
Hybrid AI: Kết hợp Phân tích Tất định với Lý luận LLM để Ngăn chặn Dữ liệu "Ảo"
Bài viết khám phá kiến trúc Hybrid AI, nơi tách biệt việc xử lý dữ liệu tất định khỏi khả năng lý luận của LLM. Cách tiếp cận này giải quyết vấn đề các mô hình ngôn ngữ lớn thường tạo ra kết quả phân tích có vẻ hợp lý nhưng thực chất sai lệch, đảm bảo độ tin cậy cho hệ thống AI doanh nghiệp.

Trong bối cảnh các doanh nghiệp đang ráo riết ứng dụng AI để tối ưu hóa vận hành, một thách thức lớn đã nổi lên: làm sao để kết hợp khả năng lý luận ngôn ngữ xuất sắc của các Mô hình Ngôn ngữ Lớn (LLM) với sự chính xác tuyệt đối của phân tích dữ liệu truyền thống.
Gần đây, tôi đã thử xây dựng một mạng lưới AI tác nhân (agentic AI) nhằm tư vấn cho các nhà máy sản xuất về cách nâng cấp quy trình vận hành. Hệ thống được thiết kế để người dùng có thể tải lên dữ liệu đánh giá trực tiếp qua giao diện trò chuyện. Mẫu thử nghiệm đầu tiên hoàn thành khá nhanh và kết quả ban đầu rất hứa hẹn.
Tuy nhiên, có một vấn đề nghiêm trọng: Đa số kết quả đều sai!
Thậm chí tệ hơn, AI nhanh chóng học được các dải số liệu trông có vẻ hợp lý và bắt đầu tạo ra các kết quả thuyết phục nhưng hoàn toàn bịa đặt. Với khả năng diễn đạt trôi chảy của LLM, những kết quả này rất dễ bị nhầm lẫn là sự thật. Hành vi này không chỉ giới hạn ở một mô hình duy nhất mà xuất hiện trên nhiều hệ thống được thử nghiệm như ChatGPT, Gemini Enterprise, DIA Brain và Microsoft Copilot.
Rõ ràng, dữ liệu "có vẻ hợp lý" là chưa đủ. Các hệ thống AI doanh nghiệp yêu cầu dữ liệu phải đáng tin cậy.
Vấn đề cốt lõi của LLM trong phân tích dữ liệu
Sau khi điều tra sâu hơn, tôi nhận thấy các mô hình thất bại theo các kiểu lặp đi lặp lại. Ngay cả khi tính năng "Code Interpreter" (Trình thông dịch mã) được bật, các hệ thống vẫn:
- Bỏ qua các hàng hoặc cột.
- Áp dụng bộ lọc sai.
- Trả về kết quả giống nhau cho các đầu vào khác nhau.
- Trộn lẫn các phần của tập dữ liệu một cách âm thầm.
- Hoặc sụp đổ dưới các tác vụ phân tích phức tạp hơn.
Điều này dẫn đến một nhận thức quan trọng: Lý luận xác suất (probabilistic reasoning) cực kỳ mạnh mẽ cho việc diễn giải và tương tác, nhưng phân tích dữ liệu nền tảng yêu cầu thực thi tất định (deterministic execution).
