
Ngôn ngữ có phải là hình ảnh? Thí nghiệm thú vị với mô hình ngôn ngữ và chữ Hán
Bài viết khám phá việc sử dụng dữ liệu hình ảnh thay vì mã hóa văn bản truyền thống để huấn luyện mô hình ngôn ngữ cho tiếng Trung. Kết quả cho thấy mô hình thị giác học nhanh hơn nhờ cấu trúc hình ảnh của chữ Hán, nhưng về lâu dài thì độ chính xác tương đương với mô hình văn bản. Phương pháp này hứa hẹn trong các tình huống thiếu dữ liệu hoặc xử lý văn bản cổ bị hư hại.

Câu chuyện bắt đầu từ một bài đăng gây tranh cãi trên Douban — một nền tảng mạng xã hội của Trung Quốc — về chiếc máy in bị lỗi. Chủ nhân của chiếc máy in nhận thấy rằng khi mực sắp hết, mỗi chữ chỉ được in ra một nửa trên cùng. Và điều kỳ diệu là văn bản đó vẫn hoàn toàn có thể đọc được.
Hãy nhìn vào ba phiên bản của cụm từ "trí tuệ nhân tạo" (人工智能) dưới đây:
 Các phiên bản cắt xén của chữ Hán
Các phiên bản cắt xén của chữ Hán
Bạn có thể đọc ngay lập tức cả ba phiên bản: Chữ đầy đủ, giữ lại 80% và giữ lại 50%. Đó không phải là một trò lừa bịp, mà có lẽ là điều gì đó căn bản bắt nguồn từ hệ thống chữ viết của người Trung Quốc. Điều này khiến tôi đặt ra câu hỏi: Liệu ngôn ngữ — ít nhất là tiếng Trung — có mang tính chất thị giác từ gốc rễ không?
Thí nghiệm: Đưa điểm ảnh vào, lấy Token ra
Mọi mô hình ngôn ngữ (LLM) đều phải xử lý vấn đề tokenization (mã hóa văn bản) trước tiên. Ý tưởng cơ bản là: máy tính không hiểu văn bản, nên chúng ta gán cho mỗi từ hoặc chữ một ID, hay nói cách khác là một con số. Ví dụ, chữ "bạn" trở thành 100, chữ "tốt" trở thành 3, v.v. Từ đó, LLM học mọi thứ từ con số không.
Theo nghĩa này, khi bạn giảm các chữ như "sơn" (núi) và "thủy" (nước) thành các số nguyên đơn giản, bạn đã loại bỏ hình dáng của chúng. Và chữ Hán có những hình dáng đẹp đẽ — cấu hình nét viết, các thành phần bộ thủ, bố cục không gian mang lại thông tin thực sự. Một ví dụ khác: các chữ "đánh" (打), "vỗ" (拍) và "kéo" (拉) đều chia sẻ bộ thủ "tay" (扌). Nếu bạn giảm chúng thành các ID 423, 1089 và 2341, mối quan hệ đó sẽ biến mất.
Thay vì sử dụng ID token, tôi đã hiển thị mỗi chữ dưới dạng một ảnh grayscale và đưa nó vào mô hình ngôn ngữ. Nhiệm vụ của mô hình là dự đoán chữ tiếp theo.
Bạn không cần thị lực quá tốt
Nếu bạn từng tháo kính ra để đọc, bạn biết rằng văn bản mờ vẫn có thể đọc được. Nguyên lý tương tự cũng xảy ra ở đây.
Hãy xem các phiên bản 8×8 pixel của chữ "trí tuệ nhân tạo" (hãy giữ màn hình ở khoảng cách bằng một cánh tay):
Các phiên bản chữ Hán ở độ phân giải thấp
Mỗi chữ chỉ có 64 pixel. Và mô hình, được huấn luyện trên đầu vào ở độ phân giải này, hoạt động tốt tương đương với mô hình được huấn luyện trên ảnh 80×80.
Chúng tôi đã kiểm tra độ phân giải ảnh từ 4×4 đến 80×80 và nhận thấy rằng: Việc tăng từ 8×8 lên 80×80 — tức là tăng gấp 100 lần số lượng pixel — về cơ bản không mang lại lợi ích gì.
Kết quả cắt xén còn ấn tượng và thú vị hơn. Với 50% mỗi chữ bị loại bỏ, độ chính xác chỉ giảm chưa đến 2%. Mô hình không cần bức tranh hoàn chỉnh rõ ràng. Hóa ra là nó chỉ cần đủ cấu trúc để biết chữ đó thuộc về họ bộ thủ nào.
Hiệu ứng khởi đầu nóng (Hot-Start Effect)
Vậy, mô hình thị giác có tốt hơn mô hình dựa trên văn bản không?
