
Hướng dẫn thực tế xây dựng hệ thống RAG cho cơ sở tri thức doanh nghiệp
Bài viết này cung cấp hướng dẫn chi tiết về cách xây dựng hệ thống RAG (Retrieval-Augmented Generation) cấp độ sản xuất để giải quyết vấn đề ảo giác của các mô hình ngôn ngữ lớn (LLM) trong môi trường doanh nghiệp. Chúng ta sẽ đi sâu vào kiến trúc hai giai đoạn, quy trình chia nhỏ tài liệu (chunking), và các công cụ mã nguồn mở giúp đảm bảo tính chính xác và bảo mật dữ liệu.

Mỗi kỹ sư AI đều từng trải qua khoảnh khắc đó. Bạn vừa hoàn thiện một bản chứng minh khái niệm (POC). Bản demo diễn ra tuyệt vời, Mô hình ngôn ngữ lớn (LLM) trả lời câu hỏi trôi chảy, tổng hợp thông tin nhanh chóng và gây ấn tượng với mọi người trong phòng. Nhưng ngay sau đó, có người hỏi về chính sách hoàn tiền của công ty, và nó tự tin đưa ra câu trả lời sai – một thông tin đã không còn đúng suốt tám tháng qua.
Đó không phải là lỗi của mô hình. Đó là lỗi của kiến trúc. Và chính xác đây là vấn đề mà Retrieval-Augmented Generation (RAG) được thiết kế để giải quyết.
Bài viết này sẽ hướng dẫn xây dựng một hệ thống RAG cấp độ sản xuất dành cho cơ sở tri thức nội bộ của doanh nghiệp, sử dụng hoàn toàn các công cụ mã nguồn mở. Chúng ta sẽ đi từ vấn đề đến thiết kế, qua từng giai đoạn của quy trình xử lý, và kết thúc bằng cách bạn thực sự biết được hệ thống có hoạt động hiệu quả hay không.
Tại sao LLM đơn độc không đủ cho doanh nghiệp
Hầu hết các tổ chức vừa và lớn đều sở hữu hàng nghìn tài liệu nội bộ: sổ tay kỹ thuật, chính sách nhân sự, hướng dẫn tuân thủ, tài liệu hướng dẫn nhân viên mới và thông số kỹ thuật sản phẩm. Chúng nằm rải rác trên Confluence, SharePoint, Notion, ổ đĩa chia sẻ và các chuỗi email không ai chạm vào trong ba năm.
Nhân viên trung bình dành hai đến ba giờ mỗi tuần chỉ để tìm kiếm thông tin đã tồn tại ở đâu đó. Kỹ sư cấp cao vô tình trở thành nhân viên hỗ trợ. Nhân viên mới mất nhiều tháng để có thể làm việc độc lập, không phải vì họ thiếu khả năng, mà vì kiến thức tổ chức bị phân tán và không thể tìm kiếm được.
Cách tiếp cận ngây thơ là chỉ định LLM vào tất cả dữ liệu này và đặt câu hỏi. Tuy nhiên, vấn đề là LLM là tĩnh. Sau khi được huấn luyện, chúng không có kiến thức về bản phát hành sản phẩm mới nhất của bạn, chính sách thay đổi quý trước hay bài phân tích sự cố (post-mortem) mà nhóm của bạn công bố hôm qua. Việc tinh chỉnh (fine-tuning) giúp ích về phong cách và giọng điệu, nhưng nó tốn kém, cập nhật chậm và không cho bạn biết câu trả lời đến từ đâu. Trong các ngành được kiểm soát, khoảng trống về khả năng kiểm tra này là không thể chấp nhận được.
RAG giải quyết vấn đề một cách tinh tế. Tại thời điểm truy vấn, hệ thống truy xuất các tài liệu liên quan nhất từ cơ sở tri thức của bạn và cung cấp chúng cho LLM làm ngữ cảnh. Mô hình tạo ra câu trả lời dựa trên các tài liệu đó, chứ không phải dựa trên những gì nó học được trong quá trình huấn luyện. Mọi câu trả lời đều có thể truy xuất nguồn gốc. Cơ sở tri thức có thể được cập nhật trong vài phút. Và không có dữ liệu nào cần rời khỏi cơ sở hạ tầng của bạn.
