
Hướng dẫn thực tế về Kiến trúc Bộ nhớ cho các Tác nhân LLM Tự chủ
Bài viết này khám phá tầm quan trọng của kiến trúc bộ nhớ trong các hệ thống tác nhân LLM tự chủ, lập luận rằng nó quan trọng hơn cả việc lựa chọn mô hình nền tảng. Tác giả phân tích các loại bộ nhớ theo thời gian, cơ chế hoạt động, các lỗi thường gặp và đưa ra những lời khuyên thực tế để xây dựng hệ thống bộ nhớ hiệu quả.
Tôi đã vận hành một hệ thống đa tác nhân phân tán (multi-agent system) trên cả OpenClaw và AWS AgentCore được một thời gian. Chỉ trong thiết lập OpenClaw của tôi, hệ thống đã bao gồm một tác nhân nghiên cứu, một tác nhân viết lách, một động cụ mô phỏng, một trình lập lịch heartbeat và nhiều thành phần khác. Chúng cộng tác không đồng bộ, chuyển ngữ cảnh thông qua các tệp chia sẻ và duy trì trạng thái xuyên suốt các phiên làm việc kéo dài ngày hoặc tuần.
Khi đưa thêm các hệ thống tác nhân khác như Claude Code hoặc các tác nhân tôi triển khai trên AgentCore, việc phối hợp, quản lý bộ nhớ và trạng thái trở nên ngày càng khó giải quyết.
Cuối cùng, tôi nhận ra một điều: hầu hết những gì làm cho các tác nhân này hoạt động thực sự không phải là lựa chọn mô hình. Mà đó là kiến trúc bộ nhớ.
Vì vậy, khi tôi bắt gặp bài viết "Memory for Autonomous LLM Agents: Mechanisms, Evaluation, and Emerging Frontiers" (arxiv 2603.07670), tôi rất tò mò xem liệu hệ thống phân loại chính thức có khớp với những gì tôi đã xây dựng dựa trên cảm tính và lặp lại hay không. Thực tế là nó khớp rất gần. Tuy nhiên, bài viết đã mã hóa hóa nhiều điều tôi tự mình khám phá được và giúp tôi nhận ra rằng một số khó khăn hiện tại của tôi không phải là duy nhất, mà đang được nhìn thấy rộng rãi hơn.
Hãy cùng đi qua bài khảo sát này và thảo luận về các phát hiện của nó cùng với kinh nghiệm thực tế của tôi.
Tại sao Bộ nhớ Quan trọng hơn Bạn Nghĩ
Bài báo bắt đầu với một quan sát thực nghiệm nên giúp bạn định lại ưu tiên nếu bạn chưa làm điều đó:
"Khoảng cách giữa 'có bộ nhớ' và 'không có bộ nhớ' thường lớn hơn khoảng cách giữa các xương sống LLM khác nhau."
Đây là một tuyên bố lớn. Việc thay đổi mô hình nền tảng quan trọng ít hơn việc tác nhân của bạn có thể ghi nhớ được những gì. Tôi đã cảm nhận điều này một cách trực giác, nhưng việc thấy nó được trình bày rõ ràng như vậy trong một bài khảo sát chính thức là rất hữu ích. Các chuyên gia thường dành năng lượng khổng lồ cho việc lựa chọn mô hình và tinh chỉnh prompt (prompt tuning), trong khi coi bộ nhớ là chuyện phụ. Đó là tư duy ngược.
Bài báo định hình bộ nhớ của tác nhân bên trong cấu trúc Quy trình quyết định Markov có thể quan sát một phần (POMDP), nơi bộ nhớ hoạt động như trạng thái niềm tin của tác nhân về một thế giới có thể quan sát một phần. Đó là một sự chính thức hóa gọn gàng. Trong thực tế, điều này có nghĩa là tác nhân không thể nhìn thấy mọi thứ, vì vậy nó xây dựng và duy trì một mô hình nội bộ về những gì là đúng. Bộ nhớ chính là mô hình đó. Nếu sai, mọi quyết định hạ nguồn sẽ bị suy giảm.
Vòng lặp Ghi - Quản lý - Đọc
Bài báo đặc tả bộ nhớ của tác nhân là một vòng lặp ghi - quản lý - đọc, không chỉ đơn thuần là "lưu trữ và truy xuất".
