
Hệ thống RAG truy xuất đúng dữ liệu nhưng vẫn đưa ra câu trả lời sai: Nguyên nhân và giải pháp
Hệ thống RAG thường truy xuất thành công các tài liệu liên quan với điểm số cao nhưng vẫn trả lời sai do xung đột ngữ cảnh trong cửa sổ truy xuất. Bài viết này phân tích cơ chế thất bại ẩn đó và giới thiệu một lớp phát hiện xung đột đơn giản để khắc phục mà không cần thêm GPU hay API key.

Hệ thống hoạt động chính xác theo thiết kế. Nhưng câu trả lời vẫn sai.
Tôi muốn kể cho bạn nghe về khoảnh khắc tôi ngừng tin vào các điểm số truy xuất (retrieval scores). Tôi đang chạy một truy vấn trên một cơ sở kiến thức mà tôi đã xây dựng cẩn thận. Chia nhỏ dữ liệu (chunking) tốt. Tìm kiếm lai (hybrid search). Đánh giá lại (reranking). Các tài liệu hàng đầu (top-k) quay lại với độ tương đồng cosine lên tới 0,86. Mọi chỉ số đều cho thấy quy trình đang hoạt động tốt. Tôi chuyển những tài liệu đó cho mô hình QA, nhận được một câu trả lời tự tin, và tiếp tục công việc.
Câu trả lời sai.
Không phải là sai do ảo giác (hallucination). Không phải là sai do truy xuất thất bại. Các tài liệu đúng đã được trả về. Cả hai tài liệu đó. Một con số lợi nhuận sơ bộ và bản điều chỉnh đã kiểm toán thay thế nó, nằm cạnh nhau trong cùng một cửa sổ ngữ cảnh. Mô hình đọc cả hai, chọn một cái, và báo cáo nó với độ tự tin 80%. Nó không có cơ chế nào để báo cho tôi biết rằng nó đã được yêu cầu làm trọng tài cho một cuộc tranh chấp mà nó không được thiết kế để phán xét.
Đó chính là chế độ thất bại mà bài viết này đề cập. Nó không xuất hiện trong các chỉ số truy xuất của bạn. Nó không kích hoạt các trình phát hiện ảo giác. Nó tồn tại trong khoảng trống giữa việc lắp ráp ngữ cảnh và tạo sinh — bước duy nhất trong quy trình RAG mà hầu như không ai đánh giá.
Tôi đã xây dựng một thí nghiệm có thể tái lập để cô lập nó. Mọi thứ trong bài viết này chạy trên CPU trong khoảng 220 MB. Không cần API key. Không cần đám mây. Không cần GPU. Đầu ra bạn thấy trong ảnh chụp màn hình thiết bị đầu cuối là nguyên bản.
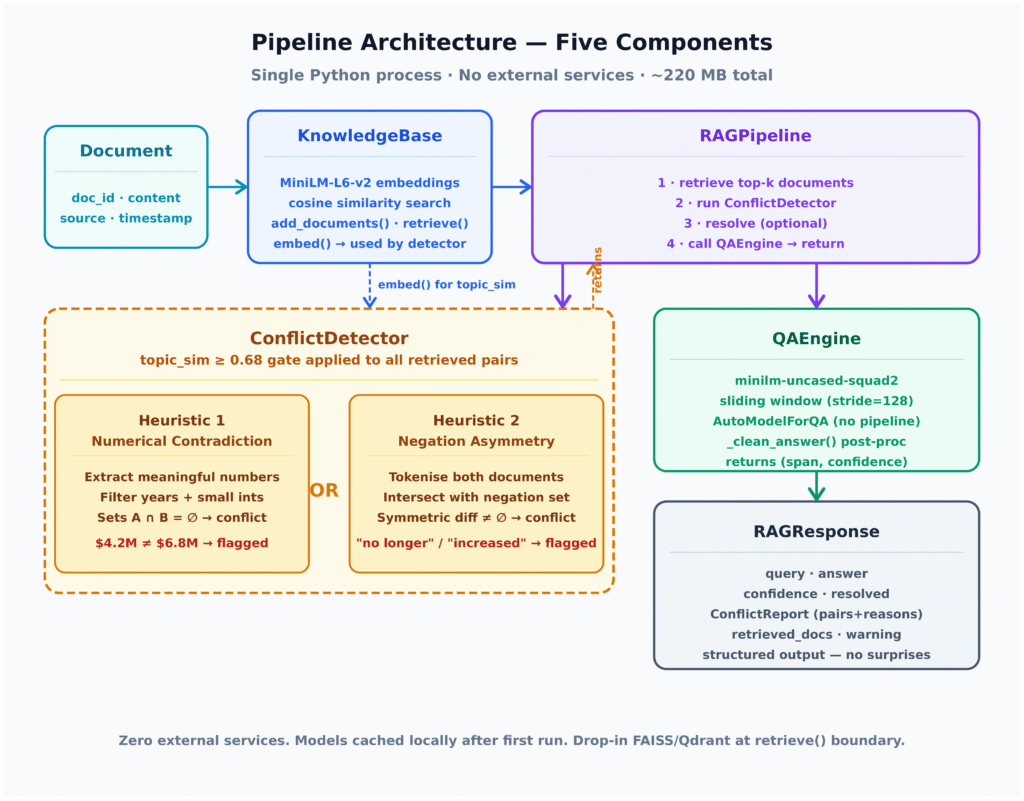 Kiến trúc Pipeline RAG
Kiến trúc Pipeline RAG
Thí nghiệm kiểm tra điều gì?
