
Học tăng cường: Sự khác biệt cốt lõi giữa On-Policy và Off-Policy
Trong Học tăng cường, việc lựa chọn giữa phương pháp On-Policy và Off-Policy ảnh hưởng trực tiếp đến cách mô hình khám phá, hiệu quả sử dụng dữ liệu và độ an toàn. Bài viết này sẽ phân tích sâu sắc hai khái niệm này thông qua các ví dụ kinh điển như SARSA và Q-learning.

Học tăng cường (Reinforcement Learning - RL) thường được giới thiệu qua một danh sách dài các thuật toán: SARSA, Q-learning, PPO, DQN, SAC... Mỗi cái tên gợi ý một phương pháp khác nhau, một mẹo toán học riêng biệt. Tuy nhiên, cốt lõi của nhiều thuật toán này xoay quanh một câu hỏi đơn giản hơn nhiều:
Tác nhân (agent) nên chỉ học từ hành vi mà nó đang thực hiện, hay cũng có thể học từ hành vi được tạo ra theo cách khác?
Đó chính là sự khác biệt trung tâm giữa việc học On-Policy và Off-Policy. Sự lựa chọn này không chỉ là thuật ngữ, mà nó ảnh hưởng trực tiếp đến các thuộc tính quan trọng nhất của thuật toán học tập: cách nó khám phá, lượng dữ liệu cần thiết, khả năng học từ kinh nghiệm cũ và sự ổn định trong quá trình huấn luyện.
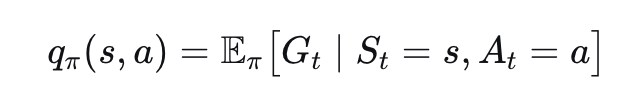 Khái niệm cơ bản trong Học tăng cường
Khái niệm cơ bản trong Học tăng cường
Chính sách (Policy) và Cách học
Để làm rõ sự phân chia này, chúng ta cần một định nghĩa cơ bản. Trong Học tăng cường, chính sách (policy) là quy tắc hoặc chiến lược mà tác nhân sử dụng để quyết định hành động nào sẽ thực hiện trong mỗi tình huống.
Khi khái niệm này rõ ràng, sự tương phản trở nên dễ thấy hơn:
- Phương pháp On-Policy: Học từ cùng một chiến lược mà tác nhân đang theo đuổi.
- Phương pháp Off-Policy: Tách biệt hai khái niệm này. Tác nhân có thể hành động theo một chiến lược (chính sách hành vi) trong khi học về một chiến lược khác (chính sách mục tiêu).
Hãy tưởng tượng bạn đang học chơi cờ vua.
- Tiếp cận On-Policy: Giống như việc cải thiện kỹ năng bằng cách phân tích chính các nước đi bạn thực hiện trong các ván đấu thực tế.
- Tiếp cận Off-Policy: Giống như việc chơi theo một phong cách nhất định trong lúc luyện tập, nhưng lại nghiên cứu hậu quả của các nước đi mạnh hơn từ hồ sơ ván đấu hoặc ví dụ của các kỳ thủ chuyên nghiệp.
Học chênh lệch thời gian (Temporal-Difference Learning)
Trước khi so sánh SARSA và Q-learning, chúng ta cần hiểu nền tảng chung của chúng: Học chênh lệch thời gian (TD Learning). Đây là phương pháp cập nhật kiến thức từ kinh nghiệm mà không cần đợi đến khi kết thúc một tập (episode).
Công thức cập nhật cơ bản của TD cho giá trị trạng thái V(s) là:
V(St) ← V(St) + α [Rt+1 + γV(St+1) − V(St)]
Trong đó, phần trong ngoặc vuông được gọi là TD error (sai số TD) - thước đo về sự "ngạc nhiên" của tác nhân. Nếu sai số dương, kết quả tốt hơn dự kiến; nếu âm, kết quả tệ hơn.