- Ghi (Write): Thông tin mới đi vào bộ nhớ (quan sát, kết quả, phản tư).
- Quản lý (Manage): Bộ nhớ được duy trì, cắt tỉa, nén và hợp nhất.
- Đọc (Read): Bộ nhớ liên quan được truy xuất và đưa vào ngữ cảnh.
Hầu hết các triển khai tôi thấy đều làm tốt "ghi" và "đọc" nhưng hoàn toàn bỏ quên "quản lý". Chúng tích lũy mà không có sự biên tập. Kết quả là nhiễu, mâu thuẫn và ngữ cảnh phình to. Quản lý là phần khó khăn, và đó là nơi hầu hết các hệ thống gặp khó khăn hoặc thất bại hoàn toàn.
Trước khi có các cải tiến gần đây của OpenClaw, tôi xử lý việc này bằng một chính sách kiểm soát heuristic: các quy tắc về những gì cần lưu trữ, những gì cần tóm tắt, khi nào cần nâng cấp lên bộ nhớ dài hạn và khi nào để dữ liệu cũ hết hạn. Nó không thanh lịch, nhưng nó buộc tôi phải rõ ràng về bước quản lý thay vì bỏ qua nó.
Trong các hệ thống khác tôi xây dựng, tôi thường dựa vào các cơ chế như Bộ nhớ Ngắn hạn/Dài hạn của AgentCore, Cơ sở dữ liệu Vector và các hệ thống Bộ nhớ tác nhân. Hệ thống bộ nhớ dựa trên tệp không mở rộng tốt cho các hệ thống phân tán lớn (mặc dù đối với các tác nhân hoặc chatbot đơn giản, điều này vẫn khả thi).
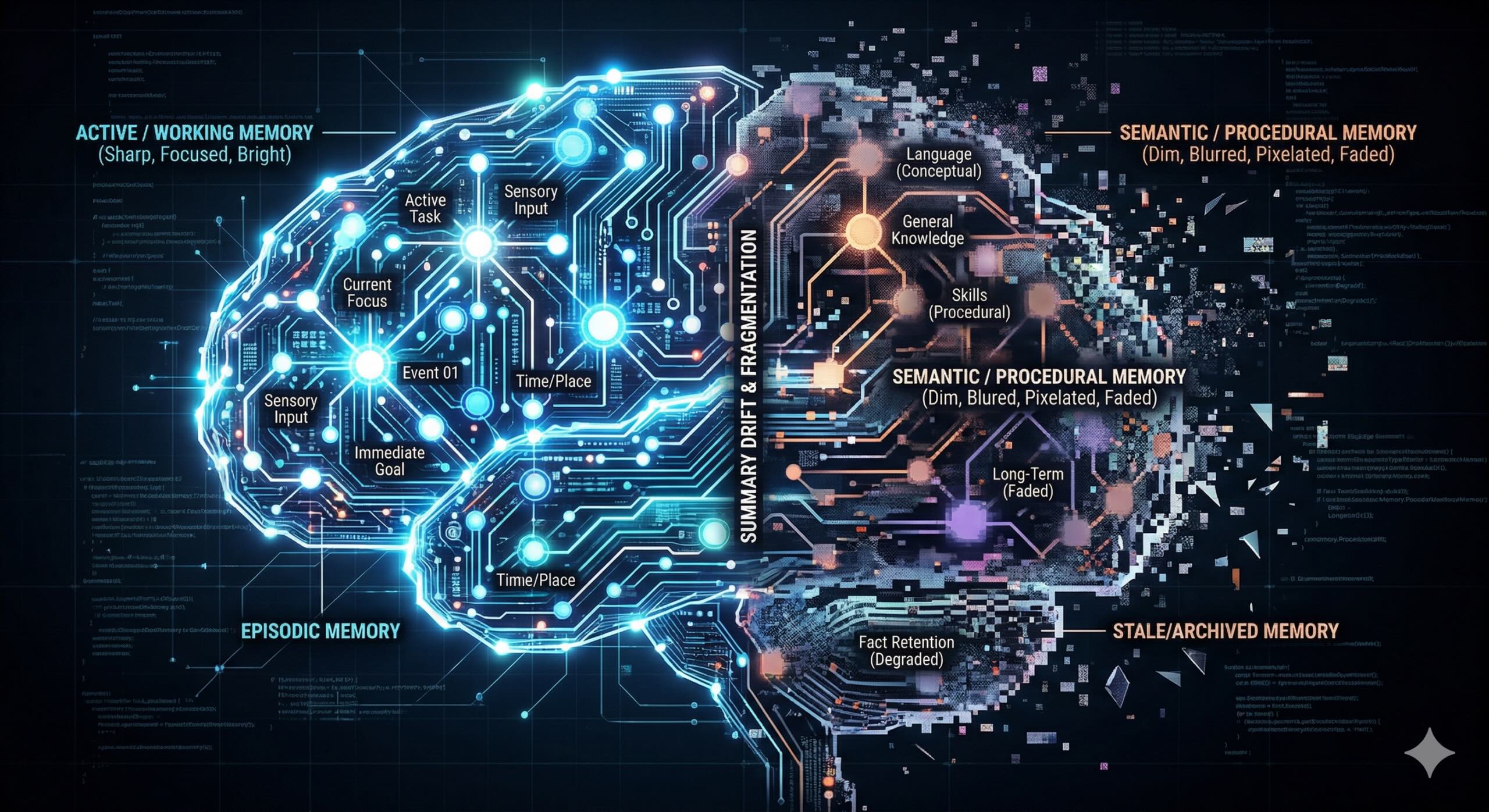
Bốn Phạm vi Thời gian (Và Nơi Tôi Thấy Chúng trong Thực tế)
Bài báo chia bộ nhớ thành bốn phạm vi thời gian.
Bộ nhớ làm việc (Working Memory)
Đây là cửa sổ ngữ cảnh (context window).
Nó ngắn hạn, băng thông cao và bị giới hạn. Mọi thứ sống ở đây một thời gian ngắn. Chế độ thất bại là sự loãng sự chú ý (attentional dilution) và hiệu ứng "mất ở giữa" (lost in the middle), nơi nội dung liên quan bị bỏ qua vì cửa sổ quá đông đúc. Tôi đã gặp phải vấn đề này, cũng như hầu hết các nhóm tôi đã làm việc cùng.
