
Giới thiệu Timer-XL: Mô hình nền tảng đột phá cho dự báo chuỗi thời gian dài hạn
Timer-XL là mô hình Transformer decoder-only mới từ Đại học Thanh Hoa, được thiết kế chuyên biệt cho dự báo chuỗi thời gian với khả năng xử lý ngữ cảnh dài vượt trội. Với cơ chế TimeAttention độc đáo, mô hình này thống trị các bài toán chuẩn và hỗ trợ cả zero-shot forecasting.

Trong bối cảnh các mô hình nền tảng (foundation models) ngày càng phát triển, Timer-XL đã xuất hiện như một bước tiến quan trọng trong lĩnh vực dự báo chuỗi thời gian. Được phát triển bởi phòng thí nghiệm THUML của Đại học Thanh Hoa (Tsinghua University), Timer-XL là phiên bản nâng cấp của mô hình Timer trước đó, tập trung tối đa vào khả năng tổng quát hóa và dự báo với ngữ cảnh dài (long-context forecasting).
Bài viết này sẽ đi sâu vào cơ chế hoạt động, kiến trúc và hiệu suất vượt trội của Timer-XL so với các mô hình hiện hành.
Timer-XL là gì?
Timer-XL là một mô hình nền tảng dạng decoder-only Transformer được xây dựng chuyên biệt cho nhiệm vụ dự báo. Điểm nổi bật của mô hình này là khả năng cung cấp giải pháp dự báo thống nhất cho nhiều trường hợp khác nhau mà không cần thay đổi cấu trúc.
Các tính năng chính của Timer-XL bao gồm:
- Độ dài đầu vào/đầu ra linh hoạt: Khác với các mô hình như Tiny-Time-Mixers cần nhiều phiên bản cho các độ dài khác nhau, Timer-XL sử dụng một mô hình duy nhất cho mọi trường hợp.
- Dự báo ngữ cảnh dài: Xử lý hiệu quả các cửa sổ nhìn lại (lookback windows) dài, cho phép sử dụng dữ liệu lịch sử kéo dài hàng năm.
- Hỗ trợ đa dạng đặc trưng: Có khả năng dự báo cả chuỗi đơn biến (univariate), đa biến phức tạp (multivariate) và các biến ngoại sinh (exogenous variables) trong cùng một thiết lập.
- Tính linh hoạt: Có thể được huấn luyện từ đầu hoặc sử dụng dưới dạng mô hình nền tảng đã được tiền huấn luyện (pretrained).
Kiến trúc Decoder-only: Tại sao lại hiệu quả cho dự báo?
Trước khi đi sâu vào Timer-XL, chúng ta cần nhìn lại sự tranh luận giữa các kiến trúc Encoder, Decoder và Encoder-Decoder trong thế giới Transformer.
Trong xử lý ngôn ngữ tự nhiên (NLP), các mô hình decoder-only như GPT thống trị các tác vụ tạo văn bản nhờ cơ chế chú ý nhân quả (causal attention) – chỉ nhìn vào các token trước đó để dự đoán token tiếp theo. Ngược lại, các mô hình encoder-only như BERT sử dụng chú ý hai chiều để hiểu ngữ cảnh.
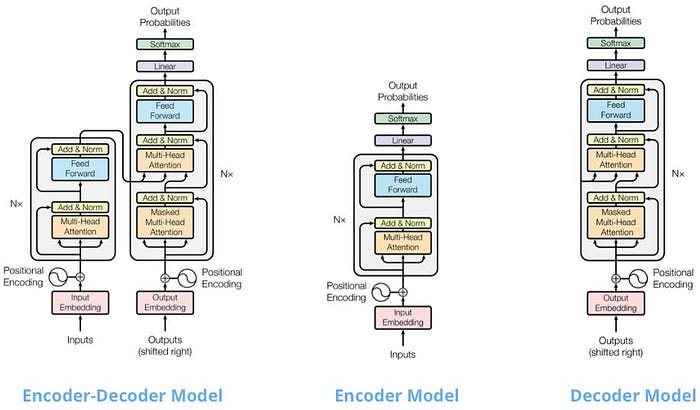 Các biến thể ban đầu của mô hình Transformer
Các biến thể ban đầu của mô hình Transformer
Đối với chuỗi thời gian, các thí nghiệm gần đây cho thấy kiến trúc decoder và encoder-decoder thường vượt trội hơn encoder thuần túy trong các bài toán dự báo. Timer-XL kế thừa thiết kế decoder-only từ Timer, nhưng chuyên biệt hóa hoàn toàn cho dự báo thay vì xử lý đa nhiệm vụ. Điều này giúp mô hình tập trung tối đa vào việc nắm bắt xu hướng thời gian một cách nhân quả.
Khả năng xử lý ngữ cảnh dài (Long-Context)
Một trong những thách thức lớn nhất của các mô hình Transformer trong chuỗi thời gian là xử lý độ dài chuỗi lớn. Trong khi các LLM hiện đại như Gemini có thể xử lý tới 1 triệu token, các mô hình chuỗi thời gian thường gặp khó khăn khi vượt quá 1.000 điểm dữ liệu.