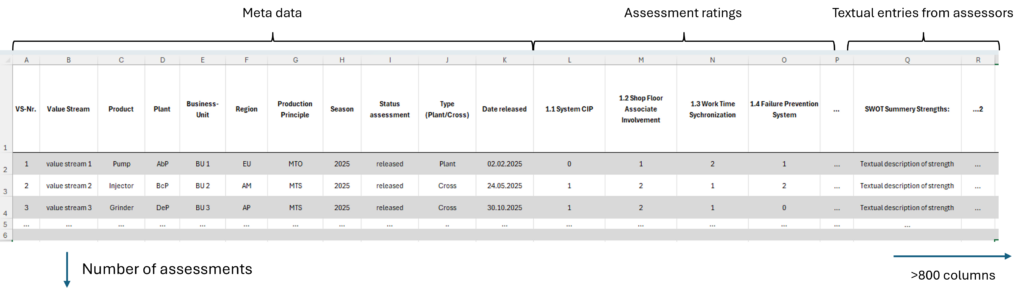 Cấu trúc dữ liệu đánh giá phức tạp
Cấu trúc dữ liệu đánh giá phức tạp
Giải pháp: Kiến trúc Hybrid AI
Ý tưởng cốt lõi để vượt qua thách thức phân tích là tách biệt rõ ràng giữa phân tích dữ liệu tất định và lý luận/diễn giải dựa trên LLM. Hình ảnh dưới đây minh họa kiến trúc hệ thống đã được chọn sau nhiều lần cải tiến.
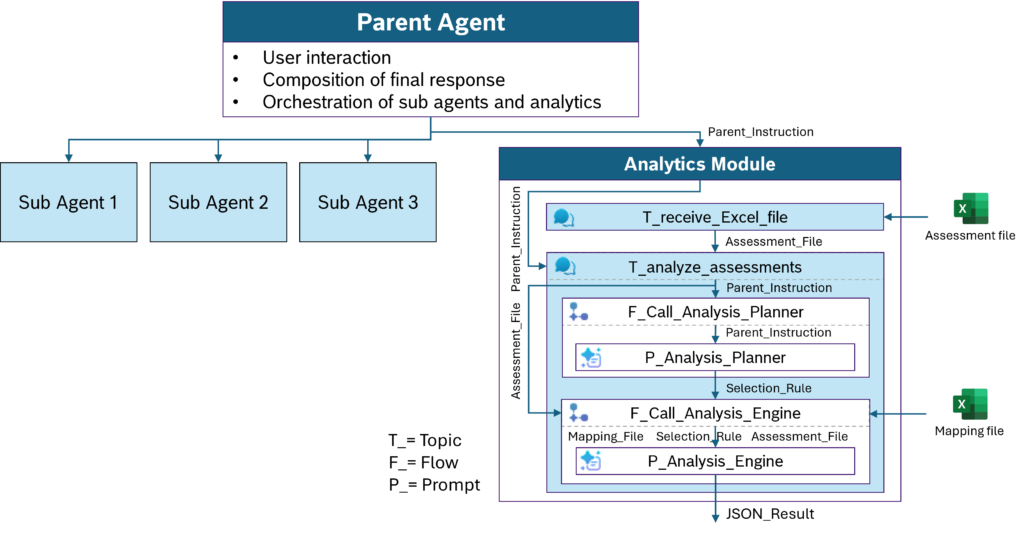 Kiến trúc hệ thống của tác nhân tư vấn với mô-đun phân tích tích hợp
Kiến trúc hệ thống của tác nhân tư vấn với mô-đun phân tích tích hợp
Hệ thống này bao gồm ba thành phần chính:
- Tác nhân chính (Parent Agent): Xử lý tất cả giao tiếp với người dùng, điều phối các tác nhân con và mô-đun phân tích.
- Các tác nhân con (Sub Agents): Các mô-đun LLM chuyên biệt có quyền truy cập vào các nguồn kiến thức cụ thể (tài liệu hướng dẫn, bảng câu hỏi, v.v.).
- Mô-đun phân tích (Analytics Module): Đây là trọng tâm của bài viết. Nó thực hiện phân tích dữ liệu tất định để cung cấp kết quả đáng tin cậy và có thể tái tạo.
Mô-đun phân tích nhận một lệnh phân tích bằng ngôn ngữ tự nhiên từ tác nhân chính và chuyển đổi nó thành quy trình thực thi dữ liệu chính xác. Nó bao gồm hai thành phần cốt lõi: Analysis Planner và Analysis Engine.