Khi ngữ cảnh của OpenClaw, Claude Code hoặc chatbot của bạn trở nên dài, hành vi của tác nhân sẽ suy giảm theo những cách khó gỡ lỗi vì về mặt kỹ thuật mô hình "có" thông tin đó nhưng không sử dụng nó. Điều phổ biến nhất tôi thấy từ các nhóm (và chính tôi) là tạo các luồng (thread) mới cho các phần công việc khác nhau. Bạn không giữ Claude Code mở cả ngày khi làm việc trên 20+ nhiệm vụ JIRA khác nhau; nó sẽ suy giảm theo thời gian và hoạt động kém.
Bộ nhớ tình huống (Episodic Memory)
Nó nắm bắt các trải nghiệm cụ thể; những gì đã xảy ra, khi nào và theo trình tự nào.
Trong phiên bản OpenClaw của tôi, đây là nhật ký họp hàng ngày (daily standup logs). Mỗi tác nhân viết một bản tóm tắt ngắn về những gì nó đã làm, những gì nó tìm thấy và những gì nó đã nâng cấp. Chúng tích lũy thành một dòng thời gian có thể tìm kiếm. Giá trị thực tế là rất lớn: các tác nhân có thể nhìn lại công việc của ngày hôm qua, phát hiện ra các mẫu và tránh lặp lại các thất bại. Các công cụ như Claude Code thường gặp khó khăn với điều này, trừ khi bạn thiết lập các hướng dẫn để ép buộc hành vi này.
Các tác nhân trong môi trường sản xuất có thể tận dụng các tính năng như bộ nhớ ngắn hạn của Agent Core để giữ những bộ nhớ tình huống này. Thậm chí còn có các cơ chế để hiểu điều gì đáng được lưu giữ vượt ra ngoài một lần tương tác duy nhất.
Bài báo xác nhận đây là một tầng riêng biệt và quan trọng.
Bộ nhớ ngữ nghĩa (Semantic Memory)
Chịu trách nhiệm cho kiến thức trừu tượng, chắt lọc, sự thật, các quy tắc heuristic và kết luận đã học.