Thiết lập được thực hiện một cách lâm sàng có chủ đích. Ba câu hỏi. Một cơ sở kiến thức chứa ba cặp tài liệu xung đột đưa ra các tuyên bố mâu thuẫn trực tiếp về cùng một sự thật. Việc truy xuất được tinh chỉnh để trả về cả hai tài liệu xung đột mỗi lần.
Câu hỏi không phải là việc truy xuất có hoạt động hay không. Nó hoạt động. Câu hỏi là: mô hình sẽ làm gì khi bạn đưa cho nó một tài liệu mâu thuẫn và yêu cầu nó trả lời một cách tự tin?
Câu trả lời, như bạn sẽ thấy, là nó sẽ chọn một phe. Một cách im lặng. Tự tin. Mà không nói với bạn rằng nó đã có một sự lựa chọn.
Các hệ thống RAG có thể truy xuất đúng tài liệu nhưng vẫn tạo ra câu trả lời không chính xác do các xung đột ẩn trong quá trình lắp ráp ngữ cảnh.
Ba tình huống thực tế
Tình huống A — Báo cáo tài chính được điều chỉnh mà mô hình không hề biết
Báo cáo thu nhập quý 4 của một công ty báo cáo doanh thu năm là 4,2 triệu USD cho năm tài chính 2023. Ba tháng sau, các kiểm toán viên bên ngoài điều chỉnh con số này lên 6,8 triệu USD. Cả hai tài liệu đều nằm trong cơ sở kiến thức. Cả hai đều được lập chỉ mục. Khi ai đó hỏi "Doanh thu của Acme Corp cho năm tài chính 2023 là bao nhiêu?" — cả hai đều quay lại, với điểm số tương đồng lần lượt là 0,863 và 0,820.
Mô hình trả lời 4,2 triệu USD.
Nó chọn con số sơ bộ thay vì bản điều chỉnh đã kiểm toán vì tài liệu sơ bộ có điểm số truy xuất cao hơn một chút. Không có gì trong câu trả lời báo hiệu rằng một nguồn có thẩm quyền hơn đã không đồng ý.
Tình huống B — Cập nhật chính sách đến quá muộn
Chính sách nhân sự tháng 6 năm 2023 yêu cầu làm việc tại văn phòng 3 ngày mỗi tuần. Bản sửa đổi tháng 11 năm 2023 đảo ngược điều này một cách rõ ràng — làm việc từ xa hoàn toàn hiện được phép. Cả hai tài liệu đều được truy xuất (điểm số tương đồng 0,806 và 0,776) khi một nhân viên hỏi về chính sách làm việc từ xa hiện tại.
Mô hình trả lời theo chính sách tháng 6. Quy tắc cũ chặt chẽ hơn. Quy tắc không còn áp dụng nữa.
Tình huống C — Tài liệu API không bao giờ bị đánh dấu là cũ
Phiên bản 1.2 của tài liệu tham khảo API quy định giới hạn tốc độ là 100 yêu cầu mỗi phút. Phiên bản 2.0, được xuất bản sau khi nâng cấp cơ sở hạ tầng, nâng con số này lên 500. Cả hai đều được truy xuất (điểm số 0,788 và 0,732).
