
memweave: Giải pháp bộ nhớ cho AI Agent sử dụng Markdown và SQLite, không cần Vector Database
memweave là một dự án mã nguồn mở giải quyết vấn đề bộ nhớ cho AI Agent bằng cách sử dụng các tệp Markdown làm nguồn sự thật và SQLite để lập chỉ mục. Phương pháp này loại bỏ sự phức tạp của cơ sở dữ liệu vector, cho phép kiểm soát phiên bản dễ dàng và giảm thiểu chi phí hạ tầng.

memweave: Giải pháp bộ nhớ cho AI Agent sử dụng Markdown và SQLite, không cần Vector Database
Hãy tưởng tượng bạn dành cả buổi chiều để xây dựng một trợ lý lập trình AI. Nó học được các quy ước của dự án, nhớ rằng bạn sử dụng Valkey thay vì Redis, và biết các mẫu kiểm thử mà nhóm bạn ưu tiên. Phiên làm việc kết thúc. Sáng hôm sau, bạn mở một cuộc hội thoại mới và nó đã quên sạch mọi thứ. Mọi thứ quay về vạch xuất phát.
Đây là trạng thái mặc định của mọi AI Agent (tác nhân AI) dựa trên Mô hình ngôn ngữ lớn (LLM) hiện nay. Các mô hình này được thiết kế để vô trạng thái (stateless). Mỗi lần gọi là một trang giấy trắng. Bộ nhớ là vấn đề mà bạn phải tự giải quyết.
Giải pháp phổ biến nhất là nhồi toàn bộ lịch sử hội thoại vào cửa sổ ngữ cảnh (context window). Cách này hoạt động — cho đến khi nó không còn hiệu quả. Cửa sổ ngữ cảnh hữu hạn và tốn kém. Một tác nhân chạy lâu dài sẽ tích lũy hàng nghìn token lịch sử, phần lớn trong đó không liên quan đến câu hỏi hiện tại. Bạn tốn tiền để liên tục cung cấp cho tác nhân các ghi chú gỡ lỗi từ tuần trước, trong khi nó thực sự chỉ cần một quyết định kiến trúc từ ba tháng trước.
Lúc này, mọi người thường tìm đến cơ sở dữ liệu vector. Khởi chạy Chroma, hoặc cung cấp chỉ mục Pinecone, nhúng (embed) mọi thứ và truy vấn dựa trên sự tương đồng ngữ nghĩa. Cách này cũng hoạt động — nhưng nó mang lại một lớp vấn đề mới: tính mờ mịt, không có kiểm soát phiên bản (không có git diff cho vector store), chi phí hạ tầng và bộ nhớ cũ kỹ không có phương thuốc khắc phục.
Có một cách đơn giản hơn: Markdown kết hợp với SQLite.
Cách tiếp cận của memweave: Markdown + SQLite
Ý tưởng cốt lõi đằng sau memweave cực kỳ đơn giản: bộ nhớ là các tệp .md bạn ghi vào đĩa. memweave lập chỉ mục chúng vào cơ sở dữ liệu SQLite cục bộ và cho phép bạn tìm kiếm trên chúng bằng tìm kiếm lai BM25 + tìm kiếm vector ngữ nghĩa. Cơ sở dữ liệu luôn là một bộ nhớ đệm dẫn xuất — nếu bạn xóa nó, memweave sẽ xây dựng lại nó từ các tệp. Các tệp mới là nguồn sự thật.
 Kiến trúc memweave
Kiến trúc memweave
Mọi kết quả tìm kiếm đều bao gồm điểm liên quan, tệp chính xác nó đến từ đó và số dòng — truy xuất nguồn gốc đầy đủ ngay lập tức. Và vì bộ nhớ chỉ là các tệp, bạn có thể kiểm tra chúng bằng bất kỳ công cụ nào bạn đã có: cat, grep, hay quan trọng nhất là git diff.
Lệnh cuối cùng đó — git diff memory/ — là thứ thay đổi cách bạn nghĩ về bộ nhớ của tác nhân. Mọi sự kiện mà tác nhân của bạn lưu trữ là một dòng trong tệp. Mỗi phiên là một lần commit. Những gì tác nhân học được có thể kiểm toán như bất kỳ thay đổi nào khác trong cơ sở mã của bạn.
Tại sao lại chọn Tệp và SQLite thay vì Cơ sở dữ liệu Vector?