Kiến trúc RAG
Trước khi đi vào các thành phần riêng lẻ, hãy hình dung hình dạng của toàn bộ hệ thống. RAG không phải là một mô hình đơn lẻ, nó là hai quy trình (pipeline) hoạt động cùng nhau.
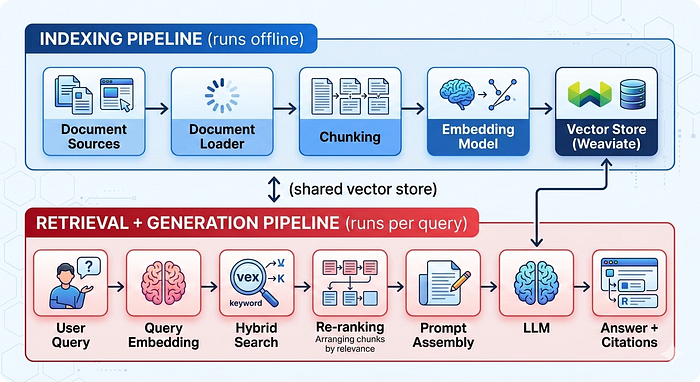 Kiến trúc RAG
Kiến trúc RAG
Quy trình lập chỉ mục (Indexing pipeline) chạy một lần khi bạn thiết lập hệ thống lần đầu, sau đó chạy tăng thêm bất cứ khi nào tài liệu được thêm hoặc thay đổi. Nhiệm vụ của nó là lấy tài liệu thô, chia nhỏ thành các đoạn (chunks) có ý nghĩa, chuyển đổi các đoạn đó thành biểu diễn vector và lưu trữ chúng.
Quy trình truy xuất và tạo sinh (Retrieval and generation pipeline) chạy trên mọi truy vấn của người dùng. Nó nhận câu hỏi, tìm các đoạn liên quan nhất, lắp ráp chúng thành một câu lệnh (prompt) và yêu cầu LLM tạo ra câu trả lời dựa trên ngữ cảnh đó.
Hai quy trình này chia sẻ kho lưu trữ vector (vector store) làm điểm gặp gỡ. Quyết định thiết kế duy nhất đó – tách biệt lập chỉ mục khỏi truy xuất – là điều khiến toàn bộ hệ thống có thể cập nhật mà không cần huấn luyện lại.
Giai đoạn 1: Quy trình lập chỉ mục
Nạp tài liệu của bạn
Thách thức đầu tiên đơn giản là đưa tài liệu của bạn vào dạng sử dụng được. Kiến thức doanh nghiệp hiếm khi nằm ở một nơi hoặc một định dạng. Đối với việc này, chúng tôi sử dụng LlamaIndex. Trong khi LangChain cung cấp các bộ nạp tài liệu, LlamaIndex đi xa hơn: nó cung cấp hơn một trăm kết nối gốc cho các hệ thống như Confluence, Notion, SharePoint, Google Drive và S3, đồng thời theo dõi các băm tài liệu để chỉ các tệp đã thay đổi được lập chỉ mục lại trong các lần chạy tiếp theo.
Chia nhỏ tài liệu (Chunking): Bước mà hầu hết các nhóm làm sai
Nếu bạn chỉ lấy một điều từ bài viết này, hãy để nó là điều này: chất lượng của việc chia nhỏ tài liệu (chunking) có tác động lớn hơn đến hiệu suất hệ thống của bạn so với việc lựa chọn LLM hay thậm chí là mô hình nhúng (embedding model) của bạn.
Lý do rất đơn giản. Khi người dùng đặt câu hỏi, hệ thống truy xuất các đoạn chứ không phải toàn bộ tài liệu. Nếu một đoạn bị cắt giữa chừng một lập luận, hoặc chia một bảng trên hai đoạn, hoặc quá lớn đến mức làm loãng tín hiệu, hệ thống truy xuất không thể thực hiện công việc của mình đúng cách.
Đối với nội dung doanh nghiệp, chúng tôi sử dụng SentenceWindowNodeParser của LlamaIndex, lập chỉ mục ở cấp câu để truy xuất chính xác nhưng mở rộng ra một cửa sổ các câu xung quanh khi tạo câu trả lời.