Cả SARSA và Q-learning đều là các phương pháp điều khiển TD (TD control). Sự khác biệt cốt lõi nằm ở mục tiêu mà chúng "bootstrap" (tự khởi tạo) từ đó.
SARSA: Học từ những lựa chọn của chính mình (On-Policy)
SARSA là thuật toán điều khiển TD cổ điển thuộc loại On-Policy. Tên của nó xuất phát từ bộ dữ liệu nó sử dụng: (State, Action, Reward, next State, next Action).
Quy tắc cập nhật của SARSA là:
Q(St,At) ← Q(St,At) + α[Rt+1+γ Q(St+1,At+1)−Q(St,At)]
Điểm mấu chốt ở đây là Q(St+1, At+1) - giá trị của hành động mà tác nhân thực sự sẽ thực hiện ở bước tiếp theo. Nếu tác nhân sử dụng chính sách ε-greedy (tham lam nhưng đôi khi ngẫu nhiên), SARSA sẽ học giá trị của chính sách ε-greedy đó, bao gồm cả những khiếm khuyết của nó.
Ví dụ: Đi bộ trên vách đá (Cliff Walking)
Hãy tưởng tượng một lưới ô vuông: Điểm bắt đầu là S, đích là G. Mỗi bước đi bị trừ -1 điểm. Nếu đi vào vực (cliff), bạn bị trừ -100 điểm và quay về S.
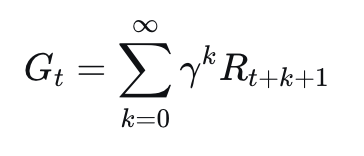 Ví dụ bài toán Cliff Walking
Ví dụ bài toán Cliff Walking
Chúng ta có hai chiến lược rõ ràng:
- Đường an toàn: Đi lên trên, vòng xa khỏi vực.
- Đường sát vực: Đi dọc theo hàng dưới cùng thẳng đến đích.
SARSA học đường an toàn. Tại sao? Vì nó biết mình đôi khi sẽ thực hiện các hành động ngẫu nhiên. Nếu đi sát vực, đôi khi nó sẽ vấp ngã. Các ước tính giá trị của SARSA phản ánh rủi ro đó, do đó nó ưu tiên con đường đi vòng trong nội địa.
Q-Learning: Tưởng tượng về một tương lai hoàn hảo (Off-Policy)
Q-learning đảo ngược kịch bản. Quy tắc cập nhật của nó sử dụng giá trị tối đa trên tất cả các hành động có thể thực hiện tiếp theo:
Q(St,At) ← Q(St,At) + α[Rt+1+γ max_a Q(St+1,a)−Q(St,At)]
Đây là nước đi Off-Policy. Tác nhân có thể đang loạng choạng với chính sách ε-greedy, nhưng các cập nhật của nó hoạt động như thể nó sẽ hành động tối ưu từ bước tiếp theo trở đi.
Trong ví dụ Cliff Walking, Q-learning học đường sát vực. Nó tưởng tượng một tương lai nơi nó hành động hoàn hảo - không có vấp ngã ngẫu nhiên. Trong thế giới hoàn hảo đó, đi sát vực là ổn vì một tác nhân hoàn hảo không bao giờ rơi xuống. Toán tử max giả định hành vi tối ưu ở mọi bước tương lai, do đó rủi ro thám hiểm biến mất khỏi các ước tính của nó.
Điều này có ý nghĩa gì trong thực tế? Trong quá trình huấn luyện, Q-learning thường hoạt động kém trực tuyến hơn SARSA. Nó đi nguy hiểm gần vực và đôi khi rơi xuống, chịu nhiều hình phạt lớn. Tuy nhiên, sau khi huấn luyện xong (khi tắt khám phá), Q-learning đi đường tối ưu ngắn nhất. SARSA thì bám vào con đường an toàn dài hơn.