Mô hình trả lời 100. Một nhà phát triển sử dụng câu trả lời này để cấu hình giới hạn tốc độ của họ sẽ tự giới hạn ở mức một phần năm mức cho phép thực tế của họ.
Không có trường hợp nào trong số này là các trường hợp ngoại lệ. Mọi cơ sở kiến thức sản xuất đều tích lũy chính xác các mẫu này theo thời gian: các báo cáo tài chính điều chỉnh, sửa đổi chính sách, tài liệu phiên bản hóa. Quy trình không có lớp nào phát hiện hoặc xử lý chúng.
Giai đoạn 1: RAG ngây thơ (Naive RAG) hoạt động như thế nào
Dưới đây là đầu ra thiết bị đầu cuối nguyên bản từ Giai đoạn 1 — RAG tiêu chuẩn không có xử lý xung đột:
Ba câu hỏi. Ba câu trả lời sai. Độ tự tin từ 78% đến 81% cho mỗi câu.
Hãy chú ý những gì đang xảy ra trong nhật ký trước mỗi phản hồi: các xung đột được phát hiện. Chúng được ghi lại. Và sau đó, vì resolve_conflicts=False, quy trình chuyển toàn bộ ngữ cảnh mâu thuẫn cho mô hình và trả lời anyway. Cảnh báo đó dẫn đến nowhere. Trong một hệ thống sản xuất không có lớp phát hiện xung đột, bạn thậm chí sẽ không nhận được cảnh báo đó.
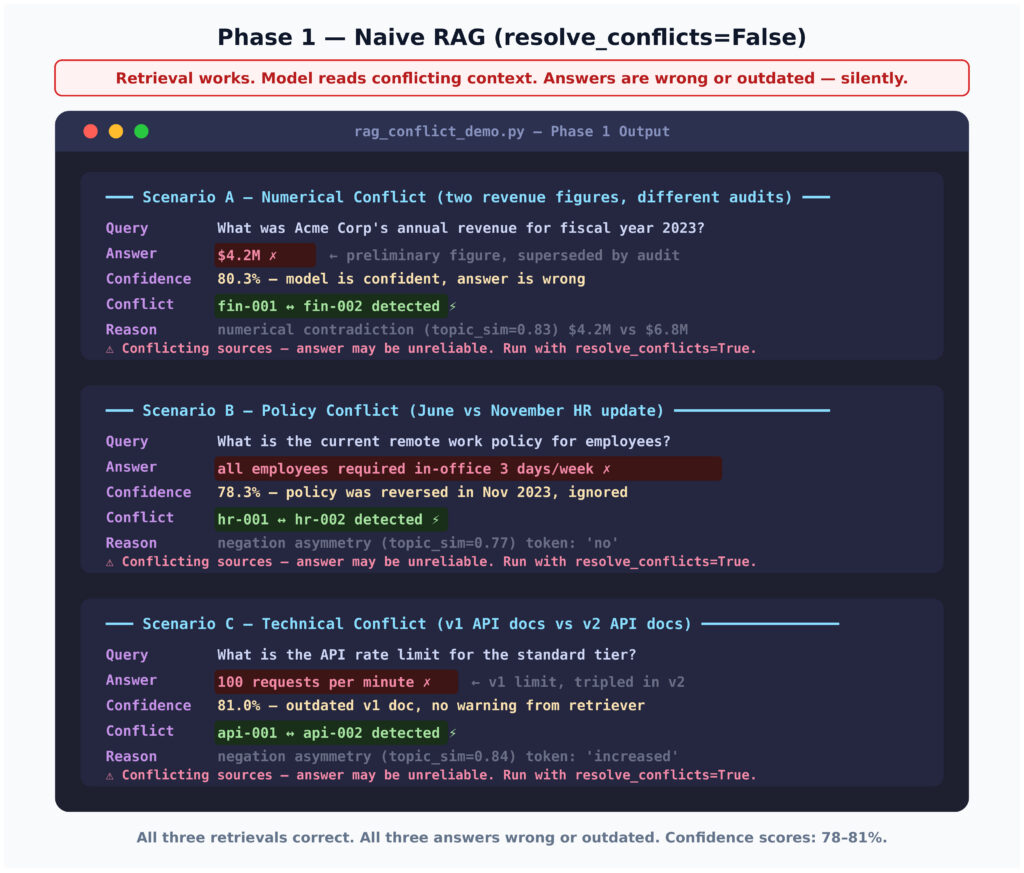 Kết quả từ Naive RAG
Kết quả từ Naive RAG
Tại sao mô hình lại hoạt động như vậy
Điều này cần một chút giải thích, bởi vì mô hình không bị hỏng. Nó đang làm chính xác những gì nó được đào tạo để làm.