Trong OpenClaw của tôi, đây là tệp MEMORY.md trong không gian làm việc của mỗi tác nhân. Nó được biên tập kỹ lưỡng. Không phải mọi thứ đều được đưa vào. Tác nhân (hoặc tôi, định kỳ) quyết định điều gì đáng được bảo tồn như một sự thật lâu dài so với điều gì chỉ mang tính tình huống.
Trong Agent Core Memory, đây chủ yếu là tính năng bộ nhớ dài hạn.
Bước biên tập này rất quan trọng; nếu không có nó, bộ nhớ ngữ nghĩa sẽ trở thành một ngăn kéo chứa rác.
Bộ nhớ quy trình (Procedural Memory)
Đây là các kỹ năng có thể thực thi được, các mô hình hành vi và hành vi đã học.
Trong OpenClaw, điều này ánh xạ chủ yếu vào các tệp AGENTS.md và SOUL.md, chứa các hướng dẫn về nhân cách, các ràng buộc hành vi và các quy tắc nâng cấp. Khi tác nhân đọc các tệp này vào đầu phiên, nó đang tải bộ nhớ quy trình. Các tệp này nên được cập nhật dựa trên phản hồi của người dùng, hoặc thậm chí thông qua các quy trình 'mơ' (dream) phân tích các tương tác.
Đây là một lĩnh vực mà tôi đã bị lơ là (cũng như các nhóm mà tôi đã làm việc cùng). Tôi dành thời gian tinh chỉnh một prompt, nhưng các cơ chế phản hồi thúc đẩy việc lưu trữ bộ nhớ quy trình và sự lặp lại trên các nhân cách này thường bị bỏ quên.
Bài báo chính thức hóa điều này như một tầng riêng biệt, điều mà tôi thấy rất xác thực. Chúng không chỉ là các hệ thống prompt. Chúng là một dạng hành vi học tập dài hạn định hình mọi hành động.
Năm Họ Cơ chế
Bây giờ chúng ta đã có một số định nghĩa chung về các loại bộ nhớ, hãy đi sâu vào các cơ chế bộ nhớ.
Nén ngữ cảnh tại chỗ (Context-Resident Compression)
Điều này bao gồm các cửa sổ trượt, tóm tắt cuộn (rolling summaries) và nén phân cấp. Đây là các chiến lược "giữ trong ngữ cảnh". Các tóm tắt cuộn rất hấp dẫn vì chúng trông gọn gàng (thực tế không phải, tôi sẽ giải thích tại sao ngay sau đây).
Tôi chắc chắn mọi người đều đã gặp trường hợp Claude Code hoặc Kiro CLI nén một cuộc trò chuyện khi nó trở nên quá lớn so với cửa sổ ngữ cảnh. Thường thì bạn tốt hơn nên khởi động một luồng mới.
Kho lưu trữ tăng cường truy xuất (Retrieval-Augmented Stores)
Đây là RAG được áp dụng cho lịch sử tương tác của tác nhân thay vì các tài liệu tĩnh. Tác nhân nhúng các quan sát trong quá khứ và truy xuất theo độ tương đồng. Điều này rất mạnh mẽ cho các tác nhân chạy dài với lịch sử sâu, nhưng chất lượng truy xuất nhanh chóng trở thành nút thắt cổ chai. Nếu các nhúng của bạn không bắt được ý định ngữ nghĩa tốt, bạn sẽ bỏ lỡ các bộ nhớ liên quan và đưa ra các bộ nhớ cũ kỹ.
Bạn cũng gặp vấn đề khi các câu hỏi như 'đã xảy ra gì thứ Hai tuần trước' không truy xuất được bộ nhớ chất lượng.
Tự phản tư và cải thiện (Reflective Self-Improvement)
Điều này bao gồm các hệ thống như Reflexion và ExpeL, nơi các tác nhân viết các bản kiểm tra sau cái chết (post-mortems) bằng lời nói và lưu trữ kết luận cho các lần chạy trong tương lai. Ý tưởng rất hấp dẫn; các tác nhân học hỏi từ sai lầm và cải thiện. Tuy nhiên, chế độ thất bại là rất nghiêm trọng (chúng tôi sẽ đề cập chi tiết hơn một chút).
Tôi tin rằng các phản tư dựa trên 'mơ' khác và các hệ thống như mô hình Memory Agent của Google cũng thuộc về lớp này.