Expected SARSA: Lấy cái hay từ cả hai
Có một thuật toán thứ ba nằm ngay giữa SARSA và Q-learning: Expected SARSA. Nó sử dụng kỳ vọng trên tất cả các hành động tiếp theo thay vì một mẫu đơn lẻ hoặc một giá trị tối đa.
- Nó giảm phương sai (variance) so với SARSA vì lấy trung bình.
- Nó có thể là On-policy hoặc Off-policy tùy thuộc vào việc chính sách mục tiêu có trùng với chính sách hành vi hay không.
- Nó bao gồm Q-learning như một trường hợp đặc biệt (khi chính sách là tham lam).
Trong các thí nghiệm Cliff Walking, Expected SARSA thường đánh bại cả SARSA và Q-learning trên một phạm vi kích thước bước (step-size) rộng.
Khi nào nên dùng cái nào?
Hãy xem xét các yếu tố thực tế khi xây dựng hệ thống:
Hiệu quả mẫu và Tái sử dụng kinh nghiệm
Siêu năng lực của Off-policy là tái sử dụng dữ liệu cũ. Vì các cập nhật không giả định dữ liệu đến từ chính sách hiện tại, chúng ta có thể lưu trữ mọi chuyển đổi trong một bộ nhớ đệm (replay buffer) và lấy mẫu hàng nghìn lần. Đó là lý do DQN hoạt động tốt. Các phương pháp On-policy như PPO phải thu thập dữ liệu mới sau mỗi cập nhật, kém hiệu quả mẫu hơn.
Hiệu suất trực tuyến trong quá trình học
Nếu bạn triển khai một tác nhân phải hoạt động tốt ngay từ ngày đầu tiên, bạn có thể muốn phương pháp On-policy. SARSA (hoặc PPO) sẽ thận trọng và ổn định hơn khi học. Off-policy có thể khám phá quá mức và gây ra các hình phạt thực tế.
An toàn và Độ nhạy rủi ro
Đây là vấn đề lớn. SARSA tự nhiên xây dựng nhận thức rủi ro vì nó học từ việc thực thi không hoàn hảo của chính nó. Nếu biết tác nhân sẽ mắc lỗi, SARSA sẽ tránh các trạng thái mà lỗi là thảm khốc. Q-learning giả định thực thi hoàn hảo trong tương lai, do đó nó có thể trở nên quá tự tin một cách nguy hiểm.
Kết nối với Học sâu (Deep Learning)
Tất cả những điều này không chỉ là lý thuyết. Mọi thuật toán RL hiện đại đều kế thừa linh hồn của các phương pháp bảng (tabular) này:
- DQN: Q-learning với mạng nơ-ron, replay buffer và mạng mục tiêu. Hoàn toàn Off-policy.
- PPO: On-policy, ổn định, sử dụng dữ liệu mới mỗi lần.
- SAC: Off-policy actor-critic với phần thưởng entropy, sử dụng replay buffer để có hiệu quả mẫu cao.
Không có câu trả lời đúng cho mọi trường hợp. Nếu sự an toàn là ưu tiên hàng đầu, hãy chọn On-policy. Nếu hiệu quả dữ liệu là quan trọng nhất và bạn có thể chấp nhận sự hỗn loạn trong quá trình học, hãy chọn Off-policy. Hiểu rõ sự đánh đổi ở mức cơ bản sẽ giúp bạn đưa ra lựa chọn có ý thức khi xây dựng các hệ thống AI thông minh.
 So sánh các thuật toán học tăng cường
So sánh các thuật toán học tăng cường
Bài viết liên quan

Công nghệ
Samsung Galaxy Book6 Ultra: Bản sao MacBook Pro đắt đỏ nhưng đầy khiếm khuyết
07 tháng 5, 2026

Công nghệ
Xây dựng và Mở rộng Nền tảng với Mô hình Project-as-a-Service
11 tháng 6, 2026

Công nghệ
Tấn công mạng làm tê liệt nhà máy đường lớn tại Australia, nông dân không thể thu hoạch
17 tháng 6, 2026