Analysis Planner: Bộ lập kế hoạch thông minh
P_Analysis_Planner là phần thông minh của quy trình phân tích dữ liệu. Nhiệm vụ duy nhất của nó là dịch yêu cầu bằng ngôn ngữ tự nhiên (Parent_Instruction) thành một đặc tả phân tích tất định gọi là Selection_Rule.
Để giảm thiểu sự biến đổi xác suất, quá trình dịch này bị giới hạn bởi các quy tắc nghiêm ngặt. Planner không bao giờ tương tác trực tiếp với các cột dữ liệu vật lý. Thay vào đó, nó hoạt động trên một lớp trừu tượng ngữ nghĩa, tách biệt ngôn ngữ tự nhiên khỏi cấu trúc tập dữ liệu cơ bản.
Ví dụ, Planner sẽ xác định:
- Loại phân tích nào là cần thiết (trung bình số hay tóm tắt văn bản).
- Các danh mục nội dung đánh giá nào có liên quan.
- Bộ lọc hàng nào cần áp dụng.
Output của Planner là một đối tượng JSON xác định chính xác những gì cần làm, không hơn không kém.
Analysis Engine: Động cơ thực thi tất định
Khác với Planner, P_Analysis_Engine không lý luận về nhiệm vụ. Nó chỉ thực thi đặc tả phân tích do Planner tạo ra. Về bản chất, lời nhắc AI này được sử dụng như một môi trường thực thi Python được kiểm soát.
Engine nhận ba đầu vào:
- Assessment_File: Tệp Excel chứa dữ liệu đánh giá do người dùng tải lên.
- Mapping_File: Tệp Excel mô tả các cột của Assessment_File (đóng vai trò là lớp ánh xạ ngữ nghĩa).
- Selection_Rule: Đối tượng JSON từ Planner.
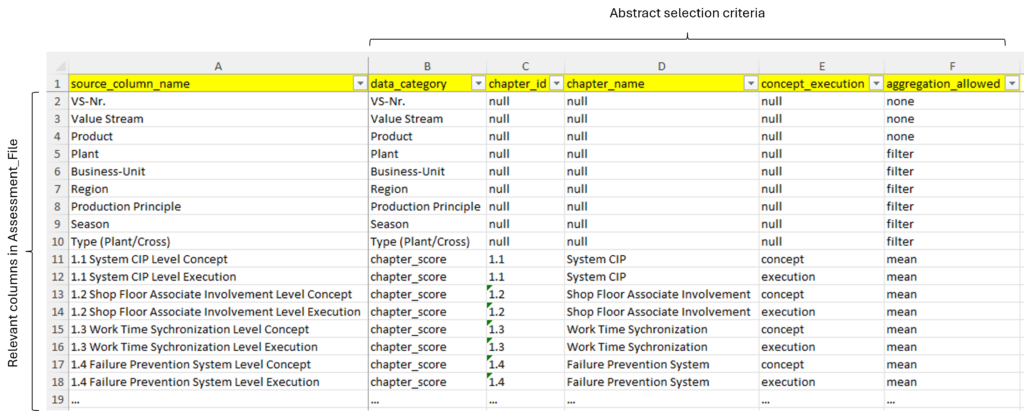 Cấu trúc của Mapping_File
Cấu trúc của Mapping_File
Mapping_File đóng vai trò quan trọng trong việc định nghĩa ngữ nghĩa của hơn 800 cột dữ liệu. Nhờ lớp trừu tượng này, Selection_Rule chỉ cần chỉ định loại thông tin nào là cần thiết, còn P_Analysis_Engine sẽ chọn các cột tập dữ liệu tương ứng trong quá trình thực thi.
Engine sử dụng thư viện Pandas để thực thi một đoạn mã Python được xác định trước. Nó không được phép diễn giải lại yêu cầu của người dùng, không được suy ra các cột bổ sung và không được thay đổi Selection_Rule. Nó chỉ thực thi.
Ví dụ thực tế từ đầu đến cuối
Để minh họa quy trình làm việc hoàn chỉnh, hãy theo dõi một yêu cầu thực tế của người dùng:
"Tóm tắt các tiềm năng cải tiến chính cho chương 1.4 Hệ thống Phòng ngừa Lỗi trong nhà máy AbcP."
