
Học tăng cường (Reinforcement Learning) với Unity: Hướng dẫn xây dựng tác nhân thông minh
Bài viết này hướng dẫn bạn cách xây dựng một tác nhân Học tăng cường (Reinforcement Learning) sử dụng thuật toán Q-Learning trong Unity. Chúng ta sẽ đi sâu vào các nguyên lý toán học như phương trình Bellman và chiến lược khám phá/khai thác để giúp một robot tự học cách điều hướng trong môi trường giả lập.
Học tăng cường (Reinforcement Learning - RL) là một trong những phương pháp học máy thú vị nhất vì nó mô phỏng cách con người và động vật học hỏi thông qua quan sát và phần thưởng. Tuy nhiên, đây cũng là một lĩnh vực phức tạp và đầy thách thức. Để giúp bạn tiếp cận chủ đề này, bài viết sẽ hướng dẫn xây dựng một ví dụ từng bước về một tác nhân (agent) học cách điều hướng trong môi trường sử dụng thuật toán Q-Learning trên nền tảng Unity.
 Mô phỏng môi trường học máy
Mô phỏng môi trường học máy
Học tăng cường là gì?
Trong RL, chúng ta có một tác nhân có khả năng thực hiện hành động, quan sát kết quả và học hỏi từ các phần thưởng hoặc hình phạt. Quyết định hành động của tác nhân ở một trạng thái cụ thể phụ thuộc vào "chính sách" (policy) của nó. Một chính sách π là một hàm ánh xạ từ trạng thái sang hành động.
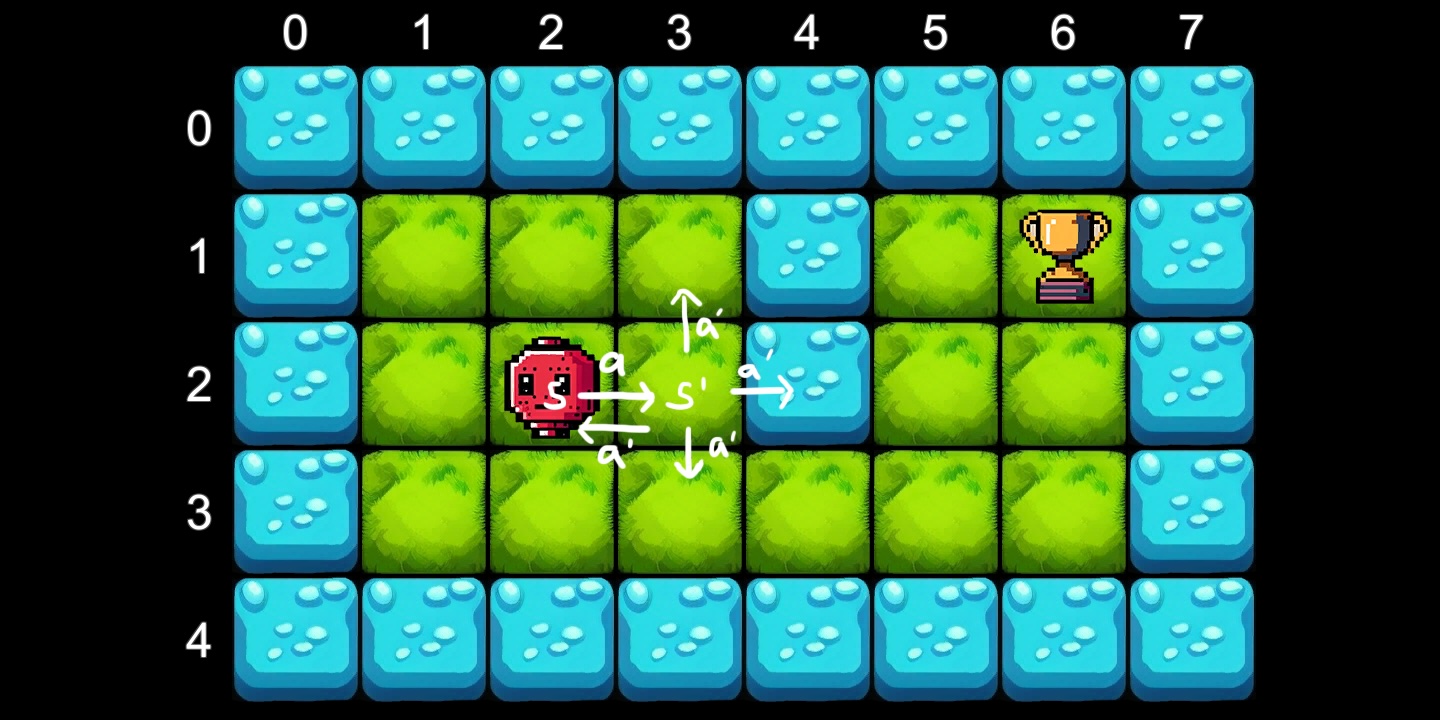
Để minh họa, hãy tưởng tượng một robot cần tìm đường trong một lưới 2D. Robot có thể thực hiện 4 hành động: Trái, Phải, Lên, Xuống. Mục tiêu là tìm đến phần thưởng (cúp) mà không rơi xuống nước.