Chuyển văn bản thành Vector
Mỗi đoạn cần được chuyển đổi thành một vector số để chúng ta có thể đo lường sự tương tự giữa một truy vấn và một tài liệu. Đây là công việc của mô hình nhúng. Chúng tôi sử dụng BAAI/bge-large-en-v1.5, một mô hình mã nguồn mở từ Học viện Kỹ thuật Bắc Kinh, nằm trong số các mô hình mã nguồn mở hoạt động tốt nhất trên điểm chuẩn MTEB. Nó chạy hoàn toàn cục bộ, điều mà đối với hầu hết các doanh nghiệp không phải là lựa chọn mà là bắt buộc.
Một quy tắc cần coi là tuyệt đối: cùng một mô hình nhúng phải được sử dụng cho cả lập chỉ mục và truy vấn. Việc trộn lẫn các mô hình, thậm chí là nâng cấp lên phiên bản mới hơn giữa các lần triển khai, sẽ phá vỡ không gian toán học đó và làm cho chỉ mục của bạn trở nên vô nghĩa.
Lưu trữ Vector: Tại sao chọn Weaviate
Kho lưu trữ vector là nơi tất cả các đoạn đã lập chỉ mục sinh sống, sẵn sàng để được tìm kiếm. Chúng tôi sử dụng Weaviate, tự lưu trữ (self-hosted). Weaviate không chỉ lưu trữ vector và tìm kiếm hàng xóm gần nhất mà còn cung cấp thứ mà các triển khai doanh nghiệp thực sự cần: tìm kiếm lai nguyên bản (native hybrid search), kết hợp vector ngữ nghĩa với tìm kiếm từ khóa BM25 trong một lệnh gọi truy vấn duy nhất.
Điều này quan trọng vì người dùng doanh nghiệp không tìm kiếm theo cách người dùng web chung chung làm. Họ tìm kiếm với tên sản phẩm chính xác, ID vé nội bộ, viết tắt nhóm và thuật ngữ chuyên ngành mà các mô hình nhúng xử lý kém. Một truy vấn cho "bảng kiểm tra tuân thủ Điều 17 GDPR" chứa một thuật ngữ cụ thể mà sự tương đồng ngữ nghĩa sẽ làm loãng. BM25 sẽ tìm thấy nó ngay lập tức.
Giai đoạn 2: Truy xuất và Tạo sinh
Tìm đúng đoạn
Khi người dùng gửi truy vấn, công việc đầu tiên là truy xuất: tìm các đoạn có khả năng chứa câu trả lời nhất. Chúng tôi nhúng truy vấn bằng cùng một mô hình với lập chỉ mục, sau đó tìm kiếm Weaviate ở chế độ lai.
Tham số alpha kiểm soát sự pha trộn giữa tìm kiếm ngữ nghĩa và từ khóa. Giá trị 0.75 nghiêng về tương đồng ngữ nghĩa trong khi vẫn mang lại trọng số có ý nghĩa cho các kết quả khớp từ khóa.
Xếp hạng lại (Re-ranking): Vòng lọc tinh chỉnh
Tìm kiếm vector nhanh và mở rộng tốt, nhưng nó có một điểm yếu đã biết: nó so sánh truy vấn và tài liệu độc lập như hai vector riêng biệt. Hai tài liệu có thể có các vector tương tự với một truy vấn nhưng chỉ có một tài liệu thực sự trả lời nó.
Một cross-encoder re-ranker giải quyết vấn đề này bằng cách đọc truy vấn và từng tài liệu cùng nhau và chấm điểm sự liên kết ngữ nghĩa thực sự. Nó chậm hơn, nhưng khi chỉ áp dụng cho mười ứng viên hàng đầu từ truy xuất, độ trễ thêm vào là khoảng năm mươi đến một trăm mili-giây và thường có thể chấp nhận được.
LLM cục bộ: Giữ dữ liệu nội bộ
Đối với nhiều doanh nghiệp, đặc biệt là trong các lĩnh vực được kiểm soát, việc gửi tài liệu nội bộ đến API LLM bên ngoài hoàn toàn không thể chấp nhận được. Các yêu cầu về GDPR, nơi lưu trữ dữ liệu và tính bảo mật thương mại đều thúc đẩy việc suy luận tại chỗ (on-premise).
Ollama làm cho việc này trở nên đơn giản. Nó đóng gói các mô hình mã nguồn mở với thời gian chạy và một API đơn giản, cho phép bạn chạy Llama 3.1 cục bộ với một lệnh duy nhất.