Cơ sở dữ liệu vector được thiết kế để truy xuất tài liệu quy mô lớn — hàng triệu tài liệu, dịch vụ đa người thuê và cơ sở hạ tầng tìm kiếm sản xuất. Chúng rất xuất sắc trong công việc đó. Bộ nhớ tác nhân là một công việc hoàn toàn khác: hàng trăm nghìn tệp, phạm vi cá nhân hoặc dự án, nơi kiến thức quan trọng ngang hàng với chính mã nguồn.
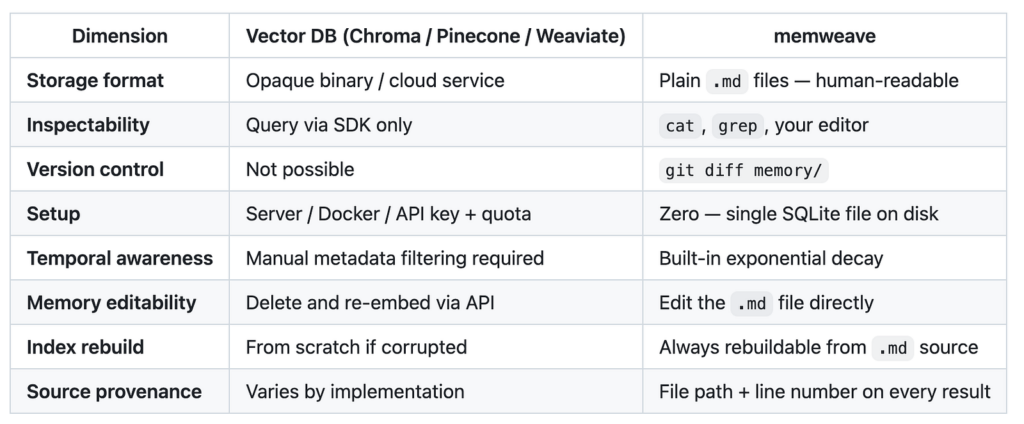 So sánh memweave và Vector Database
So sánh memweave và Vector Database
Sự khác biệt lớn nhất là kiểm soát phiên bản. Hãy xem xét điều gì xảy ra khi tác nhân của bạn lưu trữ một giả định sai — ví dụ, nó học rằng nhóm của bạn sử dụng PostgreSQL khi bạn thực sự đã chuyển sang CockroachDB vào quý trước. Với vector DB, việc sửa chữa này có nghĩa là tìm nhúng đúng, xóa nó và chèn lại phiên bản đã sửa qua API. Với memweave, bạn chỉ cần mở tệp và sửa dòng đó. Sau đó commit nó.
- Database: PostgreSQL (primary), Redis (cache)
+ Database: CockroachDB (primary, migrated Q1 2026), Valkey (cache)
+ Reason: geo-distribution requirement from the platform team
Diff đó giờ đây là một phần của lịch sử dự án của bạn. Bất kỳ đồng nghiệp nào — hoặc bất kỳ tác nhân tương lai nào — đều có thể thấy những gì đã thay đổi, khi nào và tại sao.
Quy trình tìm kiếm và xử lý bộ nhớ
memweave được xây dựng xung quanh một ý tưởng trung tâm: tách biệt lưu trữ khỏi tìm kiếm. Các tệp Markdown là nguồn sự thật. Cơ sở dữ liệu SQLite là một chỉ mục dẫn xuất — luôn có thể xây dựng lại, không bao giờ không thể thay thế.
Khi bạn gọi await mem.search(query), cả hai backend tìm kiếm chạy song song trên cùng một truy vấn và kết quả của chúng được hợp nhất trước khi xử lý hậu kỳ:
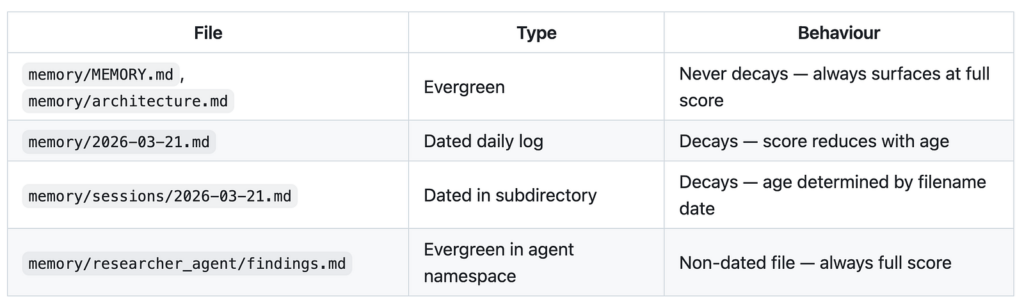 Quy trình tìm kiếm memweave
Quy trình tìm kiếm memweave
Việc chạy cả hai backend song song rất quan trọng: BM25 bắt được các kết quả khớp chính xác — mã lỗi, giá trị cấu hình, tên riêng — trong khi tìm kiếm vector bắt được nội dung liên quan về mặt ngữ nghĩa ngay cả khi không có từ khóa trùng khớp. Cùng nhau, chúng bao phủ toàn bộ phạm vi cách bộ nhớ của tác nhân có thể được truy vấn.