Phương trình Bellman và Giá trị Trạng thái
Vấn đề tìm kiếm chính sách tối ưu có thể được giải quyết bằng phương trình Bellman. Về cơ bản, phương trình này phát biểu rằng phần thưởng dài hạn của một hành động bằng phần thưởng ngay lập tức cộng với phần thưởng kỳ vọng từ tất cả các hành động trong tương lai.
Trong ví dụ của chúng ta, chúng ta sử dụng một hệ số giảm dần (gamma) để quy định giá trị của phần thưởng tương lai so với phần thưởng hiện tại. Quá trình tính toán diễn ra lặp đi lặp lại: trên mỗi lần lặp, chúng ta tính toán phần thưởng tương lai dự kiến cho tất cả các ô trên lưới. Giá trị này sẽ lan truyền từ ô phần thưởng ra ngoài, giúp tác nhân biết được ô nào có giá trị cao để hướng tới.
 Quá trình tính toán giá trị
Quá trình tính toán giá trị
Q-Learning: Chất lượng Hành động
Thay vì chỉ đánh giá giá trị của trạng thái (ô lưới), Q-Learning tập trung vào việc đánh giá chất lượng của một hành động cụ thể tại một trạng thái cụ thể. Đây được gọi là Q-value.
Thuật toán cập nhật Q-value dựa trên sự khác biệt thời gian (temporal difference). Tác nhân sẽ xem xét hành động hiện tại, phần thưởng nhận được và hành động tốt nhất có thể thực hiện ở trạng thái tiếp theo. Công thức cập nhật sử dụng một hệ số học tập (alpha) để xác định tốc độ thông tin mới ghi đè thông tin cũ.
Khám phá và Khai thác (Exploration vs. Exploitation)
Một thách thức lớn trong Q-Learning là sự đánh đổi giữa việc khai thác (exploit) và khám phá (explore).
- Khai thác: Chọn hành động có Q-value cao nhất (tham lam).
- Khám phá: Chọn một hành động ngẫu nhiên để tìm ra những con đường tốt hơn chưa được khám phá.
Nếu tác nhân chỉ khai thác, nó có thể bị mắc kẹt trong một tối ưu cục bộ. Để giải quyết, chúng ta sử dụng chiến lược ε-Greedy (Epsilon-tham lam). Ban đầu, epsilon cao để khuyến khích khám phá ngẫu nhiên. Theo thời gian, epsilon giảm dần để tác nhân chuyển sang khai thác những kiến thức đã học.
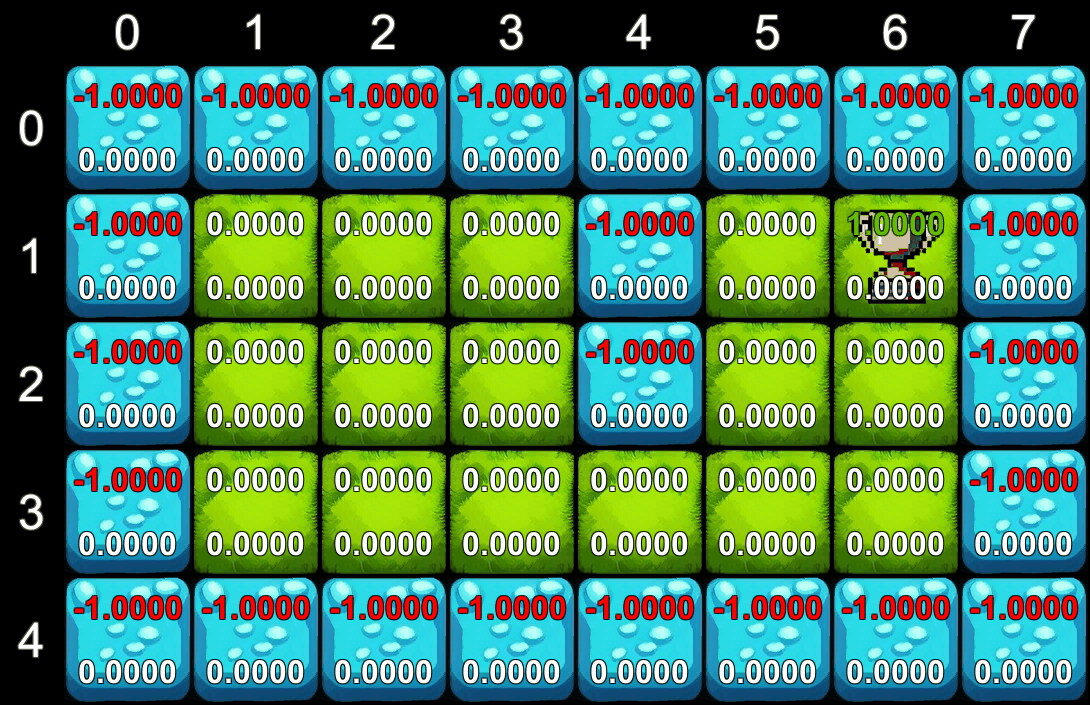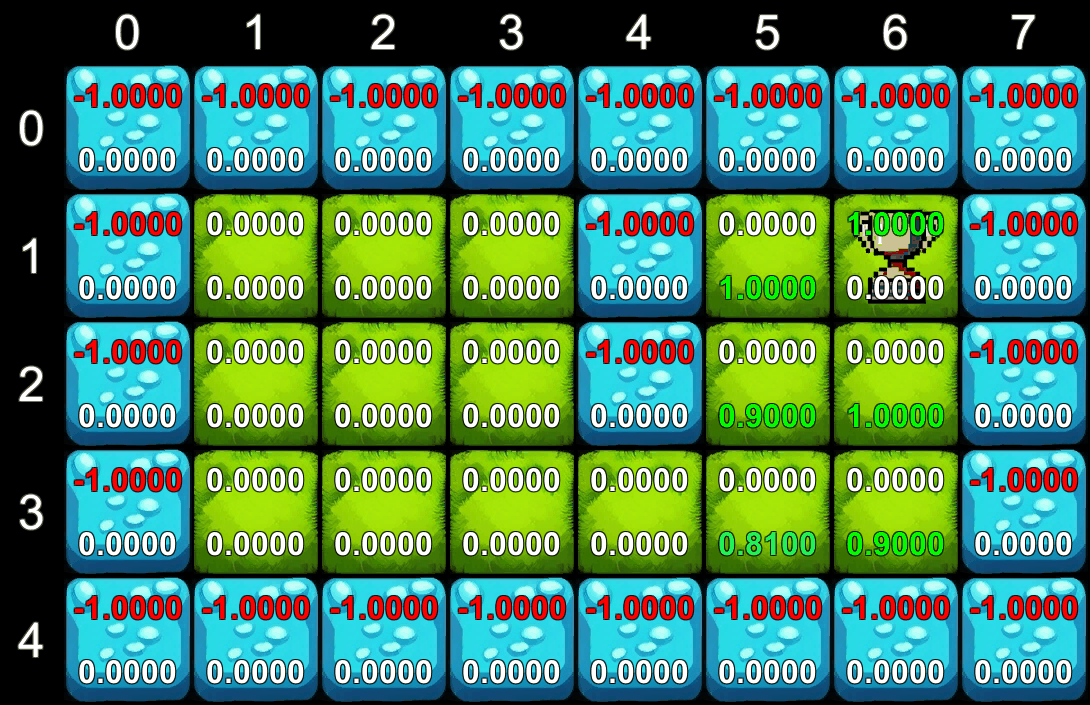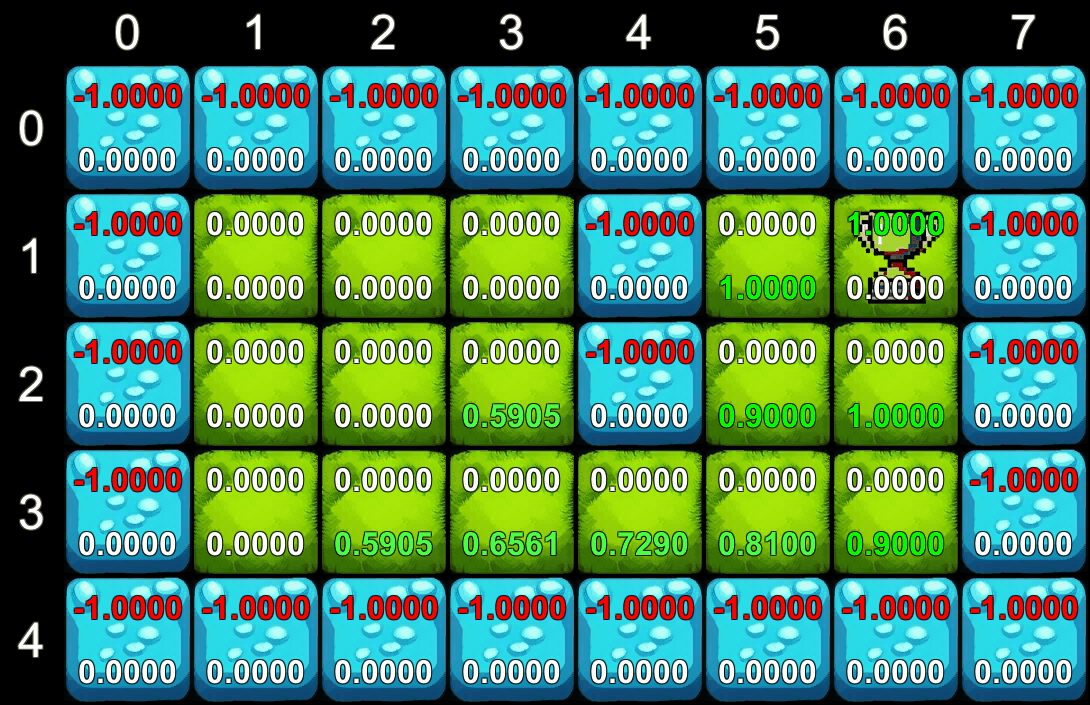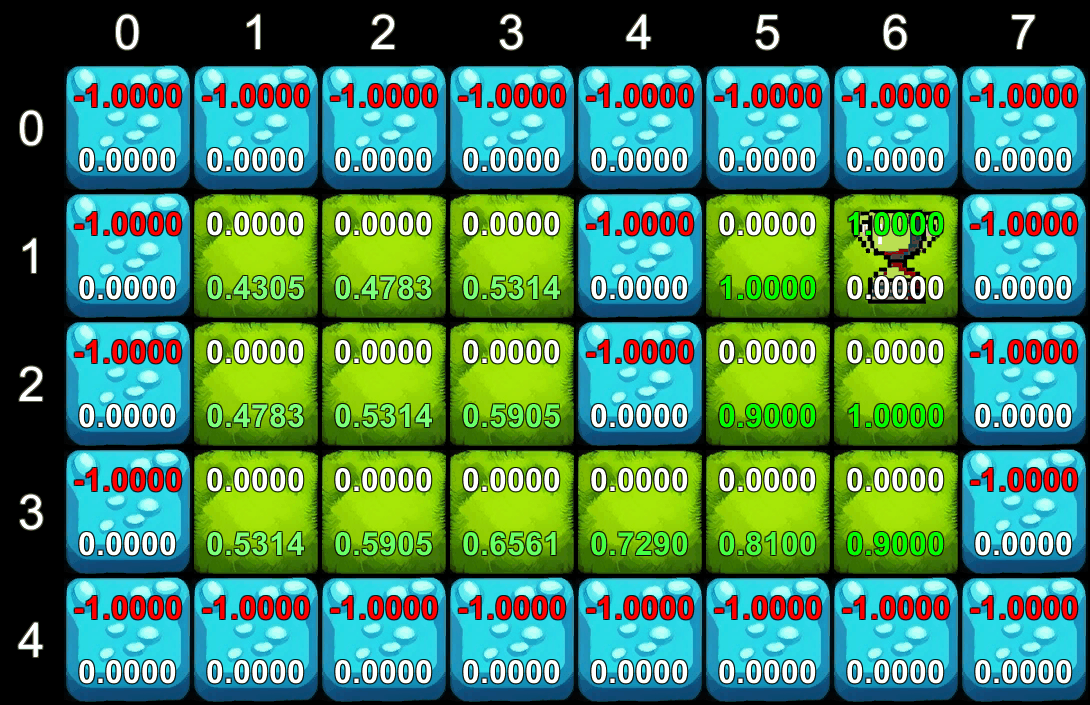 Quá trình học tập của tác nhân
Quá trình học tập của tác nhân
Mở rộng: Deep Q-Networks (DQN)
Q-Learning hoạt động tốt với không gian trạng thái rời rạc và nhỏ (như lưới 8x5 trong ví dụ). Tuy nhiên, với các trò chơi phức tạp như Cờ vua, số lượng trạng thái là khổng lồ, khiến việc lưu trữ bảng Q-value bất khả thi.
Trong những trường hợp này, các phương pháp như Deep Q-Networks (DQN) được sử dụng. Thay vì một bảng, DQN sử dụng một mạng nơ-ron (neural network) để nén thông tin. Mạng nơ-ron nhận trạng thái làm đầu vào và xuất ra Q-values cho tất cả các hành động, cho phép tổng quát hóa qua các trạng thái tương tự mà nó chưa từng thấy.
Kết luận
Việc xây dựng một tác nhân RL trong Unity không chỉ giúp hiểu rõ lý thuyết mà còn thấy được ứng dụng thực tế của AI trong phát triển game. Từ những khái niệm cơ bản như phương trình Bellman đến Q-Learning và DQN, cánh cửa để tạo ra những nhân vật AI thông minh trong game đang dần mở ra.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026