Khám phá Chế độ Tự động trong Claude Code: Hệ thống lập trình tự trị từ Anthropic
Anthropic vừa ra mắt chế độ Auto Mode cho Claude Code, cho phép thực hiện các quy trình phát triển phần mềm nhiều bước với sự can thiệp thủ công tối thiểu. Tính năng này kết hợp khả năng thực thi tự động với các lớp bảo mật đa tầng và vẫn giữ lại các điểm kiểm soát phê duyệt của con người cho các thao tác nhạy cảm.
Anthropic đã chính thức giới thiệu tính năng "Auto Mode" (Chế độ Tự động) trong Claude Code, mở ra khả năng thực hiện các tác vụ phát triển phần mềm đa bước với sự can thiệp thủ công của con người được giảm thiểu đáng kể. Trong chế độ này, các nhà phát triển chỉ cần xác định mục tiêu, để hệ thống tự lo liệu việc tạo mã, thực thi lệnh, sử dụng công cụ và tinh chỉnh lặp đi lặp lại, đồng thời vẫn yêu cầu sự phê duyệt của người dùng tại các điểm kiểm soát quan trọng đối với các thao tác nhạy cảm.
Trước đây, Claude Code hoạt động dựa trên mô hình dựa trên quyền hạn, nơi người dùng phải phê duyệt hầu hết mọi hành động như chạy lệnh hay sửa đổi tệp. Mặc dù cách này mang lại độ an toàn và kiểm soát cao, nó lại gây ra ma sát trong các phiên làm việc dài do phải liên tục xác nhận, dẫn đến hiện tượng "mệt mỏi vì phê duyệt" khiến người dùng mất nhiều thời gian quản lý lời nhắc hơn là tập trung vào công việc phát triển.
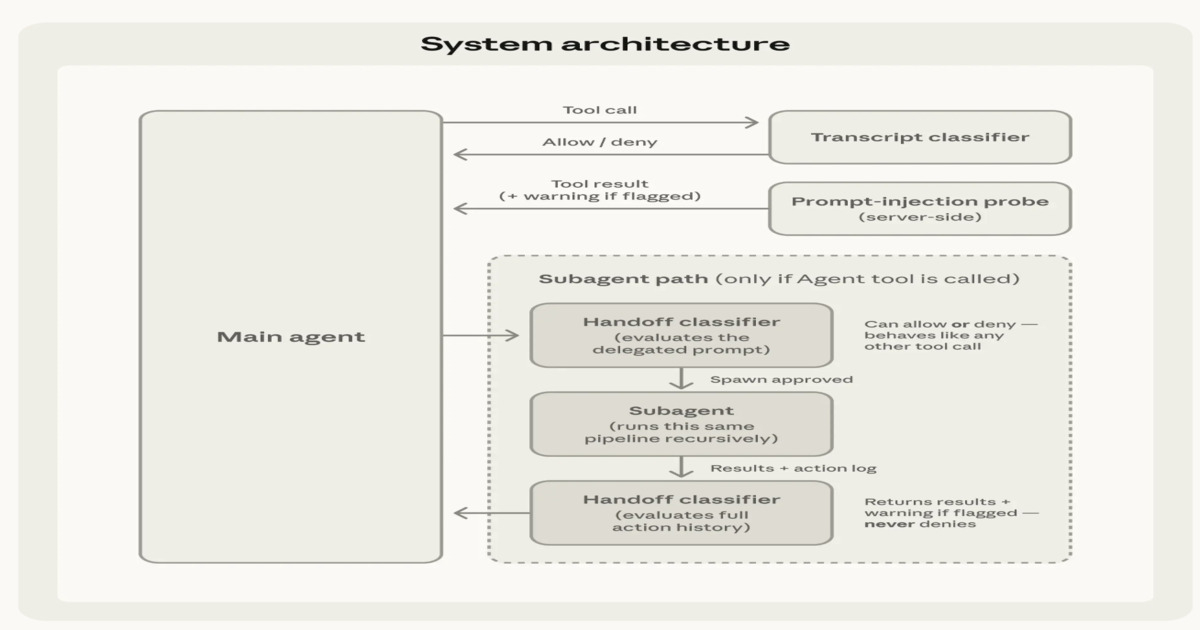
/filters:no_upscale()/news/2026/05/anthropic-claude-code-auto-mode/en/resources/1claudcodeautomode-1777787383154.jpeg) Kiến trúc tổng quan của Claude Code Auto Mode
Kiến trúc tổng quan của Claude Code Auto Mode
Sid Chaudhary, Trưởng bộ phận Sản phẩm tại Intempt, nhận định: “Bây giờ bạn có thể chạy Claude và thực sự rời đi. Đi nghỉ cà phê. Đi dạo một vòng. Bạn không phải trông chừng nó liên tục nữa.”