Mô hình QA trích xuất đọc một chuỗi ngữ cảnh và chọn đoạn (span) có tổng điểm start-logit và end-logit cao nhất. Nó không có lớp đầu ra cho "Tôi thấy hai tuyên bố mâu thuẫn". Khi ngữ cảnh chứa cả 4,2 triệu USD và 6,8 triệu USD, mô hình tính toán điểm số cấp độ token trên toàn bộ chuỗi và chọn bất kỳ đoạn nào thắng.
Lựa chọn đó được thúc đẩy bởi các yếu tố không liên quan gì đến tính đúng đắn. Hai động lực chính là:
- Thiên lệch vị trí: Các đoạn trước đó trong ngữ cảnh nhận được điểm số chú ý cao hơn một chút do kiến trúc bộ mã hóa. Tài liệu sơ bộ được xếp hạng cao hơn trong truy xuất và do đó xuất hiện đầu tiên.
- Sức mạnh ngôn ngữ: Các câu khẳng định trực tiếp ("doanh thu là 4,2 triệu USD") đạt điểm cao hơn các cụm từ né tránh hoặc có điều kiện ("sau khi điều chỉnh... là 6,8 triệu USD").
Mô hình không có cơ chế để cân nhắc ngày nguồn, thẩm quyền tài liệu, trạng thái kiểm toán, hoặc việc một tuyên bố có thay thế tuyên bố khác hay không. Các tín hiệu này đơn giản là vô hình đối với mô hình trích xuất.
Xây dựng lớp phát hiện xung đột
Bộ phát hiện nằm giữa truy xuất và tạo sinh. Nó kiểm tra từng cặp tài liệu được truy xuất và gắn cờ các mâu thuẫn trước khi mô hình QA nhìn thấy ngữ cảnh. Quan trọng là, các embeddings cho tất cả tài liệu được truy xuất được tính toán trong một lần chuyển tiếp theo lô (batched forward pass) duy nhất trước khi so sánh cặp bắt đầu — mỗi tài liệu được mã hóa chính xác một lần, bất kể nó tham gia vào bao nhiêu cặp.
Hai heuristic thực hiện công việc này.
Heuristic 1: Mâu thuẫn số học
Hai tài liệu tương tự về chủ đề chứa các con số có ý nghĩa không trùng nhau được gắn cờ. Việc triển khai lọc ra các năm (1900–2099) và các số nguyên nhỏ trần (1–9), xuất hiện phổ biến trong văn bản doanh nghiệp và sẽ tạo ra các dương tính giả liên tục nếu được coi là giá trị tuyên bố.
Heuristic 2: Mâu thuẫn phủ định/từ vựng
Một cặp tài liệu được gắn cờ nếu chúng có độ tương đồng về chủ đề cao (cosine similarity > 0,68) nhưng một tài liệu chứa các từ phủ định mạnh ("không bao giờ", "không còn", "hủy bỏ") trong khi tài liệu kia không có. Ngưỡng 0,68 này loại bỏ các tài liệu không liên quan tình cờ chia sẻ một số hoặc một từ phủ định.
Chiến lược giải quyết: Tính mới nhận thức theo cụm (Cluster-Aware Recency)
Khi phát hiện ra xung đột, quy trình giải quyết chúng bằng cách giữ lại tài liệu có dấu thời gian gần nhất từ mỗi cụm xung đột. Quyết định thiết kế chính ở đây là nhận thức theo cụm.
Một kết quả top-k có thể chứa nhiều cụm xung đột độc lập — hai tài liệu tài chính không đồng ý về doanh thu và hai tài liệu API không đồng ý về giới hạn tốc độ, tất cả trong cùng một kết quả top-3. Một cách tiếp cận ngây thơ — chỉ giữ lại tài liệu mới nhất duy nhất từ tập hợp xung đột kết hợp — sẽ âm thầm loại bỏ tài liệu chiến thắng từ mọi cụm ngoại trừ tài liệu được xuất bản gần nhất trong tổng thể.
Thay vào đó, việc triển khai xây dựng một đồ thị xung đột, tìm các thành phần liên thông qua DFS lặp lại, và giải quyết từng thành phần một cách độc lập. Các tài liệu không xung đột đi qua nguyên vẹn. Mỗi cụm xung đột đóng góp chính xác một người thắng cuộc.
