
Linux 7.0 làm giảm hiệu năng PostgreSQL: Giải mã vấn đề Preemption và giải pháp Huge Pages
Một kỹ sư AWS đã phát hiện hiệu năng của PostgreSQL giảm đi một nửa trên Linux 7.0 do thay đổi cơ chế tiền đình của kernel. Vấn đề xuất phát từ việc xung đột giữa spinlock và page fault, có thể giải quyết bằng cách kích hoạt Huge Pages.

Vào ngày 3 tháng 4, Salvatore Dipietro, một kỹ sư tại AWS, đã đăng một bản vá lên danh sách gửi thư kernel Linux. Lý do là trên một máy Graviton4 với 96 vCPU chạy Linux 7.0, thông lượng (throughput) của PostgreSQL đã giảm xuống còn khoảng một nửa so với khi chạy trên Linux 6.x.
Bài viết này sẽ đi sâu vào những thay đổi trong Linux 7.0, cách PostgreSQL quản lý bộ nhớ, và vai trò của các trang nhớ (memory pages) trong việc tạo ra (hoặc giải quyết) vấn đề này.
 Môi trường server và hiệu năng
Môi trường server và hiệu năng
Hiệu năng sụt giảm nghiêm trọng
Salvatore Dipietro đã chạy công cụ benchmark chuẩn pgbench trên bộ xử lý Graviton4 với 96 vCPU. Khối lượng công việc là một bài kiểm tra cập nhật đơn giản với hệ số quy mô 8.470 (tương đương bảng khoảng 847 triệu dòng), mô phỏng 1.024 client và 96 luồng. Đây là một tải nặng tính toán song song cao được thiết kế để thử thách hệ thống.
Kết quả thu được rất đáng ngạc nhiên. Trên cùng một phần cứng và khối lượng công việc, Linux 7.0 chỉ đạt được khoảng một nửa thông lượng của Linux 6.x:
- Linux 6.x: 98.565 giao dịch mỗi giây
- Linux 7.0: 50.751 giao dịch mỗi giây
Để tìm ra xem thời gian đã bị tiêu hao ở đâu, Dipietro đã sử dụng công cụ phân tích perf của Linux. Kết quả cho thấy rõ ràng rằng 55% thời gian CPU của máy đã được tiêu tốn bên trong một hàm duy nhất: s_lock. Thủ phạm đã được truy ngược về một thay đổi trong cách Linux 7.0 lập lịch các quy trình.
Cơ chế Preemption thay đổi trong Linux 7.0
Khi nhiều luồng chạy trên một máy, hệ điều hành cần chia sẻ CPU giữa chúng. Đó là công việc của bộ lập lịch (scheduler). Tuy nhiên, bộ lập lịch cũng quyết định một điều tinh tế hơn: khi nào nên ngắt một luồng đang chạy và chuyển CPU cho luồng khác. Quyết định này được gọi là preemption (tiền đình).
Trước Linux 7.0, có ba tùy chọn cấu hình:
- PREEMPT_NONE: Kernel hầu như không bao giờ ngắt một luồng đang chạy. Luồng sẽ chạy cho đến khi tự nguyện nhường CPU (khi gọi syscall, chờ I/O, hoặc ngủ). Đây là mặc định truyền thống cho máy chủ, mang lại ít chuyển đổi ngữ cảnh hơn, thông lượng cao hơn và hành vi dễ dự đoán dưới tải nặng.
- PREEMPT_FULL: Kernel có thể ngắt một luồng đang chạy tại hầu hết mọi điểm an toàn. Điều này giảm thời gian phản hồi nhưng tăng chi phí chuyển đổi ngữ cảnh. Thường là mặc định cho máy tính để bàn.
- PREEMPT_LAZY: Được giới thiệu trong Linux 6.12 như một sự thỏa hiệp. Bộ lập lịch có thể ngắt luồng, nhưng cố gắng chờ các ranh giới tự nhiên thay vì cắt ngang một cách hung hăng.
Trong Linux 7.0, PREEMPT_NONE đã bị loại bỏ như một tùy chọn trên các kiến trúc CPU hiện đại, chỉ còn lại PREEMPT_FULL và PREEMPT_LAZY. Trên thực tế, PREEMPT_LAZY được thiết kế để thay thế trực tiếp cho các khối lượng công việc tập trung vào thông lượng. Đối với phần lớn phần mềm máy chủ, điều này hoạt động tốt. Nhưng PostgreSQL lại gặp một trường hợp cụ thể nơi sự khác biệt này là thảm khốc.