Ngữ cảnh ảo phân cấp (Hierarchical Virtual Context)
Kiến trúc lấy cảm hứng từ hệ điều hành của MemGPT (xem repo GitHub). Một cửa sổ ngữ cảnh chính là "RAM", cơ sở dữ liệu gọi lại là "đĩa", và lưu trữ lưu trữ là "lưu trữ lạnh", trong khi tác nhân quản lý việc phân trang của riêng nó. Mặc dù danh mục này thú vị, nhưng chi phí/công việc để duy trì các tầng riêng biệt này là gánh nặng và có xu hướng thất bại.
Bài báo và repo git của MemGPT đều đã gần 3 năm tuổi, và tôi chưa thấy bất kỳ sử dụng thực tế nào trong sản xuất.
Quản lý được học bằng chính sách (Policy-Learned Management)
Đây là cách tiếp cận biên giới mới, nơi các toán tử được đào tạo RL (như lưu trữ, truy xuất, cập nhật, tóm tắt và loại bỏ) mà các mô hình học cách gọi tối ưu. Tôi nghĩ có rất nhiều hứa hẹn ở đây, nhưng tôi chưa thấy bất kỳ sự khai thác thực tế nào cho các nhà xây dựng hay bất kỳ sử dụng sản xuất thực tế nào.
Các Chế độ Thất bại
Chúng tôi đã bao gồm các loại bộ nhớ và các hệ thống tạo ra chúng. Tiếp theo là cách chúng có thể thất bại.
Thất bại do Nén ngữ cảnh
Sự trôi dạt của tóm tắt (Summarization drift) xảy ra khi bạn liên tục nén lịch sử để vừa vặn trong một cửa sổ ngữ cảnh. Mỗi lần nén/tóm tắt loại bỏ các chi tiết, và cuối cùng bạn bị bỏ lại với một bộ nhớ không thực sự khớp với những gì đã xảy ra. Một lần nữa, bạn thấy điều này trong Claude Code và Kiro CLI khi các phiên mã hóa bao gồm quá nhiều tính năng mà không tạo các luồng mới. Một cách tôi thấy các nhóm chống lại điều này là giữ các bộ nhớ thô liên kết với các bộ nhớ đã tóm tắt/hợp nhất.
Sự loãng sự chú ý (Attention dilution) là chế độ thất bại khác trong danh mục này. Ngay cả khi bạn có thể giữ mọi thứ trong ngữ cảnh (như với các cửa sổ 1 triệu token mới), các lời nhắc lớn hơn sẽ "mất" thông tin ở giữa. Trong khi các tác nhân về mặt kỹ thuật có tất cả các bộ nhớ, chúng không thể tập trung vào các phần đúng vào đúng thời điểm.
Thất bại do Truy xuất
Sự không khớp ngữ nghĩa so với nhân quả xảy ra khi các tìm kiếm tương đồng trả về các bộ nhớ có vẻ liên quan nhưng thực tế không. Các nhúng rất tuyệt vời trong việc xác định khi nào văn bản 'trông giống nhau', nhưng lại tồi trong việc biết 'đây là nguyên nhân'. Trong thực tế, tôi thường thấy điều này khi gỡ lỗi thông qua các trợ lý mã hóa. Chúng thấy các lỗi tương tự nhưng có thể bỏ qua nguyên nhân cơ bản, điều này thường dẫn đến việc thrashing/churning, nhiều thay đổi, nhưng không bao giờ sửa vấn đề thực sự.
Mù bộ nhớ (Memory blindness) xảy ra trong các hệ thống phân tầng khi các sự thật quan trọng không bao giờ nổi lên lại. Dữ liệu tồn tại, nhưng tác nhân không bao giờ thấy nó nữa. Điều này có thể vì cửa sổ trượt đã di chuyển, vì bạn chỉ truy xuất 10 bộ nhớ từ một nguồn dữ liệu, nhưng những gì bạn cần sẽ là bộ nhớ thứ 11.
