
Ngưỡng Dự Báo Rời Bỏ (Churn) Thực Chất Là Một Quyết Định Về Giá Cả
Việc sử dụng ngưỡng mặc định 0.5 trong các mô hình dự báo rời bỏ của khách hàng (churn) có thể gây ra thiệt hại tài chính lớn do bỏ qua sự bất cân xứng trong chi phí. Bài viết phân tích cách kinh tế đơn vị nên xác định ngưỡng phân loại, tại sao các phương pháp truyền thống thường thất bại và tầm quan trọng của việc sử dụng phân tích tồn tại (survival analysis) để tối ưu hóa lợi nhuận.

Khi một mô hình dự báo rời bỏ (churn) nói rằng "xác suất khách hàng này rời đi là 0.4" và mã của bạn thực hiện lệnh predict(X) >= 0.5, bạn vừa mới đưa ra một quyết định về giá cả: bạn đã quyết định rằng chi phí để gửi một ưu đãi giữ chân khách hàng cho người lẽ ra vẫn ở lại chính xác bằng chi phí để mất đi một người lẽ ra sẽ rời đi. Trên tập dữ liệu IBM Telco—một trong những tập dữ liệu về churn được sử dụng nhiều nhất trên Kaggle và GitHub—quyết định đó sai lệch tới mức 13 lần.
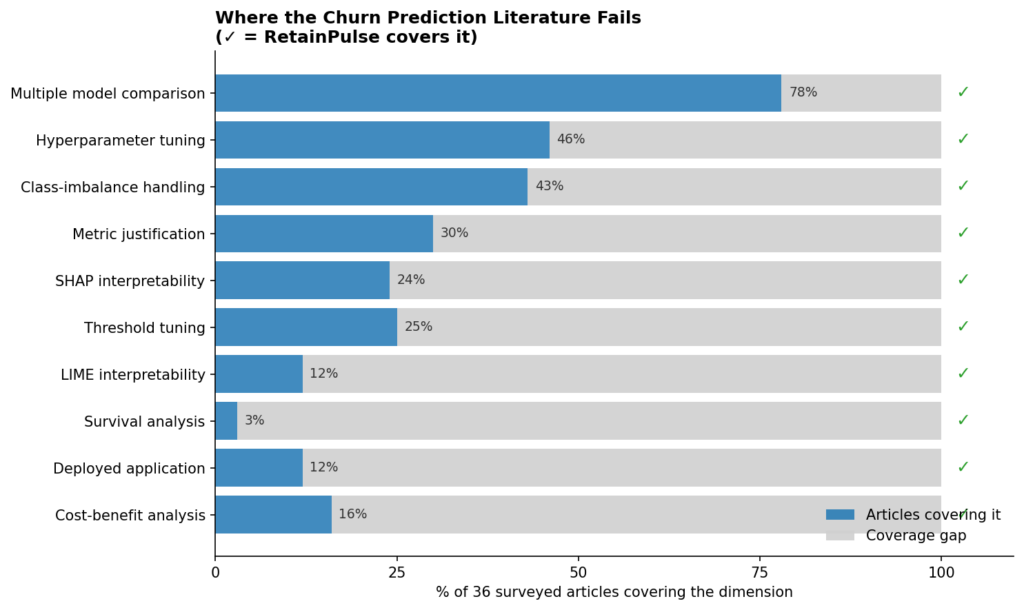
Tôi đã tổng hợp một kho dữ liệu gồm 36 phân tích công khai về churn của IBM Telco (bao gồm các notebook trên Kaggle, kho lưu trữ GitHub, bài viết blog và các bài báo được đánh giá ngang hàng), và mô hình báo cáo cho thấy một xu hướng đáng chú ý: khoảng chín mươi phần trăm báo cáo độ chính xác phân loại hoặc điểm F1, chỉ hơn một phần bảy báo cáo đường cong lợi nhuận (profit curve), và không bài nào sử dụng phân tích tồn tại để tính toán giá trị vòng đời khách hàng (LTV).