Bước 1: Dịch từ Analysis Planner
Planner chuyển đổi yêu cầu này thành Selection_Rule JSON:
analysis_type: "text_summary" (tóm tắt văn bản).data_category: ["potential"] (chỉ lấy tiềm năng cải tiến).chapter_id: ["1.4"] (chỉ chương 1.4).row_filters: {"Plant": ["AbcP"]} (chỉ lọc nhà máy AbcP).
Bước 2: Thực thi từ Analysis Engine
Engine nhận Selection_Rule và Mapping_File. Nó xác định các cột Excel thực tế tương ứng với các tiêu chí trừu tượng (ví dụ: "1.4 CON L2 Improvement potentials", "1.4 EXE L3 Improvement potentials"...).
Sau đó, Engine áp dụng bộ lọc hàng để chỉ giữ lại dữ liệu của nhà máy AbcP và thu thập tất cả các mục văn bản không trống từ các cột đã chọn.
Kết quả trả về là một đối tượng JSON thô chứa các nhận xét của người đánh giá:
{
"entry_count": 6,
"entries": [
"Nguyên nhân gốc rễ không được theo dõi có hệ thống.",
"Quy tắc thăng cấp cho các lỗi lặp lại không rõ ràng.",
"Bài học kinh nghiệm không được chuyển giao giữa các ca làm việc.",
...
]
}
Lưu ý rằng tại thời điểm này, hệ thống chưa tạo ra bất kỳ khuyến nghị nào. Nó chỉ mới tạo ra một bộ sưu tập các phát hiện đánh giá đáng tin cậy.
Bước 3: Diễn giải từ Parent Agent Trong bước cuối cùng, tác nhân chính thu thập kết quả JSON và tạo ra phản hồi cuối cùng bằng ngôn ngữ tự nhiên cho người dùng, dựa trên các dữ liệu thực đã được xác minh ở trên.
Tại sao Kiến trúc AI lại Quan trọng?
Các Mô hình Ngôn ngữ Lớn (LLM) vốn mạnh về diễn giải, lý luận và tạo ngôn ngữ, nhưng vẫn yếu trong phân tích số học đáng tin cậy. Mục tiêu tối ưu hóa của chúng là tính "có lý" (plausibility), không phải tính tái tạo tất định.
Tin tốt là hạn chế này có thể được bù đắp phần lớn thông qua kiến trúc hệ thống thông minh. Chìa khóa nằm ở sự phân chia trách nhiệm rõ ràng: các lớp xử lý dữ liệu tất định thực hiện nền tảng phân tích, trong khi LLM tập trung vào diễn giải, ưu tiên hóa, giải thích và giao tiếp.
Trong cách tiếp cận đã trình bày, quyết định thiết kế quan trọng nhất không phải là thêm nhiều AI hơn vào hệ thống, mà là xác định cẩn thận nơi lý luận xác suất nên kết thúc và thực thi tất định nên bắt đầu. Các hệ thống tác nhân đáng tin cậy trong tương lai sẽ yêu cầu chính xác các loại kiến trúc Hybrid này: kết hợp sự mạnh mẽ của các quy trình khoa học dữ liệu cổ điển với khả năng suy luận của LLM.
Bài viết liên quan

Phần mềm
Tối ưu hóa hệ thống gợi ý bằng LLM và Python: Cách cân bằng giữa tốc độ và độ chính xác
08 tháng 6, 2026

Phần mềm
Giám đốc Rimini Street: "Headless ERP" và mã nguồn mở là chìa khóa thoát khỏi sự kiểm soát của nhà cung cấp
16 tháng 6, 2026

Công nghệ
Amazon ra mắt tính năng Sleep Studio giúp trẻ em đi ngủ dễ dàng hơn trên loa Echo
10 tháng 6, 2026