Các thất bại điều phối thầm lặng là nguy hiểm nhất trong danh mục này. Các chính sách phân trang, loại bỏ hoặc lưu trữ làm sai việc, nhưng không có lỗi nào được ném ra (hoặc bị mất trong tiếng ồn bởi hệ thống tự chủ hoặc con người chạy nó). Triệu chứng duy nhất sẽ là các phản hồi trở nên tồi tệ hơn, chung chung hơn và ít dựa trên thực tế hơn. Mặc dù tôi đã thấy điều này phát sinh theo nhiều cách, gần đây nhất là khi OpenClaw không thể viết các tệp bộ nhớ hàng ngày, nên các cuộc họp hàng ngày/tóm tắt không có gì để làm. Tôi chỉ nhận ra vì nó tiếp tục quên những thứ chúng tôi đã làm trong những ngày đó.
Thất bại về Tính toàn vẹn Kiến thức
Sự cũ kỹ (Staleness) có lẽ là phổ biến nhất. Thế giới bên ngoài thay đổi, nhưng bộ nhớ hệ thống của bạn thì không. Các địa chỉ, trạng thái thiết bị, sở thích người dùng và bất cứ thứ gì hệ thống của bạn dựa vào để đưa ra quyết định có thể trôi đi theo thời gian. Các tác nhân sống lâu sẽ hành động dựa trên dữ liệu từ năm 2024 ngay cả trong năm 2026 (ai chưa thấy một LLM khăng khăng rằng ngày sai, Tổng thống sai đắn, hoặc công nghệ mới nhất thực sự chưa xuất hiện?).
Các lỗi tự củng cố (vòng lặp xác nhận) xảy ra khi hệ thống coi một bộ nhớ là sự thật nền tảng, nhưng bộ nhớ đó lại sai. Mặc dù bạn thường muốn các hệ thống học hỏi và xây dựng một cơ sở sự thật mới, nếu hệ thống tạo ra một bộ nhớ xấu, quan điểm của nó về thế giới bị ảnh hưởng. Trong phiên bản OpenClaw của tôi, nó quyết định rằng tích hợp SmartThings của tôi với Home Assistant bị lỗi; do đó, tất cả thông tin từ thiết bị SmartThings được coi là sai và nó bỏ qua mọi thứ từ đó (thực tế chỉ có một vài pin chết trong hệ thống của tôi).
Sự quá tổng quát hóa là một phiên bản yên tĩnh hơn của sự tự củng cố. Các tác nhân học một bài học trong một bối cảnh hẹp, sau đó áp dụng nó ở khắp mọi nơi. Một giải pháp thay thế cho một khách hàng duy nhất hoặc một lỗi duy nhất trở thành một mẫu mặc định.
Thất bại Môi trường
Xử lý mâu thuẫn có thể cực kỳ bực bội. Khi thông tin mới được thu thập, nếu nó xung đột với thông tin hiện có, các hệ thống không thể luôn xác định sự thật thực tế là gì. Trong hệ thống OpenClaw của tôi, tôi yêu cầu nó tạo một số quy trình làm việc N8N. Chúng đều được tạo chính xác, nhưng hành động hết giờ, vì vậy nó nghĩ rằng nó đã thất bại. Tôi xác minh các quy trình làm việc tồn tại, yêu cầu tác nhân OpenClaw nhớ lại nó, và nó đồng ý. Trong vài tương tác tiếp theo, tác nhân dao động giữa việc tin rằng quy trình làm việc có sẵn và tin rằng nó đã thất bại trong việc thiết lập.
Các Sự căng thẳng trong Thiết kế
Sẽ có sự đẩy và kéo chống lại tất cả những điều này cho các tác nhân và hệ thống bộ nhớ.
- Tiện ích so với Hiệu quả: Bộ nhớ tốt hơn thường có nghĩa là nhiều token hơn, độ trễ cao hơn, lưu trữ nhiều hơn, nhiều hệ thống hơn.
- Tiện ích so với Khả năng thích ứng: Bộ nhớ hữu ích bây giờ sẽ cũ kỹ vào một thời điểm nào đó. Cập nhật tốn kém và rủi ro.
- Khả năng thích ứng so với Trung thực: Bạn càng cập nhật, sửa đổi và nén nhiều, bạn càng có nguy cơ bóp méo những gì thực sự đã xảy ra.
- Trung thực so với Quản trị: Bộ nhớ chính xác có thể chứa thông tin nhạy cảm (PHI, PII, v.v.) mà bạn có thể được yêu cầu xóa, làm mờ hoặc bảo vệ.