Cuối cùng thì không. Cả hai đều hội tụ về độ chính xác cuối về cơ bản là giống hệt nhau. Nhưng hành trình của chúng trông rất khác nhau, đặc biệt là ở giai đoạn đầu.
Sau khi chỉ nhìn thấy 0,4% các bước huấn luyện, mô hình thị giác đã chính xác gấp đôi so với đường cơ sở dựa trên văn bản.
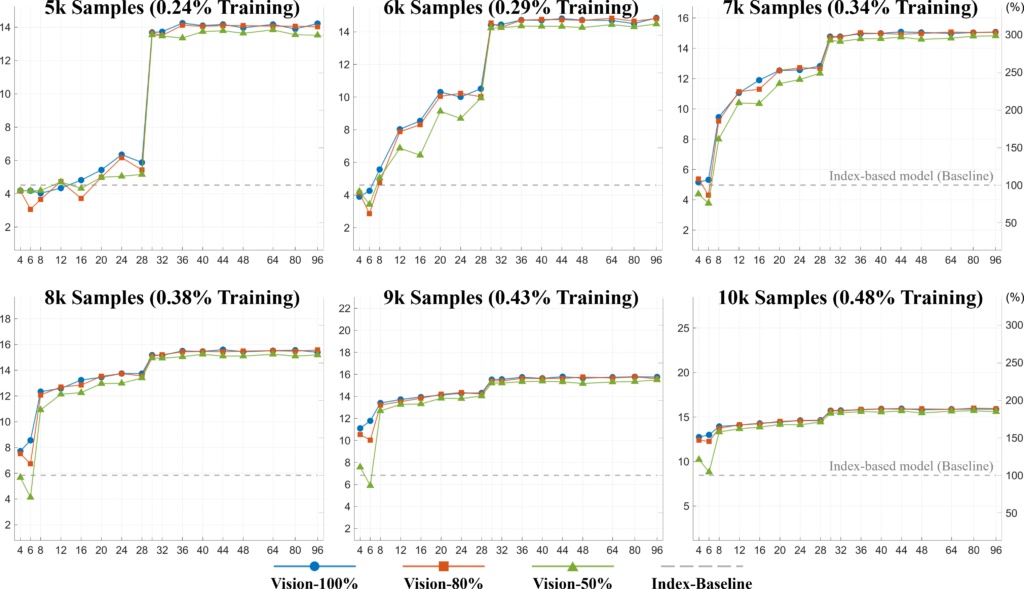 Động lực huấn luyện ở giai đoạn đầu
Động lực huấn luyện ở giai đoạn đầu
Đây là những gì chúng tôi gọi là hiệu ứng khởi đầu nóng. Mô hình thị giác đến với quá trình huấn luyện đã biết một điều gì đó hữu ích: rằng "đánh", "vỗ" và "kéo" trông giống nhau và có thể hoạt động tương tự nhau. Mô hình dựa trên văn bản bắt đầu với các nhúng ngẫu nhiên và phải tự tìm ra điều này từ đầu.
Nếu bạn nhìn vào không gian nhúng (embedding space) tại thời điểm khởi tạo — trước bất kỳ huấn luyện nào — bạn có thể thấy điều này trực quan:
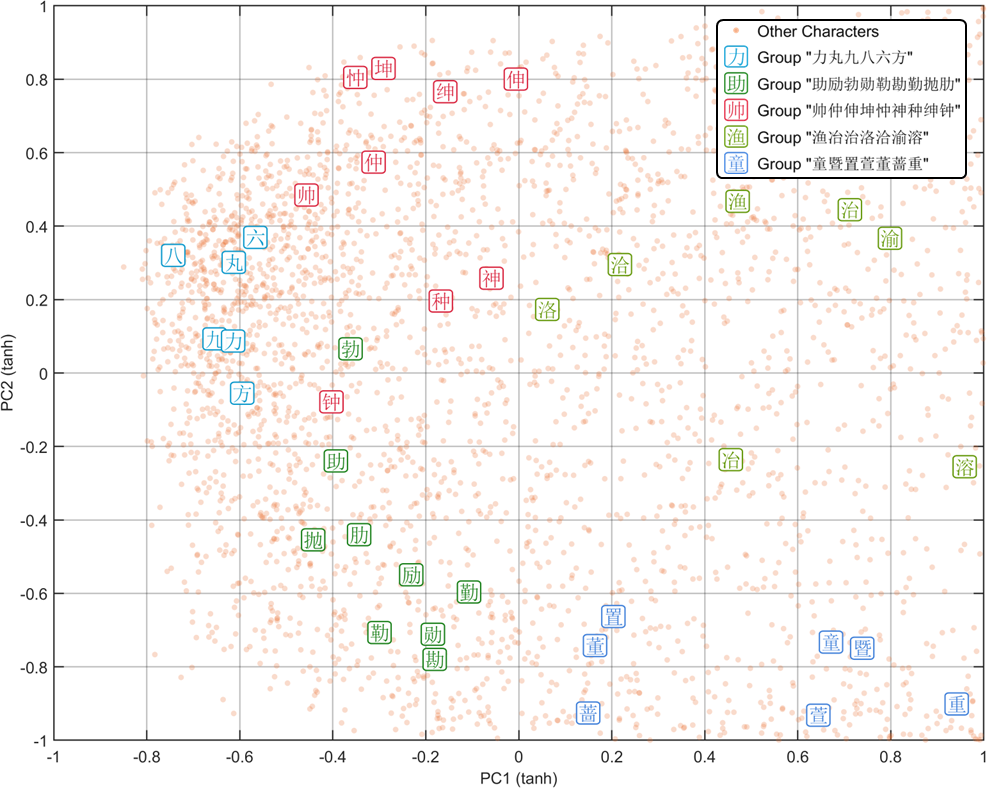 Không gian nhúng của các chữ Hán
Không gian nhúng của các chữ Hán
Bạn có thể thấy rằng các chữ có chung bộ thủ được nhóm lại với nhau ở giai đoạn huấn luyện rất sớm. Độ tương đồng cosine cho các cặp có chung bộ thủ: ~0,27 cho nhúng thị giác, so với ~0,002 cho nhúng token ngẫu nhiên.