Kết quả là một kho tàng nghiên cứu nơi cùng một tập dữ liệu được mô hình hóa lại hàng trăm lần, và mọi mô hình sử dụng ngưỡng mặc định đều để mất tiền trên bàn: khoảng 86 USD mỗi khách hàng dưới dạng "thiệt hại có thể tránh được" trên tập kiểm tra tiêu chuẩn 20%. Nếu quy mô lên một danh sách 100.000 người đăng ký có cùng hồ sơ churn, con số đó sẽ đại diện cho 8,6 triệu USD chi phí có thể thu hồi.
 Khoảng trống trong báo cáo phân tích Churn
Khoảng trống trong báo cáo phân tích Churn
Khoảng trống trong 36 bài phân tích
Tập dữ liệu IBM Telco Customer Churn nhỏ gọn (7.032 dòng sau khi làm sạch), ngăn nắp, có gắn nhãn và đã là tập dữ liệu churn giới thiệu tiêu chuẩn trên Kaggle trong gần một thập kỷ. Để hiểu rõ những gì cộng đồng thực sự đo lường, tôi đã lập chỉ mục 36 phân tích trên Kaggle, GitHub và các blog khoa học dữ liệu lớn, chấm điểm từng bài trên mười chiều đo lường từ điểm F1 đến đường cong lợi nhuận dựa trên CAC và LTV.
Ba phát hiện đáng chú ý:
- Bão hòa: Điểm F1, độ chính xác, AUC, ảnh ma trận nhầm lẫn và các so sánh SMOTE (kỹ thuật lấy mẫu quá mức) xuất hiện trong 80–90% các bài viết. Việc tinh chỉnh siêu tham số thông qua Optuna hoặc tìm kiếm lưới (grid search) là một mô-típ gần như phổ biến.
- Ít gặp: Đường cong lợi nhuận (tổng chi phí bằng đô la của các sự phân loại nhầm dưới dạng hàm của ngưỡng quyết định) xuất hiện ở dưới 15% các phân tích tôi xem xét. Khi nó xuất hiện, các con số chi phí FN/FP thường được lấy từ một ví dụ trong sách giáo khoa mà không neo chúng vào CAC hay LTV thực tế.
- Vắng mặt: Không có bất kỳ phân tích nào trong số 36 bài tôi lập chỉ mục tính toán giá trị vòng đời khách hàng thông qua phân tích tồn tại trên thời hạn sử dụng (tenure). Hầu hết bỏ qua LTV hoàn toàn hoặc sử dụng công thức trạng thái ổn định của Skok
LTV = ARPU / tỷ lệ churn hàng tháng, công thức này giả định một cơ sở khách hàng đồng nhất—một giả định mạnh mẽ đối với một tập dữ liệu nơi loại hợp đồng, phương thức thanh toán và thời hạn sử dụng đều ảnh hưởng đáng kể đến việc giữ chân khách hàng.
Việc bỏ qua phân tích tồn tại rất quan trọng vì quyết định ngưỡng là một hàm của LTV: nếu bạn đánh giá sai LTV gấp 2 lần, bạn sẽ đánh giá sai chi phí của việc bỏ sót một người rời đi (churner) gấp 2 lần, và ngưỡng tối ưu về chi phí sẽ dịch chuyển theo nó.
Chi phí của một sai lầm, tính bằng đô la
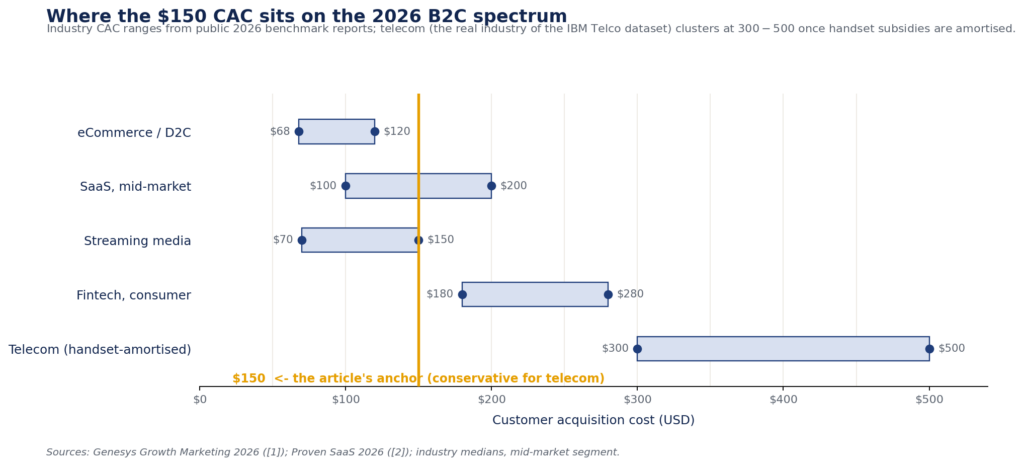
Ba con số xác định chi phí bằng đô la của mọi dự đoán (ARPU, biên lợi nhuận gộp và CAC); hai con số đến trực tiếp từ tập dữ liệu, một con số từ các chuẩn mực ngành công khai năm 2026.
