
Harness Engineering: 5 định nghĩa từ 5 công ty - Tại sao mọi người không đồng ý với nhau?
Thuật ngữ "Harness Engineering" bùng nổ sau khi OpenAI công bố, nhưng Anthropic, LangChain và các chuyên gia khác lại đưa ra những định nghĩa hoàn toàn khác nhau. Bài viết phân tích sâu sắc 5 quan điểm này để tìm ra điểm chung và hướng đi thực tế cho các kỹ sư.
Harness Engineering đang gặp phải một vấn đề lớn về định nghĩa.
Vào tháng 2 năm 2026, khi OpenAI công bố bài viết "Harness engineering: leveraging Codex in an agent-first world", thuật ngữ này lập tức bùng nổ. Chỉ trong vài tuần, Anthropic đã phát hành hai hướng dẫn, LangChain đưa ra định nghĩa trên blog chính thức, Birgitta Böckeler có bài phân tích sâu trên martinfowler.com và một bài báo trên arXiv đã chính thức hóa khái niệm này.
Tuy nhiên, vấn đề là: tất cả họ đang nói những điều hơi khác nhau.
Cùng một từ ngữ. Nhưng khác nhau về ẩn dụ, xuất phát điểm và kết luận. Sau khi đọc kỹ cả 5 quan điểm, đây là những gì tôi tìm thấy.
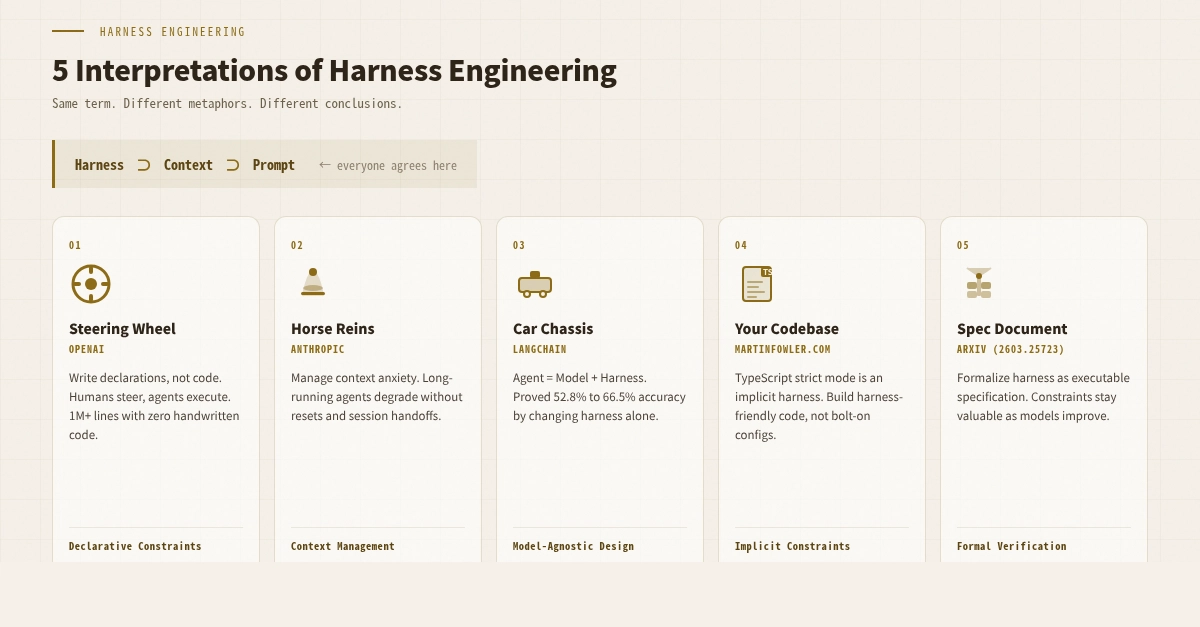
 5 cách hiểu về Harness Engineering
5 cách hiểu về Harness Engineering
Điểm chung duy nhất mà mọi người đồng ý
Có một cấu trúc lồng nhau mà không ai tranh cãi:
Harness ⊃ Context ⊃ Prompt
Bài viết của SmartScope đã nắm bắt rất rõ điều này:
Việc viết "chạy linter" trong file CLAUDE.md so với việc thực thi linter thông qua hooks là sự khác biệt giữa "hầu như mọi lúc" và "mọi lúc, không ngoại lệ".