 Kiến trúc phần cứng và hệ điều hành
Kiến trúc phần cứng và hệ điều hành
Quản lý bộ nhớ và Spinlock trong PostgreSQL
PostgreSQL, giống như hầu hết các cơ sở dữ liệu, không lưu trữ dữ liệu dưới dạng các dòng trong một tệp phẳng. Thay vào đó, nó sử dụng một trừu tượng kích thước cố định gọi là data page (8 KB theo mặc định) làm đơn vị lưu trữ cơ bản. PostgreSQL duy trì một shared buffer pool, một vùng bộ nhớ chia sẻ lớn lưu trữ cache các trang dữ liệu đã đọc gần đây.
Khi một client kết nối, máy chủ tạo ra một quy trình chuyên dụng gọi là backend. Mọi backend cần một trang dữ liệu chưa có trong buffer pool phải đọc nó từ đĩa, sau đó tìm một bộ đệm để lưu trữ nó. Công việc tìm bộ đệm đó thuộc về một hàm quan trọng gọi là StrategyGetBuffer.
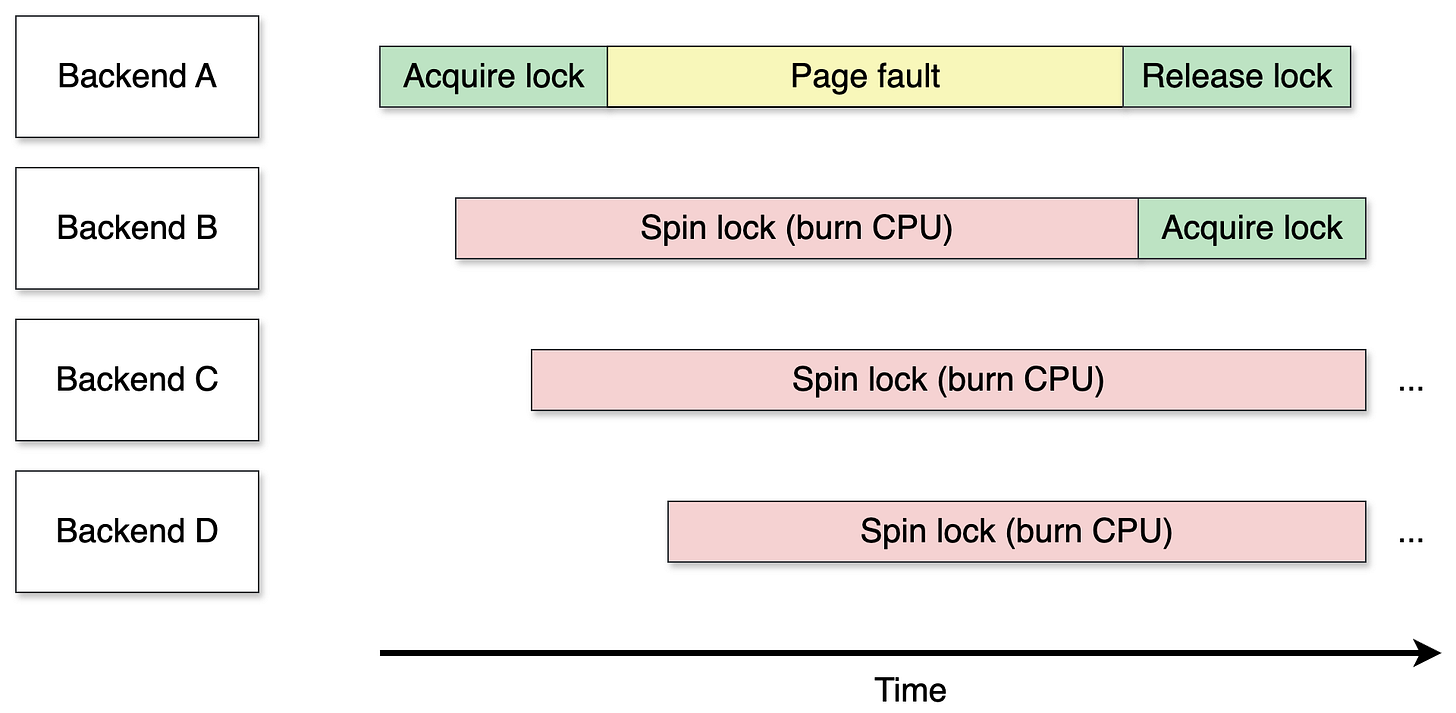
Để điều phối quyền truy cập vào buffer pool giữa hàng trăm backend đồng thời, StrategyGetBuffer sử dụng spinlock.