- Tất cả những điều trên so với Quản trị: Các doanh nghiệp có các yêu cầu tuân thủ phức tạp có thể xung đột với tất cả những điều này.
Bài học Thực tế cho Các Nhà xây dựng
Tôi thường được các nhóm kỹ thuật hỏi về hệ thống bộ nhớ tốt nhất hoặc họ nên bắt đầu hành trình từ đâu. Đây là những gì tôi nói.
Bắt đầu với các phạm vi thời gian rõ ràng
Đừng xây dựng "bộ nhớ". Khi bạn cần bộ nhớ tình huống, hãy xây dựng nó. Khi trường hợp sử dụng của bạn phát triển và cần bộ nhớ ngữ nghĩa, hãy xây dựng nó. Đừng cố gắng tìm một hệ thống làm tất cả, và đừng xây dựng mọi hình thức bộ nhớ trước khi bạn cần nó.
Nghiêm túc với bước quản lý
Lên kế hoạch cách duy trì bộ nhớ của bạn. Đừng dự định tích lũy vô thời hạn; hãy tìm hiểu xem bạn có cần nén hay hành vi kết nối/mơ bộ nhớ hay không. Làm thế nào bạn biết điều gì đi vào bộ nhớ ngữ nghĩa so với bộ nhớ RAG? Bạn xử lý các bản cập nhật như thế nào? Nếu không biết những điều này, bạn sẽ tích lũy nhiễu, gặp mâu thuẫn và hệ thống của bạn sẽ suy giảm.
Giữ lại các bản ghi tình huống thô
Đừng chỉ dựa vào các bản tóm tắt; chúng có thể trôi đi hoặc mất chi tiết. Các bản ghi thô cho phép bạn quay lại những gì thực sự đã xảy ra và kéo chúng vào khi cần thiết.
Phiên bản hóa bộ nhớ phản tư
Để giúp tránh mâu thuẫn trong các bản tóm tắt, bộ nhớ dài hạn và các bản nén, hãy thêm dấu thời gian hoặc phiên bản cho từng cái. Điều này có thể giúp các tác nhân của bạn xác định điều gì là đúng và điều gì là phản ánh chính xác nhất của hệ thống.
Coi bộ nhớ quy trình là mã
Trong OpenClaw, các tệp Agents.MD, Memory.MD, tệp cá nhân và cấu hình hành vi của bạn đều là một phần của kiến trúc bộ nhớ của bạn. Xem xét chúng và giữ chúng dưới kiểm soát nguồn (source control) để bạn có thể kiểm tra những gì thay đổi và khi nào. Điều này đặc biệt quan trọng nếu hệ thống tự chủ của bạn có thể thay đổi những thứ này dựa trên phản hồi.
Tổng kết
Khung ghi - quản lý - đọc là bài học hữu ích nhất từ bài báo này. Nó đơn giản, nó hoàn chỉnh và nó buộc bạn phải suy nghĩ về cả ba giai đoạn thay vì chỉ "lưu đồ vật, truy xuất đồ vật".
Hệ thống phân loại ánh xạ surprisingly tốt với những gì tôi đã xây dựng trong OpenClaw thông qua sự lặp lại và thất vọng. Điều đó hoặc là xác thực hoặc khiêm tốn, tùy thuộc vào cách bạn nhìn nhận nó (có lẽ là cả hai). Bài báo chính thức hóa các mẫu mà các chuyên gia đã phát hiện một cách độc lập, đó là điều mà một bài khảo sát tốt nên làm.
Phần các vấn đề mở rất trung thực về mức độ chưa được giải quyết. Đánh giá vẫn còn sơ khai. Quản trị phần lớn bị bỏ qua trong thực tế. Quản lý được học bằng chính sách thì đầy hứa hẹn nhưng chưa trưởng thành. Còn rất nhiều dư địa để phát triển.
Bộ nhớ là nơi sự khác biệt thực sự xảy ra trong các hệ thống tác nhân. Không phải mô hình, không phải các lời nhắc. Đó là kiến trúc bộ nhớ. Bài báo cung cấp cho bạn một từ vựng và một khung để suy nghĩ rõ ràng hơn về nó.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Epic Games giới thiệu Lore: Hệ thống kiểm soát phiên bản mã nguồn mở thế hệ mới
17 tháng 6, 2026