Một tính năng quan trọng khác là Temporal Decay (Sự suy giảm theo thời gian). Không phải kiến thức nào cũng già đi giống nhau. Quyết định sử dụng CockroachDB thay vì PostgreSQL vẫn phù hợp hôm nay như ngày nó được đưa ra. Một ghi chú gỡ lỗi từ phiên sáu tháng trước thì có thể không.
memweave thực thi sự phân biệt này ở cấp độ tệp. Bất kỳ tệp nào có tên khớp với YYYY-MM-DD.md là dated (có ngày tháng). Mọi thứ khác là evergreen (vĩnh cửu). Theo thời gian, các tệp dated sẽ tích lũy và mờ dần. Các tệp evergreen vẫn được neo ở điểm số đầy đủ bất kể có bao nhiêu lịch sử được xây dựng xung quanh chúng.
Ví dụ thực tế: Vấn đề bộ nhớ cũ
Để minh họa tầm quan trọng của Temporal Decay, hãy xem xét một ví dụ về một câu lạc bộ sách. Cả hai tác nhân đều được hỏi cùng một câu hỏi: "Thể loại nào mà câu lạc bộ đã bầu chọn gần đây nhất?"
Câu trả lời đúng — dựa trên thông tin mới nhất — là khoa học viễn tưởng. Tuy nhiên, một tác nhân không có nhận thức về thời gian sẽ không nhất thiết tìm thấy điều này.
- Tác nhân A (Không có Temporal Decay): Trả lời "Phi hư cấu" (Non-fiction) dựa trên một cuộc bỏ phiếu 5 tháng trước, vì tệp đó có ngôn ngữ "bỏ phiếu" rõ ràng hơn và điểm tương đồng ngữ nghĩa cao hơn.
- Tác nhân B (Có Temporal Decay): Trả lời "Khoa học viễn tưởng" (Science fiction) dựa trên tệp của hôm nay, vì cơ chế suy giảm đã làm giảm điểm số của các tệp cũ, giúp thông tin mới nổi lên trên cùng.
Vấn đề bộ nhớ cũ là có thật và âm thầm. Tác nhân A không biết nó sai. Nó trả lời một câu hỏi tự tin dựa trên các kết quả phù hợp về mặt ngữ nghĩa — tình cờ là các tệp cũ hơn. Không có lỗi, không có cảnh báo, chỉ là ngữ cảnh hơi lỗi thời.
Kết luận
Bộ nhớ của tác nhân không nhất thiết phải đồng nghĩa với hạ tầng. memweave đặt một cược khác: bộ nhớ là các tệp Markdown đơn giản bạn có thể mở, chỉnh sửa và git diff. Một cơ sở dữ liệu SQLite cục bộ lập chỉ mục chúng để tìm kiếm lai — BM25 cho kết quả khớp chính xác, tìm kiếm vector để truy xuất ngữ nghĩa, hợp nhất thành một danh sách được xếp hạng duy nhất.
Toàn bộ kho lưu trữ chỉ là một tệp duy nhất trên đĩa — không có máy chủ, không có Docker, không có dịch vụ đám mây. Đây là một giải pháp tối ưu cho quy mô bộ nhớ của tác nhân (hàng nghìn tệp), mang lại tính minh bạch và khả năng kiểm soát mà các cơ sở dữ liệu vector truyền thống không thể so sánh được.
Bài viết liên quan

Phần mềm
Hiểu rõ bản chất quy tắc thay vì tìm cách lách luật trong lập trình hệ thống
16 tháng 6, 2026

Công nghệ
Các tác nhân AI đã khiến thế giới công nghệ chao đảo: Câu chuyện đằng sau cuộc cách mạng Claude Code và OpenClaw
26 tháng 5, 2026

Phần mềm
Google tung ra Antigravity 2.0: Ứng dụng lập trình thế hệ mới với công cụ CLI và gói đăng ký AI Ultra
19 tháng 5, 2026