Spinlock hoạt động dựa trên ý tưởng đơn giản: thay vì ngủ trong khi chờ khóa có sẵn, quy trình chỉ tiếp tục kiểm tra trong một vòng lặp chặt chẽ (nó "xoay"). Giả định chính đằng sau spinlock là: luồng giữ khóa sẽ giải phóng nó rất sớm. Không ai sẽ tiền đình luồng đó ở giữa một phần quan trọng chỉ kéo dài 20 nano-giây.
Sự cố hoàn hảo: Page Fault và Preemption
Vấn đề nằm ở cách bộ nhớ hoạt động ở mức phần cứng, cụ thể là Virtual Memory và TLB (Translation Lookaside Buffer). Mọi quy trình trong Linux làm việc với địa chỉ bộ nhớ ảo. Phần cứng dịch địa chỉ ảo sang địa chỉ vật lý bằng cách sử dụng bảng trang (page table).
Khi PostgreSQL khởi động, nó cấp phát shared buffer pool (ví dụ 120 GB trong bài benchmark) như một vùng bộ nhớ ảo lớn. Linux sử dụng nguyên tắc "lazy allocation": phân bổ được ghi nhận, nhưng các trang vật lý thực tế chỉ được ánh xạ khi được truy cập lần đầu tiên.
Lần đầu tiên mã chạm vào địa chỉ ảo chưa được ánh xạ, một minor page fault xảy ra: kernel cấp phát một trang vật lý và lưu ánh xạ. Điều này mất micro-giây, chậm hơn nhiều so với việc đọc/ghi thông thường.
Theo mặc định, một trang nhớ Linux là 4 KB. Với buffer pool 120 GB, điều này có nghĩa là khoảng 31 triệu trang nhớ tiềm năng. Trong bài benchmark dài, các vùng mới liên tục được đưa vào tập làm việc, do đó các lỗi trang này xảy ra liên tục.
Khi một backend giữ spinlock để tìm một khe trống trong buffer pool, nó cần đọc hoặc ghi bộ nhớ chia sẻ. Nếu vùng đó chưa được chạm vào, nó kích hoạt page fault. Khi lỗi này xảy ra trong khi backend đang giữ spinlock, hậu quả rất nghiêm trọng.
- Với PREEMPT_NONE (trước Linux 7): Khi backend vào trình xử lý lỗi, kernel xử lý lỗi. Do
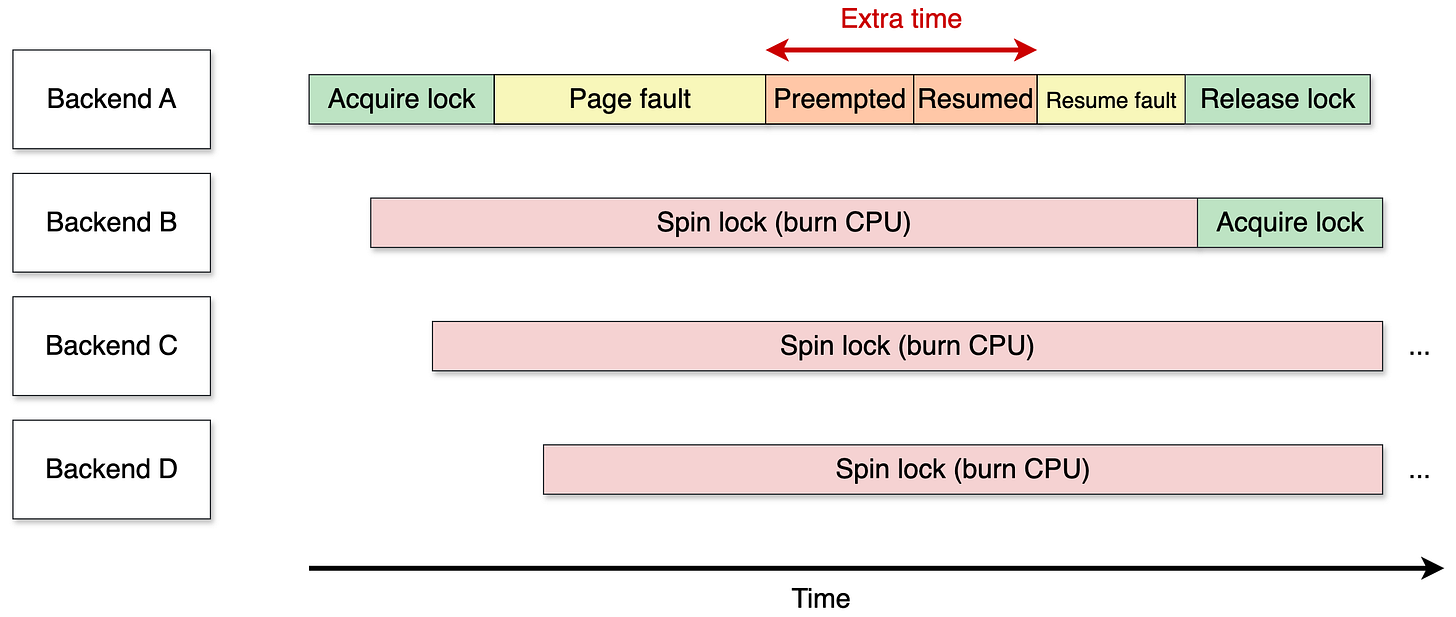
PREEMPT_NONEtránh các điểm lập lịch lại, backend khó bị lên lịch thay thế trước khi lỗi được giải quyết và khóa được giải phóng. Các luồng khác chờ một chút lâu hơn nhưng thiệt hại hạn chế. - Với PREEMPT_LAZY (Linux 7 trở đi): Bộ lập lịch có thể quyết định tiền đình backend ngay khi nó vẫn đang ở trong trình xử lý lỗi. Backend sẽ không tiếp tục cho đến khi bộ lập lịch trả lại quyền kiểm soát. Thời gian giữ khóa kéo dài từ "thời gian xử lý lỗi" thành "thời gian xử lý lỗi + thời gian chờ bộ lập lịch".