Nhiệt độ (temperature) xứng đáng được nhắc đến ở đây. Đối với việc trả lời câu hỏi thực tế dựa trên cơ sở tri thức, bạn muốn mô hình mang tính xác định và bảo thủ. Nhiệt độ 0.1 giữ mô hình bám chặt vào ngữ cảnh được cung cấp.
Lắp đặt Prompt (Prompt Engineering)
Kỹ thuật prompt cho RAG thường bị coi nhẹ, đó là một sai lầm. Cách bạn khung ngữ cảnh và hướng dẫn trực tiếp quyết định xem mô hình có giữ được gốc hay trôi dạt vào ảo giác.
Những điều cần thiết bao gồm: nói với mô hình một cách rõ ràng rằng nó phải chỉ trả lời bằng ngữ cảnh được cung cấp; đưa ra hướng dẫn dự phòng rõ ràng cho khi câu trả lời không có trong ngữ cảnh; và yêu cầu nó trích dẫn tài liệu nguồn.
Đánh giá toàn bộ quy trình
Xây dựng hệ thống RAG mà không có khung đánh giá giống như vận hành phần mềm mà không có kiểm thử. Bạn không thể biết liệu một thay đổi đã cải thiện hay làm suy thoái hệ thống trừ khi bạn có đường cơ sở để so sánh.
RAGAS (Retrieval Augmented Generation Assessment) là khung mã nguồn mở tiêu chuẩn cho việc này. Bốn chỉ số cốt lõi – mỗi chỉ số bắt một loại thất bại khác nhau:
- Độ trung thực (Faithfulness): Kiểm tra xem câu trả lời có thực sự được hỗ trợ bởi ngữ cảnh đã truy xuất hay không.
- Tính liên quan của câu trả lời (Answer Relevancy): Đo lường xem phản hồi có thực sự giải quyết câu hỏi được hỏi hay không.
- Độ nhớ ngữ cảnh (Context Recall): Kiểm tra xem bước truy xuất có làm nổi bật thông tin cần thiết hay không.
- Độ chính xác ngữ cảnh (Context Precision): Đo lường tỷ lệ các đoạn được truy xuất thực sự hữu ích.
Đối với hệ thống sản xuất, các mục tiêu hợp lý là độ trung thực trên 0,90, tính liên quan của câu trả lời trên 0,85, độ nhớ ngữ cảnh trên 0,80 và độ chính xác ngữ cảnh trên 0,75.
RAG hay Fine-tuning? Câu trả lời trung thực
Câu hỏi này xuất hiện trong hầu hết mọi cuộc trò chuyện về LLM trong doanh nghiệp.
Fine-tuning là công cụ đúng khi bạn muốn thay đổi cách một mô hình hành xử: giọng điệu, mô hình suy luận, cách nó cấu trúc phản hồi, từ vựng nó sử dụng. Nó "nướng" những thuộc tính đó vào trọng số mô hình.
RAG là công cụ đúng khi bạn muốn thay đổi những gì một mô hình biết: các sự thật, chính sách và tài liệu mà nó có thể rút ra. Việc cập nhật kiến thức chỉ là vấn đề lập chỉ mục lại tài liệu.
Hai thứ này không cạnh tranh nhau. Các hệ thống sản xuất mạnh mẽ nhất sử dụng cả hai: một mô hình được tinh chỉnh trên phong cách viết và thuật ngữ nội bộ của công ty, kết hợp với RAG để neo giữ kiến thức.
Kết luận
RAG không làm cho LLM của bạn thông minh hơn. Nó làm cho nó trung thực.
Sự khác biệt giữa một hệ thống mà đồng nghiệp tin tưởng và một hệ thống mà họ âm thầm ngừng sử dụng sau hai tuần thường không có gì liên quan đến việc bạn chọn mô hình nào. Nó phụ thuộc vào việc liệu việc truy xuất có đủ chính xác để tìm đúng đoạn, liệu prompt có đủ kỷ luật để giữ mô hình dựa trên nó, và liệu bạn có đánh giá cần thiết để biết khi nào những thứ đó bắt đầu suy giảm hay không.
Trong môi trường doanh nghiệp, sự tin tưởng là sản phẩm. Mọi thứ khác chỉ là cơ sở hạ tầng.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Google tung ra Antigravity 2.0: Ứng dụng lập trình thế hệ mới với công cụ CLI và gói đăng ký AI Ultra
19 tháng 5, 2026