Ngoài điều cốt lõi này ra, mọi thứ bắt đầu trở nên rắc rối.
OpenAI: "Viết khai báo. Đừng viết mã."
Bài viết của OpenAI đã gây sốc. Trong 5 tháng, các kỹ sư của họ đã không viết một dòng mã nào. Hơn 1 triệu dòng mã ứng dụng sản xuất, tất cả đều được xây dựng bởi các Codex agents. Thời gian xây dựng chỉ bằng 1/10 so với viết thủ công.
"Con người điều khiển. Agents thực thi."
Với OpenAI, một harness là một hệ thống ràng buộc mang tính khai báo (declarative constraint system). Bạn mô tả "điều gì nên xảy ra", và agent sẽ tự figuring ra "làm thế nào".
Trọng tâm:
- Mở rộng quy mô các dự án khổng lồ
- Thực thi song song bởi nhiều agents
- Đảm bảo an toàn trong môi trường sandbox
Anthropic: "Quản lý ngữ cảnh. Mô hình của bạn đang lo âu"
Anthropic lại đi từ một hướng tiếp cận hoàn toàn khác.
Trong khi OpenAI bắt đầu bằng ý tưởng "tự động hóa cả một dự án quy mô lớn", Anthropic lại bắt đầu từ câu hỏi "làm sao để giữ cho một agent chạy lâu dài ổn định?"
Khái niệm độc đáo của họ là: Context anxiety (lo âu ngữ cảnh). Khi cửa sổ ngữ cảnh (context window) bị lấp đầy thông tin, chất lượng đầu ra của mô hình sẽ suy giảm. Giống như con người ngồi trong một cuộc họp 3 tiếng không chương trình nghị sự — AI bắt đầu đưa ra quyết định tệ hơn.
Với Claude Sonnet 4.5, "lo âu ngữ cảnh" đủ mạnh khiến việc nén (tóm tắt) một mình không thể duy trì hiệu suất trên các nhiệm vụ dài. Việc đặt lại ngữ cảnh trở nên thiết yếu.
Giải pháp của họ là đặt lại định kỳ, sử dụng file claude-progress.txt và lịch sử git để chuyển trạng thái sang phiên tiếp theo.
Một điểm khác biệt của Anthropic là sự đơn giản hóa thành một agent duy nhất. Họ từng thiết kế kiến trúc đa agent, nhưng khi các mô hình thông minh hơn, một agent duy nhất với harness phù hợp là đủ.
Trọng tâm:
- Quản lý ngữ cảnh (tránh lo âu)
- Quản lý vòng đời (chuyển giao phiên)
- Cấu trúc Generator-Evaluator lấy cảm hứng từ GAN
LangChain: "Agent = Model + Harness. Đây là bằng chứng."
Bài đăng trên blog chính thức của LangChain, "The Anatomy of an Agent Harness", có định nghĩa đơn giản nhất:
Agent = Model + Harness Mô hình cung cấp trí thông minh. Harness biến trí thông minh đó trở nên hữu ích.
Sau đó, họ đã làm điều mà không ai khác làm: cho thấy các con số. Việc cải thiện harness một mình đã đẩy độ chính xác benchmark từ 52,8% lên 66,5%. Cùng một mô hình, chỉ thay đổi harness.
Đó là mức cải thiện 13,7 điểm mà không cần chạm vào mô hình. Rất khó để phản bác.
Trọng tâm:
- Nguyên tắc thiết kế harness không phụ thuộc vào mô hình
- Bằng chứng định lượng
- LangGraph (điều phối) + LangSmith (quan sát)
Birgitta Böckeler (martinfowler.com): "Codebase của bạn CHÍNH LÀ Harness"
Góc độ của Böckeler hoàn toàn khác biệt so với những người khác.
Một codebase có kiểu mạnh (strongly-typed) tự nhiên biến việc kiểm tra kiểu thành một cảm biến. Các ranh giới mô-đun được xác định rõ cung cấp các ràng buộc kiến trúc. Framework này ngầm định nâng cao tỷ lệ thành công của agent.
Nói cách khác: trước khi bạn viết file AGENTS.md, chính codebase của bạn đã là một phần của harness.
Chế độ strict của TypeScript đóng vai trò như một cổng chất lượng ngoài ý muốn cho các agent. Borrow checker của Rust là harness ngầm mạnh nhất. Các quy ước Next.js App Router cũng là harness ngầm.