Thời gian chờ thêm này không chỉ lãng phí CPU của một luồng, mà được nhân lên với mọi backend đang xoay (spin) chờ khóa. Trên máy 96 vCPU với hàng trăm backend, hệ số nhân này là thảm khốc. Đó là lý do benchmark kết thúc với 56% CPU bị đốt cháy trong s_lock.
Giải pháp: Huge Pages
May mắn thay, có một tùy chọn để khắc phục vấn đề này trong PostgreSQL: Huge Pages (trang nhớ lớn).
Kernel hỗ trợ các trang lớn hơn 4 KB, cụ thể là 2 MB và 1 GB trên x86_64 và ARM64:
- Trang 4 KB: ~31.000.000 lỗi trang tiềm năng
- Trang 2 MB: ~61.440 lỗi trang tiềm năng
- Trang 1 GB: ~120 lỗi trang tiềm năng
Việc tăng kích thước trang nhớ giảm số lượng lỗi trang tiềm năng và giảm áp lực lên TLB. Ít mục nhập hơn cần thiết để bao phủ cùng một lượng bộ nhớ, do đó tập làm việc vừa vặn trong TLB. Nhìn chung, StrategyGetBuffer ngừng kích hoạt lỗi trang trong khi giữ khóa. Người giữ khóa hoàn thành nhanh chóng. Các backend khác chỉ chờ micro-giây thay vì mili-giây. Sự suy giảm hiệu năng biến mất.
Trong PostgreSQL, việc này được kiểm soát bởi tham số cấu hình huge_pages. Các nhà quản trị hệ thống nên đặt giá trị này thành on thay vì try (mặc định) để đảm bảo PostgreSQL sử dụng huge pages và thất bại khi khởi động nếu không có sẵn, thay vì chạy với cấu hình sai mà không để ý.
 Giải pháp và tối ưu hóa hệ thống
Giải pháp và tối ưu hóa hệ thống
Kết luận và tương lai
Peter Zijlstra, kỹ sư kernel Intel người đã viết thay đổi về tiền đình, đã đề xuất một bản sửa lỗi: PostgreSQL nên áp dụng Restartable Sequences (rseq). Đây là cơ chế của kernel Linux cho phép mã người dùng phát hiện xem nó có bị tiền đình hay di chuyển trong một phần quan trọng hay không và khởi động lại nếu có.
Tuy nhiên, cộng đồng PostgreSQL không quá hào hứng. Việc sử dụng một cơ chế kernel cụ thể chỉ để khôi phục hiệu năng mà PostgreSQL từng có miễn phí trước Linux 7.0 là một điều khó chấp nhận. Nó cũng đi ngược lại nguyên tắc lâu đời của kernel: không làm hỏng không gian người dùng (userspace).
Đối với các nhà phát triển và quản trị hệ thống hiện tại, bài học rút ra là rõ ràng: khi nâng cấp lên Linux 7.0 cho các hệ thống PostgreSQL tải nặng, việc kích hoạt Huge Pages không còn là một tùy chọn tối ưu hóa nữa, mà gần như là một yêu cầu bắt buộc để duy trì hiệu suất.

