
GLM-5.2: Mô hình Open Weights mới dẫn đầu Chỉ số Thông minh Artificial Analysis
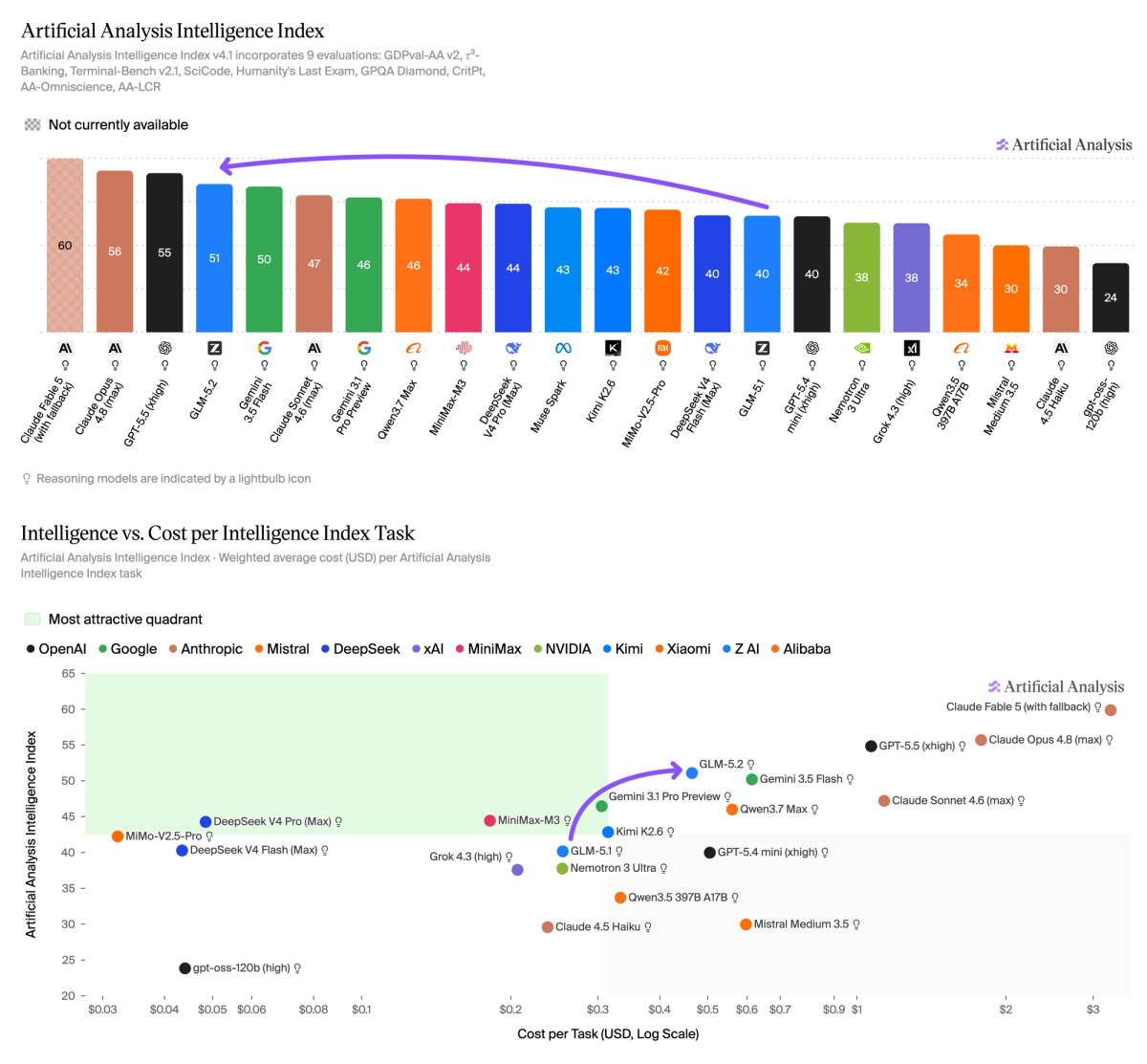
GLM-5.2 của Z ai đã chính thức vượt qua các đối thủ nặng ký để trở thành mô hình open weights hàng đầu trên Chỉ số Thông minh Artificial Analysis với điểm số ấn tượng là 51. Mô hình này không chỉ cải thiện mạnh mẽ về khả năng lý luận khoa học mà còn đạt hiệu suất tương đương với các mô hình độc quyền trên các bài kiểm tra thực tế.

GLM-5.2 của Z ai đã ghi dấu ấn mạnh mẽ khi trở thành mô hình open weights (trọng số mở) hàng đầu trên Chỉ số Thông minh (Intelligence Index) v4.1 của Artificial Analysis. Với điểm số đạt mức 51, mô hình này đã vượt qua các đối thủ sừng sỏ như MiniMax-M3 và DeepSeek V4 Pro, đồng thời nằm trên biên Pareto (Pareto frontier) trong biểu đồ cân bằng giữa trí thông minh và chi phí thực thi nhiệm vụ.
