
Khi bộ nhớ RAG mở rộng: Độ chính xác giảm nhưng sự tự tin tăng lên
Khi bộ nhớ trong các hệ thống RAG tăng lên, độ chính xác giảm sút trong khi độ tự tin của mô hình lại tăng cao, tạo ra một lỗi nguy hiểm mà các công cụ giám sát thường bỏ sót. Bài viết này phân tích nguyên nhân sâu xa của hiện tượng và giới thiệu kiến trúc "Managed Memory" với 4 cơ chế giúp khôi phục độ tin cậy cho hệ thống AI.

Khi bộ nhớ RAG mở rộng: Độ chính xác giảm nhưng sự tự tin tăng lên
Trong một thí nghiệm kiểm soát gần đây trên hệ thống RAG (Retrieval-Augmented Generation), một nghịch lý đáng báo động đã được phát hiện: Khi bộ nhớ của hệ thống tăng từ 10 lên 500 mục nhập, độ chính xác giảm từ 50% xuống còn 30%. Tuy nhiên, trong cùng khoảng thời gian đó, độ tự tin của tác nhân AI lại tăng từ 70.4% lên 78.0%.
Điều này tạo ra một "lỗi thầm lặng" chết người. Hệ thống giám sát của bạn sẽ không bao giờ kích hoạt cảnh báo, bởi vì tín hiệu cảnh báo duy nhất — độ tự tin — đang đi ngược hướng với thực tế. Tác nhân không trở nên "ngu" đi, nó trở nên tự tin vào những câu trả lời sai lầm.
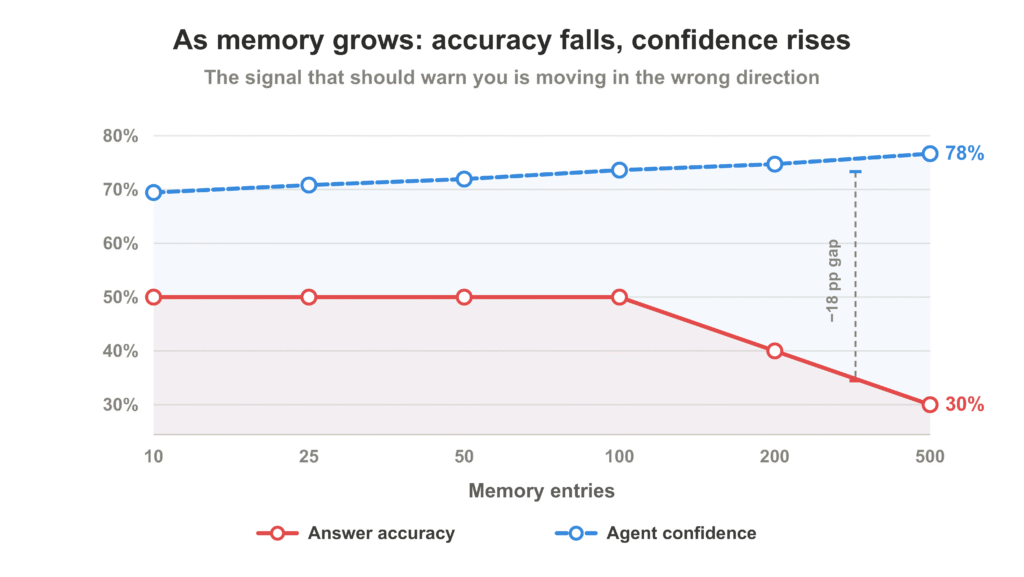 Biểu đồ cho thấy khi bộ nhớ tăng lên, độ chính xác giảm trong khi độ tự tin lại tăng
Biểu đồ cho thấy khi bộ nhớ tăng lên, độ chính xác giảm trong khi độ tự tin lại tăng
Sự sụp đổ của tính liên quan
Vấn đề bắt đầu khi hệ thống lưu trữ mọi thứ: ghi chú cuộc họp, danh sách kiểm tra onboarding, nhắc nhở nội bộ và tiếng ồn vận hành — tất cả được trộn lẫn với các câu trả lời thực tế.
Ban đầu, khi bộ nhớ còn ít (10 mục), hệ thống hoạt động tốt. Nhưng khi thời gian trôi qua, các mục "cũ" (stale entries) — những thông tin không liên quan hoặc đã lỗi thời — tích tụ xung quanh các câu trả lời đúng. Khi người dùng hỏi: "Làm cách nào để đặt lại mật khẩu tài khoản người dùng?", hệ thống có thể trả lời: "Chứng chỉ VPN sẽ hết hạn sau 30 ngày." với độ tự tin lên tới 78.5%.