Kiến trúc an toàn và thực thi nhiều lớp
Auto Mode áp dụng một kiến trúc an toàn và thực thi nhiều lớp chi phối cả cách xử lý đầu vào và cách thực thi hành động. Tại lớp đầu vào, các đầu ra từ công cụ như đọc tệp, kết quả shell và phản hồi web sẽ được kiểm tra trước khi được đưa vào ngữ cảnh hệ thống. Khi nội dung có vẻ độc hại hoặc cố gắng thay đổi hướng dẫn, hệ thống sẽ chèn các cảnh báo để đảm bảo nội dung đó được coi là không đáng tin cậy và không làm ghi đè ý định của người dùng.
Tại lớp thực thi, mỗi hành động được đề xuất sẽ được đánh giá trước khi chạy, hoạt động như một cơ chế phê duyệt tự động lọc các thao tác an toàn trong khi định tuyến các trường hợp mơ hồ để kiểm tra thêm. Điều này giúp giảm sự can thiệp lặp lại của người dùng nhưng vẫn giữ lại các biện pháp bảo vệ cho các hành động có tác động cao hoặc tiềm ẩn nguy cơ không an toàn.
Ankit Kalluraya, một Kỹ sư Kiểm thử, mô tả hành vi của giao diện trong chế độ tự động: “Trong chế độ tự động, biểu tượng vòng quay sẽ chuyển sang màu đỏ khi một kiểm tra quyền hạn được kích hoạt, cung cấp tín hiệu hình ảnh rõ ràng rằng Claude đang tạm dừng để xin phê duyệt.”
Cân bằng hiệu quả và độ an toàn
Hệ thống sử dụng phương pháp phân loại hai giai đoạn để cân bằng giữa hiệu quả và phạm vi bảo vệ. Bộ lọc ban đầu nhanh sẽ xử lý hầu hết các lệnh gọi công cụ, cho phép các hành động an toàn tiếp tục với độ trễ tối thiểu. Chỉ các hoạt động không chắc chắn hoặc tiềm ẩn rủi ro mới được nâng cấp lên phân tích sâu hơn.
/filters:no_upscale()/news/2026/05/anthropic-claude-code-auto-mode/en/resources/1Screenshot 2026-05-02 at 5.19.31 PM-1777787383154.png)
Cách tiếp cận này cải thiện khả năng phát hiện đối với các trường hợp ngoại lệ trong khi kiểm soát độ trễ và chi phí tính toán, đồng thời duy trì việc thực thi nhất quán các quy tắc an toàn và sự nhất quán về ý định.
Mykola Kondratiuk, Giám đốc tại Playtika, nhận xét: “Với Auto Mode bật lên, AI giờ đây là người phê duyệt, không chỉ là người thực hiện. Hầu hết các tài liệu quản trị vẫn ghi tên một con người ở vị trí đó và chưa được cập nhật.”
Tuy nhiên, không phải ai cũng hoàn toàn lạc quan về những thay đổi này. Mayank Agrawal, Kỹ sư Chính tại Zethra OS, đã chia sẻ quan điểm thận trọng hơn: “Đây chính là nơi mà sự khả dự (resilience) biến thành vấn đề bảo mật.”
Mở rộng bảo mật cho quy trình Subagent
Chế độ tự động cũng mở rộng các kiểm tra an toàn cho các quy trình công việc con (subagent workflows). Trong quá trình ủy quyền, các kiểm tra đầu ra sẽ xác minh xem nhiệm vụ được giao có phù hợp với ý định của người dùng hay không trước khi thực thi bắt đầu.
Sau khi hoàn thành, một kiểm tra trả về sẽ đánh giá toàn bộ lịch sử thực thi của tác nhân con để phát hiện các nỗ lực tiêm lệnh (prompt injection) hay thao túng trong thời gian chạy. Nếu phát hiện rủi ro, các cảnh báo sẽ được thêm vào trước khi kết quả được trả về cho tác nhân điều phối chính.
Anthropic cho biết họ sẽ tiếp tục cải thiện sự cân bằng giữa an toàn và chi phí thông qua việc mở rộng bộ đánh giá và tinh chỉnh lặp đi lặp lại, nhằm mục đích bắt đủ các hành động rủi ro cao để việc vận hành tự động trở nên an toàn hơn so với không có rào chắn, đồng thời khuyến khích người dùng nhận thức về rủi ro còn tồn tại và báo cáo các vấn đề phát sinh.