Trong khi những người khác thảo luận về "cách xây dựng harness", Böckeler lại hỏi "làm thế nào để xây dựng một codebase thân thiện với harness".
Trọng tâm:
- Các ràng buộc vốn có trong mã
- Tái khám phá giá trị của an toàn kiểu (type safety), kiểm thử, linters
- "Harness không được vặn vào — nó được xây dựng từ bên trong"
arXiv: "Chính thức hóa Harness thành Đặc tả"
Nghiên cứu học thuật lại đi theo một hướng khác. Bài báo arXiv (2603.25723) đề xuất:
Tách biệt logic mẫu harness thành các đối tượng có thể đọc và thực thi được.
Thay vì coi harness là "các thực hành tốt đẹp có vẻ đúng", hãy chính thức hóa nó thành một đặc tả có thể xác minh (verifiable specification).
Một hiểu biết quan trọng từ bài báo:
Ngay cả khi các mô hình trở nên capable hơn, các điều khiển cấp harness — vai trò, hợp đồng, cổng xác minh, trạng thái liên tục, ranh giới ủy quyền — vẫn quan trọng khi được chỉ định bằng ngôn ngữ tự nhiên.
Các ràng buộc trong AGENTS.md không mất giá trị khi mô hình thông minh hơn, vì chúng là đặc tả harness, không phải là prompts.
Bảng so sánh: Điểm giống và khác nhau
| Tiêu chí | OpenAI | Anthropic | LangChain | Böckeler (mf.com) | Academic |
|---|---|---|---|---|---|
| Ẩn dụ | Vô lăng | Cương ngựa | Khung gầm xe | Kiểu dữ liệu | Tài liệu đặc tả |
| Xuất phát điểm | Thí nghiệm 1 triệu dòng | Vấn đề ổn định | Chỉ số benchmark | Chất lượng code | Nghiên cứu |
| Trọng tâm | Ràng buộc khai báo | Quản lý ngữ cảnh | Không phụ thuộc model | Ràng buộc ngầm | Chính thức hóa |
| Khái niệm độc đáo | Ưu tiên Agent | Context anxiety | Agent = Model + Harness | Tính thân thiện | Ranh giới ủy quyền |
| Mô hình Agent | Mở rộng song song | Agent đơn | Framework | Phụ thuộc codebase | Tách biệt mẫu |
Điểm mọi người đồng ý
- Những thứ bên ngoài mô hình quan trọng hơn bên trong.
- Ràng buộc nên được thực thi, không chỉ gợi ý.
- Vòng lặp phản hồi (feedback loops) là bắt buộc.
- Prompt engineering không biến mất (nó được chứa trong harness).
Điểm họ tranh luận
Đa agent vs Agent đơn:
- OpenAI: Mở rộng song song là tương lai.
- Anthropic: Một agent thông minh với harness phù hợp là đủ.
Độ chi tiết của Harness:
- OpenAI: Một harness bao bọc cả dự án.
- Böckeler: Một lần kiểm tra kiểu (type check) cũng được tính là harness.
"Thay thế" vs "Tiến hóa":
- Phe thay thế: "Agents đã lớn hơn những gì prompt có thể xử lý".
- Phe tiến hóa: "Không có sự khác biệt cơ bản — chỉ phản ánh khả năng tăng trưởng của LLM".
Vậy bạn thực sự nên làm gì vào ngày mai?
Sự khác biệt về cách hiểu là thú vị, nhưng các bước tiếp theo của bạn rất rõ ràng:
Bước 1: Viết file AGENTS.md / CLAUDE.md (Nếu chưa viết, hãy làm ngay hôm nay. 500 từ là đủ.)
Bước 2: Tự động hóa các cổng chất lượng (Bắt buộc chạy linters, kiểm tra kiểu và kiểm thử thông qua hooks.)
Bước 3: Chạy vòng lặp phản hồi (Agent mắc lỗi -> thêm ràng buộc vào AGENTS.md -> nó sẽ không lặp lại lỗi đó.)
Ba bước này có nghĩa là bạn đã đang thực hành Harness Engineering. Việc lo lắng về việc định nghĩa của công ty nào là "đúng" có thể để sau khi bạn đã chạy Bước 3 được ba tháng.