Tại sao cuộc đua kết thúc hòa
Điểm mấu chốt ở đây là: kiến thức trước (prior) về thị giác mã hóa sự tương đồng về mặt hình ảnh, nhưng không mã hóa sự đồng xuất hiện ngôn ngữ (linguistic co-occurrence). Tuy nhiên, việc dự đoán chữ tiếp theo cuối cùng phụ thuộc vào后者.
Đúng là "đánh", "vỗ" và "kéo" đều có bộ thủ "tay" và trông giống nhau. Nhưng trong văn bản thực tế, chúng có thể xuất hiện trong các ngữ cảnh rất khác nhau — "đánh tội phạm" (打击犯罪), "chụp ảnh" (拍摄照片), "kéo nền kinh tế" (拉动经济), v.v. Khi mô hình văn bản đã nhìn thấy đủ dữ liệu để học các mẫu này, kiến thức thị giác trước đó không còn quan trọng nữa.
Nói cách khác, đầu vào thị giác giúp khởi động quá trình tối ưu hóa (warm-start). Nhưng nó không làm thay đổi trần thông tin.
Điều này luôn khiến tôi nhớ đến câu chuyện "Câu chuyện cuộc đời bạn" của Ted Chiang (cơ sở cho bộ phim "Sự xuất hiện"). Trong câu chuyện, ngôn ngữ viết và nói là hai hệ thống độc lập. Nhưng chúng cuối cùng phục vụ cùng một mục đích: giao tiếp. Hai con đường, cùng một điểm đến.
Điều này thực sự quan trọng ở đâu
Mặc dù cùng một điểm đến, nhưng có những tình huống thực tế mà điều này lại quan trọng:
Cài đặt tài nguyên thấp (Low-resource settings). Khi bạn không có nhiều dữ liệu huấn luyện, lợi thế đầu về mặt thị giác chuyển thành một lợi thế thực tế. Trong các thí nghiệm của chúng tôi, với chỉ 10K mẫu, các mô hình thị giác đã vượt trội hơn đường cơ sở văn bản được huấn luyện đầy đủ trên các điểm chuẩn tiếng Trung (C-eval).
Văn bản lịch sử bị hư hại. Đây là một ứng dụng thú vị khác. Thị giác có thể giúp kiểm tra các bản thảo tiếng Trung cổ, sách bị hỏng và tài liệu viết tay nơi các nét chữ bị thiếu hoặc mờ nhạt.
Vậy chi phí tính toán thì sao?
Tin vui: hầu như không có chi phí thêm. Bộ mã hóa thị giác đơn giản hóa mà tôi sử dụng thực tế có ít tham số hơn so với đường cơ sở văn bản (12,6M so với 19,0M). Chi phí bộ nhớ: +1,3%. Vì vậy, chúng tôi lập luận rằng kiến thức trước về thị giác gần như miễn phí.
Câu trả lời ngắn gọn
Tiếng Trung có mang tính thị giác tự nhiên không? Câu trả lời dường như là: ở giai đoạn đầu, có. Đến cuối, thì không quan trọng.
Cấu trúc thị giác mang lại cho mô hình một khởi đầu nóng. Nó tương tự như cách người đọc nhìn thấy bộ thủ "tay" và ngay lập tức biết họ đang ở trong lãnh thổ của các hành động liên quan đến tay. Nhưng các mẫu sâu hơn của ngôn ngữ phải được học từ dữ liệu. Cả hai cách biểu diễn đều học chúng tốt như nhau.
Bài báo chi tiết đã được đăng trên arxiv: https://arxiv.org/abs/2601.09566