Timer-XL đã giải quyết vấn đề này một cách xuất sắc. Như biểu đồ dưới đây minh họa, hiệu suất của Timer-XL duy trì ổn định và tốt hơn so với các mô hình khác khi độ dài ngữ cảnh tăng lên.
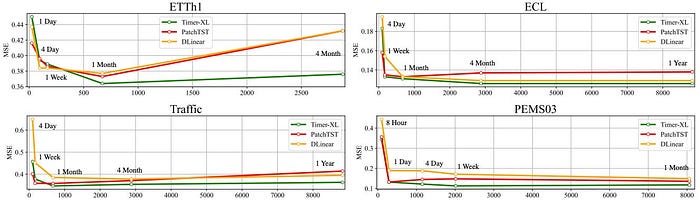 Hiệu suất của các mô hình khác nhau trên các độ dài ngữ cảnh
Hiệu suất của các mô hình khác nhau trên các độ dài ngữ cảnh
Điều này cho phép Timer-XL áp dụng cho các bài toán dự báo tần suất cao, ví dụ như sử dụng dữ liệu giao thông hàng ngày trong suốt một năm (khoảng 8.760 điểm dữ liệu) để đưa ra dự báo chính xác.
TimeAttention: "Vũ khí bí mật" của Timer-XL
Cơ chế chú ý (attention) là linh hồn của Transformer, nhưng áp dụng nó vào chuỗi thời gian không đơn giản do tính chất không bất biến theo thứ tự (non-permutation invariance) của dữ liệu thời gian.
Timer-XL giới thiệu TimeAttention, một biến thể nhân quả của cơ chế Any-Variate Attention (từ mô hình MOIRAI), được thiết kế riêng cho decoder-only. TimeAttention kết hợp:
- Rotary Positional Embeddings (ROPE): Để nắm bắt các phụ thuộc thời gian.
- Binary Biases (ALIBI): Để nắm bắt phụ thuộc giữa các biến (variates).
- Causal Self-Attention: Đảm bảo tính nhân quả trong dự báo.
Mục tiêu của TimeAttention là giữ nguyên thứ tự của các điểm dữ liệu thời gian (thứ tự quan trọng) nhưng không phụ thuộc vào thứ tự sắp xếp của các biến đầu vào (ví dụ: biến X1 đứng trước hay sau X2 không quan trọng, miễn là mối quan hệ giữa chúng được giữ nguyên).
Kiến trúc và Hiệu suất
Kiến trúc tổng thể của Timer-XL tận dụng tối đa các kỹ thuật tiên tiến của LLM hiện đại như FlashAttention để tăng tốc độ tính toán và giảm bộ nhớ. Đáng chú ý, mô hình này không sử dụng kỹ thuật Reversible Instance Normalization (RevIN) phổ biến, do cấu trúc tập trung vào cửa sổ của nó đã giải quyết tốt vấn đề dịch chuyển phân phối dữ liệu.
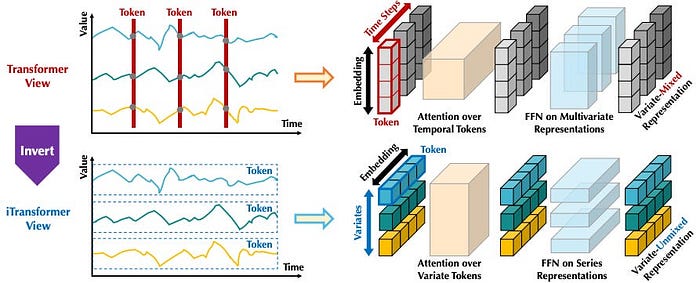 Tổng quan kiến trúc Timer-XL
Tổng quan kiến trúc Timer-XL
Kết quả Benchmark
Trên các bộ dữ liệu chuẩn, Timer-XL đã chứng minh hiệu suất dẫn đầu:
- Đa biến (Multivariate): Vượt trội so với các mô hình SOTA trước đây như PatchTST và iTransformer.
- Biến ngoại sinh (Covariate-Informed): Trong bài toán dự báo giá điện (EPF), Timer-XL đạt kết quả tốt nhất, vượt qua cả các biến thể encoder-based.
- Zero-Shot Forecasting: Khi không được huấn luyện lại trên dữ liệu mục tiêu, Timer-XL-base vẫn đạt thành tích ấn tượng, đứng trước các đối thủ nặng ký như Time-MOE và MOIRAI.
Kết luận
Timer-XL đại diện cho bước chuyển mình từ các mô hình đa mục tiêu sang các mô hình chuyên biệt hóa sâu sắc trong lĩnh vực dự báo chuỗi thời gian. Với khả năng xử lý ngữ cảnh dài và cơ chế TimeAttention thông minh, Timer-XL mở ra cơ hội lớn cho việc áp dụng các mô hình nền tảng vào các bài toán thực tế đòi hỏi độ chính xác cao và dữ liệu lịch sử dài.
Hiện tại, nhóm nghiên cứu đã phát hành phiên bản tiền huấn luyện cho bài toán đơn biến, và các phiên bản đa biến cũng đang được cộng đồng mong chờ.
Bài viết liên quan

Công nghệ
Đây là BIOS đang nói chuyện: Xin hãy sửa tôi, máy tính của bạn đã hỏng
12 tháng 6, 2026

Công nghệ
Điều hòa trạng thái rắn: Hứa hẹn tương lai mát mẻ hay thách thức chưa thể giải quyết?
15 tháng 6, 2026

Công nghệ
Revolut bắt đầu triển khai dịch vụ cho hàng nghìn người dùng tại Ấn Độ trước khi ra mắt rộng rãi
01 tháng 6, 2026