rõ ràng rằng DQN đang thực sự học trò chơi. Tuy nhiên, sau khoảng một triệu bước, sự cải thiện đi vào ngõ cụt, với chính sách ngẫu nhiên vẫn thắng khoảng 20% số trận.
Để hiểu rõ hơn ý nghĩa thực tế, chúng ta có thể đánh giá chính sách đã học against một người chơi. Kết quả khá thú vị: tác nhân đã rõ ràng học được cách chơi tấn công—nó tích cực theo đuổi việc tạo ra bốn quân liên tiếp của riêng mình. Tuy nhiên, nó gặp khó khăn trong lối chơi phòng thủ, thất bại trong việc dự đoán và chặn các mối đe dọa đơn giản từ đối thủ.
 Cảnh chơi với người dùng
Cảnh chơi với người dùng
Kết luận
Trong bài viết này, chúng ta đã chuyển từ Sarsa dạng bảng sang Deep Q-Learning, giới thiệu bộ đệm kinh nghiệm, cập nhật theo lô và xấp xỉ hàm. Chúng ta đã áp dụng điều này cho Connect Four và thu được kết quả rõ ràng: tác nhân của chúng ta không còn bị mắc kẹt ở mức ngẫu nhiên—nó học hỏi, cải thiện và liên tục vượt trội hơn chính sách ngẫu nhiên.
Nhưng quan trọng không kém, chúng ta cũng thấy các giới hạn. Ngay cả sau khi huấn luyện rộng rãi, tác nhân vẫn đi vào ngõ cụt và thể hiện những điểm yếu rõ ràng—đáng chú ý nhất là trong lối chơi phòng thủ. Trong các cài đặt nhiều người chơi, bản thân bài toán trở nên khó khăn hơn: đối thủ tiến hóa, môi trường không còn tĩnh tại và các mục tiêu học tập liên tục thay đổi.
Cho đến thời điểm này, khung làm việc của chúng ta đã ưu tiên tính tổng quát và rõ ràng. Nhưng để đi xa hơn, điều đó là chưa đủ. Hiệu suất đòi hỏi sự chuyên biệt hóa. Trong các bài viết tiếp theo, chúng ta sẽ tập trung vào việc xây dựng các hệ thống nhanh hơn, ổn định hơn và có khả năng mở rộng tốt hơn—đẩy các tác nhân vượt qua các đường cơ sở đơn giản hướng tới khả năng cạnh tranh thực sự.
Bài viết liên quan

Công nghệ
Tấn công mạng làm tê liệt nhà máy đường lớn tại Australia, nông dân không thể thu hoạch
17 tháng 6, 2026

Công nghệ
OpenAI tặng ưu đãi Codex đặc biệt cho 8.000 developer sau khi tiệc GPT-5.5 cháy vé
05 tháng 5, 2026

Công nghệ
Apple gây sức ép lên Châu Âu: Đổ lỗi cho DMA khi hoãn Siri AI
09 tháng 6, 2026