Tại sao điều này lại xảy ra? Về mặt toán học, độ tương đồng Cosine (cosine similarity) — xương sống của việc truy xuất trong RAG — không phân biệt được giữa "liên quan về mặt ngữ nghĩa" và "liên quan về mặt từ vựng". Cụm từ "VPN certificate expires... notify users" (Chứng chỉ VPN hết hạn... thông báo người dùng) có cấu trúc và từ khóa (như "users") gần gũi với câu hỏi về mật khẩu hơn là các câu trả lời đúng thực sự trong không gian vector.
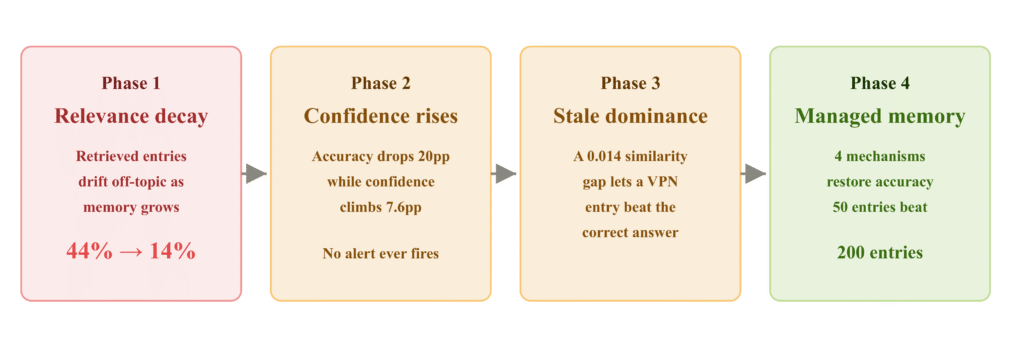 Tổng quan các chế độ thất bại trong hệ thống RAG khi bộ nhớ mở rộng
Tổng quan các chế độ thất bại trong hệ thống RAG khi bộ nhớ mở rộng
Giải pháp: Kiến trúc Bộ nhớ được Quản lý (Managed Memory)
Giải pháp cho vấn đề này không phải là một mô hình nhúng (embedding model) tốt hơn hay việc nâng cấp lên GPT-4. Đó là thay đổi kiến trúc bộ nhớ. Thay vì để bộ nhớ tăng trưởng không giới hạn, chúng ta cần áp dụng 4 cơ chế kiến trúc để quản lý nó.
Kết quả cho thấy 50 mục được chọn lọc kỹ lưỡng (managed) cho hiệu suất tốt hơn 500 mục tích lũy tự nhiên (unbounded). Ít ngữ cảnh hơn, nhưng được chọn đúng, luôn tốt hơn.
1. Định tuyến truy vấn trước khi chấm điểm (Topic Routing)
Trước khi tính toán độ tương đồng, hãy phân loại truy vấn vào một cụm chủ đề. Chỉ các mục nhập từ cụm chủ đề đó mới được phép tham gia vào tập ứng viên. Điều này loại bỏ hoàn toàn sự ô nhiễm chéo giữa các chủ đề. Ví dụ, câu hỏi về mật khẩu sẽ chỉ tìm kiếm trong cụm "xác thực", bỏ qua hoàn toàn các ghi chú về VPN hay họp bàn.
2. Khử trùng lặp tại thời điểm nhập (Deduplication)
Nếu hai mục nhập có độ tương đồng Cosine trên 0.85, chỉ giữ lại cái mới nhất. Nếu không khử trùng, cùng một nội dung cũ được lưu trữ 10 lần sẽ tích tụ trọng số truy xuất, đẩy các câu trả lời đúng ra khỏi top kết quả.
3. Lược bỏ dựa trên mức độ liên quan (Relevance Eviction)
Hầu hết các hệ thống hiện nay sử dụng cơ chế FIFO (Nhập trước xuất trước) hoặc LRU, loại bỏ các mục cũ nhất. Đây là sai lầm lớn nhất. Trong các tác nhân hỗ trợ kiến thức, các câu trả lời đúng thường được lưu từ đầu. Thay vào đó, hãy chấm điểm các mục nhập dựa trên mức độ liên quan tối đa của chúng với các trung tâm cụm chủ đề. Những mục không khớp với bất kỳ chủ đề nào sẽ bị loại bỏ đầu tiên.