 Các chuẩn mực CAC và Biên lợi nhuận
Các chuẩn mực CAC và Biên lợi nhuận
Đối với B2C SaaS trong các chuẩn mực năm 2026, CAC dao động từ khoảng 68 USD (thương mại điện tử) đến hơn 200 USD (fintech), với các sản phẩm đăng ký thị trường tầm trung tập trung quanh mức 150 USD. Chi phí thu hút người đăng ký viễn thông cao hơn đáng kể (300+ USD sau khi khấu hao trợ cấp thiết bị), vì vậy 150 USD là một mỏ neo thận trọng cho tập dữ liệu này. Biên lợi nhuận gộp cho B2C SaaS nằm trong dải 70–85%, với 75% là điểm giữa thường gặp phù hợp với các giả định mô hình hóa của David Skok.
Điều này cho chúng ta các khối xây dựng cho chi phí của một lỗi dự đoán duy nhất:
- Chi phí Âm giả (FN - False Negative): Chi phí thu hút mới (150 USD) cộng với 18 tháng doanh thu bị mất đi (64,80 USD × 18 = 1.166,40 USD). Tổng cộng: 1.316,40 USD.
- Chi phí Dương giả (FP - False Positive): Cờ đỏ một khách hàng là rủi ro rời đi khi họ thực sự sẽ ở lại tốn khoảng 100 USD chi phí chiến dịch và giảm giá.
Tỷ lệ này là 13,2 : 1. Đây là lý do toàn bộ tại sao ngưỡng = 0.5 là mặc định sai: ranh giới quyết định nên phản ánh sự bất cân xứng này.
Đường cong lợi nhuận LTV
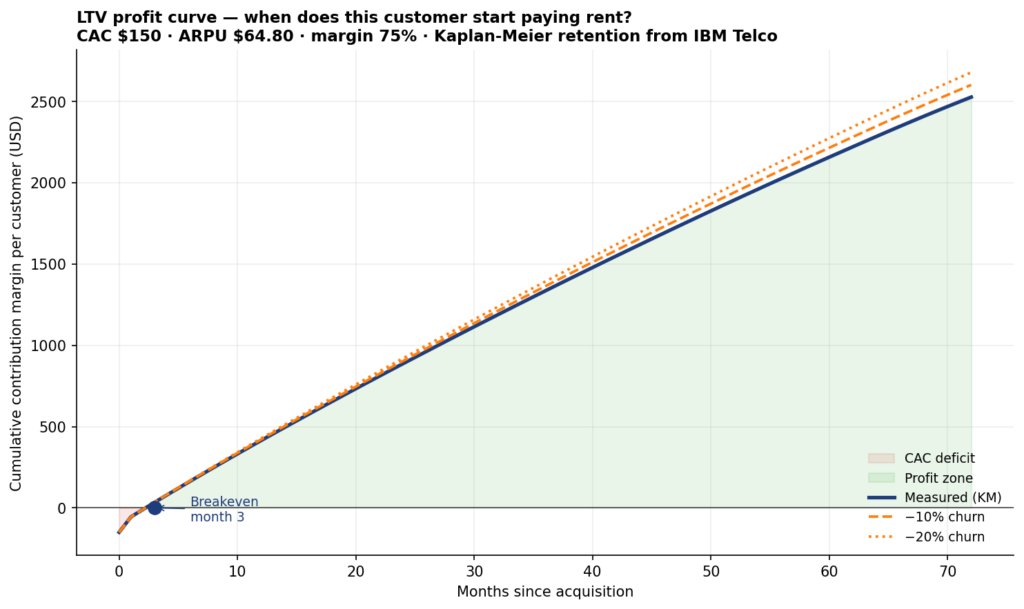
Hầu hết các bài viết về churn coi giá trị vòng đời là một con số tĩnh nhân với tỷ lệ rủi ro. Phân tích tồn tại làm tốt hơn. Nó đo lường khả năng giữ chân trực tiếp từ dữ liệu và biến LTV thành một đường cong: biên đóng góp tích lũy trên mỗi khách hàng dưới dạng hàm của số tháng kể từ khi có được, bắt đầu ở −CAC vào ngày thứ 0 và tăng lên khi mỗi tháng tồn tại thêm ARPU × biên_lợi_nhuận × P(vẫn còn sống) vào số dư.