 Biểu đồ hiệu suất GLM-5.2
Biểu đồ hiệu suất GLM-5.2
Cải thiện vượt bậc về hiệu suất
So với phiên bản tiền nhiệm GLM-5.1, phiên bản 5.2 có cùng kích thước (744B tham số tổng cộng / 40B tham số hoạt động) nhưng điểm số đã tăng thêm 11 điểm. Sự cải thiện này lan rộng trên hầu hết các bài đánh giá, đặc biệt là trong lĩnh vực lý luận khoa học.
Cụ thể, GLM-5.2 ghi nhận mức tăng ấn tượng trên các chỉ số:
- CritPt: +16 điểm (đạt 21%).
- HLE: +12 điểm (đạt 40%).
- AA-LCR: +9 điểm (đạt 71%).
- SciCode: +7 điểm (đạt 50%).
Ngoài ra, TerminalBench v2.1 cũng cải thiện mạnh mẽ (+16 điểm lên 78%) và GPQA Diamond tăng 3 điểm lên mức 89%.
Hiệu suất thực tế và khả năng của tác nhân AI
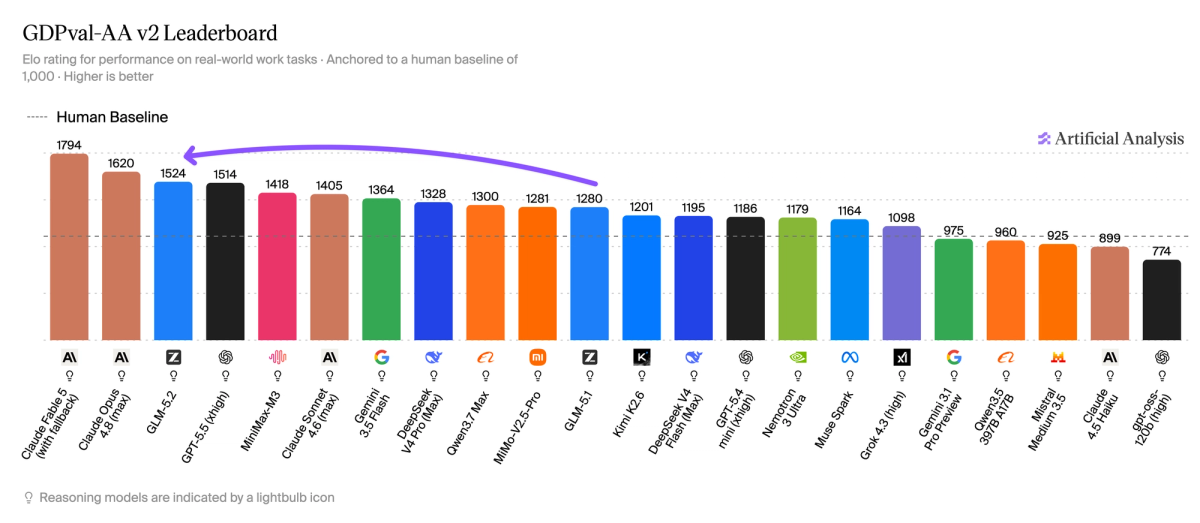
Một trong những điểm nhấn quan trọng là thành tích của GLM-5.2 trên GDPval-AA v2 - thước đo chính cho hiệu suất của các tác nhân AI (agentic performance) trong thực tế. Với điểm số 1524, GLM-5.2 vượt xa MiniMax-M3 (1418) và DeepSeek V4 Pro (1328), ngang hàng với các mô hình độc quyền hàng đầu như GPT-5.5 (xhigh reasoning).
 Chi tiết các bài kiểm tra hiệu suất
Chi tiết các bài kiểm tra hiệu suất
Mô hình cũng đạt điểm 4 trên Chỉ số AA-Omniscience, tăng từ mức 2 của GLM-5.1. Điều này phản ánh sự cải thiện cả về độ chính xác (tăng từ 24.2% lên 25.1%) và tỷ lệ ảo giác thấp hơn (giảm từ 29.4% xuống 28.1%).
Thông số kỹ thuật và Chi phí
GLM-5.2 mang đến những thông số kỹ thuật hấp dẫn cho các nhà phát triển:
- Giấy phép: MIT (mở rộng tự do sử dụng).
- Cửa sổ ngữ cảnh: 1M token, tăng gấp 5 lần so với GLM-5.1 (200K).
- Giá cả API: $1.4 cho mỗi 1M token đầu vào, $4.4 cho token đầu ra và $0.26 cho cache hit.
Tuy nhiên, cần lưu ý rằng để đạt được trí thông minh cao, GLM-5.2 sử dụng lượng token đầu ra lớn hơn nhiều so với các đối thủ. Cụ thể, mô hình tiêu thụ khoảng 43k token đầu ra cho mỗi nhiệm vụ trên Chỉ số Thông minh (trong đó 37k là lý luận), cao hơn đáng kể so với MiniMax-M3 (24k) hay Kimi K2.6 (35k). Điều này khiến chi phí cho mỗi nhiệm vụ khoảng $0.46, cao hơn một chút so với một số đối thủ nhưng bù lại là chất lượng xử lý vượt trội.
GLM-5.2 hiện đã có sẵn thông qua API chính thức của Z ai và các nhà cung cấp bên thứ ba như DeepInfra, Novita, Nebius, và Siliconflow.