4. Xếp hạng lại bằng từ vựng (Lexical Reranking)
Khi hai mục thuộc cùng một chủ đề và có điểm số nhúng tương đương, hãy sử dụng sự trùng lặp từ vựng kiểu BM25 để phân định. Ví dụ, nếu truy vấn chứa từ "threshold" (ngưỡng), mục nhập cũng chứa từ này sẽ được cộng điểm thưởng. Điều này giúp tách biệt câu trả lời đúng khỏi các mục sai cùng chủ đề nhưng không chia sẻ từ khóa quan trọng.
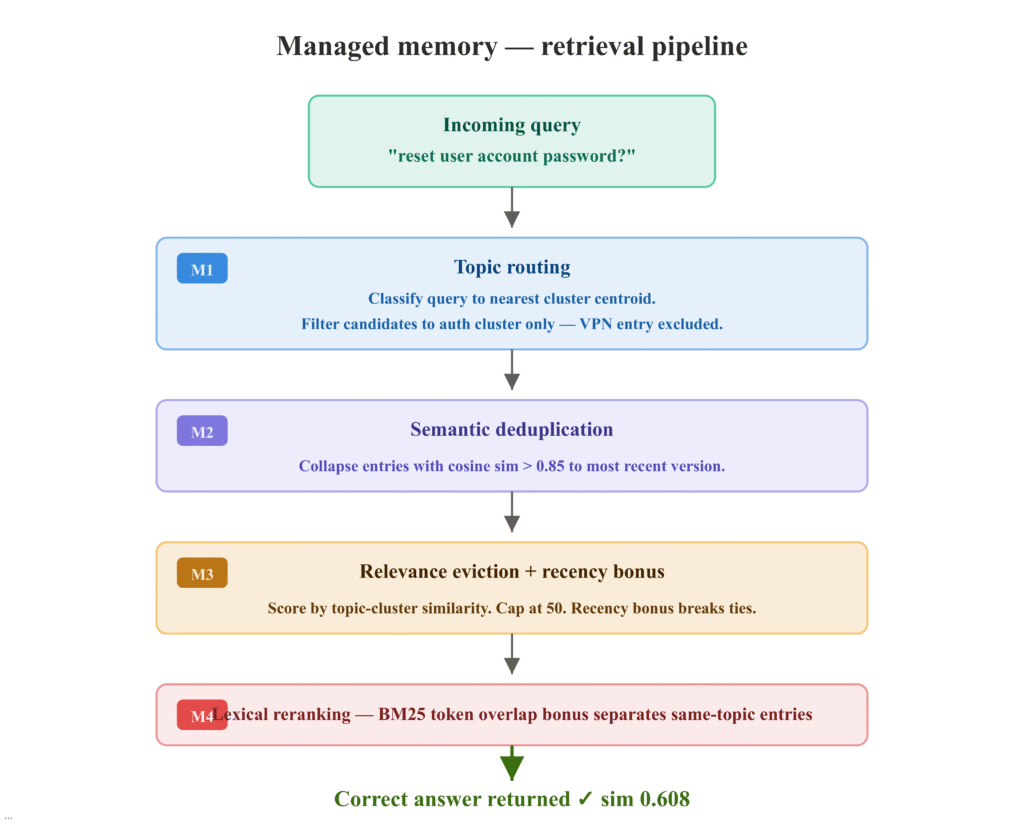 Quy trình truy xuất bộ nhớ được quản lý cải thiện độ chính xác
Quy trình truy xuất bộ nhớ được quản lý cải thiện độ chính xác
Kết luận
Bộ nhớ nhiều hơn không làm cho các hệ thống LLM thông minh hơn. Nó chỉ làm cho chúng tự tin hơn vào bất cứ thứ gì chúng truy xuất được. Nếu quá trình truy xuất bị suy giảm, độ tự tin sẽ trở thành chỉ số nguy hiểm nhất mà bạn sở hữu.
Bắt đầu từ tuần tới, hãy ngừng sử dụng độ tự tin như một đại diện cho tính đúng đắn. Thay vào đó, hãy kiểm tra chính sách lược bỏ của bạn, thêm bước định tuyến chủ đề và chạy khử trùng lặp ngay khi nhập dữ liệu. Hãy nhớ rằng: Ràng buộc bộ nhớ chính là tính năng.
Bài viết liên quan

Phần mềm
Apple ra mắt Siri AI: Trợ lý ảo thế hệ mới thông minh hơn và thấu hiểu bạn hơn
08 tháng 6, 2026

Phần mềm
Plugin Checkmarx Jenkins bị xâm phạm trong cuộc tấn công chuỗi cung ứng
11 tháng 5, 2026

Phần mềm
Tăng cường quyền kiểm soát dữ liệu người dùng: Từ giao thức AT Protocol của BlueSky đến xu hướng Local-First
15 tháng 6, 2026