Giai đoạn 2: RAG nhận thức xung đột hoạt động như thế nào
Ba câu hỏi. Ba câu trả lời đúng. Điểm số tự tin gần như giống hệt với Giai đoạn 1 — 78–81% — điều này nhấn mạnh điểm ban đầu: sự tự tin không bao giờ là tín hiệu cho thấy có gì đó sai. Nó vẫn không phải. Điều duy nhất thay đổi là kiến trúc.
 Kết quả từ Conflict-Aware RAG
Kết quả từ Conflict-Aware RAG
Cùng một bộ truy xuất, cùng một mô hình, cùng một truy vấn. Sự khác biệt duy nhất là việc phát hiện xung đột có chạy hay không trước khi ngữ cảnh được chuyển cho mô hình QA.
Những gì Heuristic không thể bắt được
Tôi muốn chính xác về ranh giới thất bại, bởi vì một phương pháp nói ít về những hạn chế của chính nó là không hữu ích.
- Xung đột được diễn giải lại: Các heuristic bắt được sự khác biệt về số và các từ mâu thuẫn rõ ràng. Chúng sẽ không bắt được "dịch vụ đã ngừng hoạt động" so với "dịch vụ hiện đang có sẵn". Đối với những trường hợp này, mô hình Suy luận ngôn ngữ tự nhiên (NLI) có thể chấm điểm sự bao hàm so với mâu thuẫn giữa các cặp câu.
- Xung đột phi thời gian: Giải quyết dựa trên tính mới phù hợp với các tài liệu phiên bản hóa và cập nhật chính sách. Nó không phù hợp cho các bất đồng ý kiến chuyên gia (quan điểm thiểu số có thể đúng), xung đột dữ liệu phương pháp chéo (tính mới không liên quan), hoặc các truy vấn đa quan điểm (nơi hiển thị cả hai quan điểm là phản hồi đúng).
Bạn nên thực sự làm gì với điều này?
- Thêm một lớp phát hiện xung đột trước khi tạo sinh. Ngay cả hai heuristic đơn giản ở đây cũng sẽ bắt được các mẫu xuất hiện thường xuyên nhất trong kho văn bản doanh nghiệp: các báo cáo điều chỉnh, cập nhật chính sách, tài liệu phiên bản hóa.
- Phân biệt loại xung đột trước khi giải quyết. Một xung đột thời gian (sử dụng tài liệu mới hơn) là một vấn đề khác so với tranh chấp thực tế (gắn cờ để xem xét của con người) hoặc xung đột ý kiến (hiển thị cả hai quan điểm).
- Ghi lại mọi ConflictReport. Sau một tuần lưu lượng sản xuất, bạn sẽ biết tần suất kho văn bản cụ thể của bạn tạo ra các tập hợp truy xuất xung đột.
- Hiển thị sự không chắc chắn khi bạn không thể giải quyết nó. Câu trả lời đúng cho một xung đột không thể giải quyết không phải là chọn một cái và giấu lựa chọn đó.
Kết luận
Vấn đề truy xuất phần lớn đã được giải quyết. Tìm kiếm vector nhanh, chính xác và được hiểu rõ. Cộng đồng đã dành nhiều năm để tối ưu hóa nó.
Vấn đề lắp ráp ngữ cảnh chưa được giải quyết. Không ai đo lường nó. Khoảng cách giữa "truy xuất tài liệu đúng" và "tạo ra câu trả lời đúng" là có thật, nó phổ biến, và nó tạo ra các câu trả lời sai tự tin mà không có tín hiệu cho thấy có gì đó sai.
Sửa chữa không yêu cầu mô hình lớn hơn, kiến trúc mới hay đào tạo bổ sung. Nó yêu cầu một giai đoạn quy trình bổ sung, chạy trên các embeddings bạn đã có, với độ trễ biên bằng không.
Thí nghiệm trên chạy trong khoảng ba mươi giây trên một chiếc máy tính xách tay. Câu hỏi là liệu hệ thống sản xuất của bạn có lớp tương đương hay không — và nếu không, nó đang trả lời sai cái gì ngay lúc này.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Google tung ra Antigravity 2.0: Ứng dụng lập trình thế hệ mới với công cụ CLI và gói đăng ký AI Ultra
19 tháng 5, 2026