 Đường cong lợi nhuận LTV
Đường cong lợi nhuận LTV
Ước tính Kaplan-Meier đảm nhận phần nặng nhọc, với thời hạn sử dụng là thời lượng và Churn == "Yes" là sự kiện. Ba điểm đọc đáng chú ý từ đường cong này:
- Điểm hòa vốn vào tháng thứ 3: Trên nhóm khách hàng được thu hút ban đầu, đóng góp tích lũy có trọng số tồn tại bao phủ chi phí thu hút 150 USD vào tháng thứ 3.
- LTV tại chân trời 72 tháng ≈ 2.527 USD mỗi khách hàng: Kết hợp với CAC 150 USD, đó là tỷ lệ LTV:CAC khoảng 17,8:1, cao hơn nhiều so với mức sàn 3:1 mà hầu hết các nhà đầu tư SaaS tìm kiếm.
- Phân khúc theo hợp đồng: Một khách hàng hợp đồng hai năm có giá trị khoảng 3.372 USD trong 72 tháng, trong khi một khách hàng tháng-tới-tháng (month-to-month) chỉ có giá trị 1.620 USD (ít hơn một nửa), với cùng ARPU và cùng CAC. Toàn bộ sự chênh lệch nằm ở khả năng giữ chân.
Đường cong lợi nhuận phân loại
Với chi phí FN, chi phí FP và LTV dựa trên sự tồn tại trong tay, vấn đề ngưỡng trở thành một bài toán tối ưu hóa một chiều: huấn luyện mô hình, lấy xác suất dự đoán trên tập kiểm tra, quét ngưỡng từ 0 đến 1, tính tổng chi phí bằng đô la tại mỗi ngưỡng và chọn mức tối thiểu.
Mô hình ở đây là một XGBoost đã tinh chỉnh, được huấn luyện với SMOTE chỉ trên tập huấn luyện—công thức chuẩn cho Telco.
Kết quả cho thấy việc chuyển từ 0.5 xuống mức tối thiểu thực nghiệm thu hồi 121.160 USD trên tập kiểm tra, tương đương 86,11 USD mỗi khách hàng. Áp dụng điều đó cho một danh sách 100.000 người đăng ký cho ra con số tiêu đề 8,6 triệu USD.
Khi công thức sách giáo khoa thua cuộc trước việc quét ngưỡng
Trong bất kỳ tài liệu tham khảo phân loại nhạy cảm về chi phí nào, bạn sẽ tìm thấy công thức ngưỡng tối ưu Bayes:
t* = C_FP / (C_FP + C_FN)
Với tỷ lệ chi phí của chúng ta: t* = 100 / (100 + 1316.40) ≈ 0.0706. Đây là toán học đúng, nhưng việc quét cho ra t = 0.03. Tại sao có khoảng cách?
Công thức tối ưu Bayes giả định các xác suất dự đoán của mô hình đã được hiệu chuẩn: một dự đoán 0.5 nên tương ứng với 50% xác suất churn thực sự. Tuy nhiên, mô hình của chúng tôi được huấn luyện trên tập dữ liệu cân bằng SMOTE, làm phồng lớp thiểu số lên 50% trong quá trình huấn luyện. Các mô hình dựa trên cây sau đó xuất ra xác suất bị thiên lệch về các giá trị cao hơn.
Có hai cách khắc phục rõ ràng:
- Hiệu chuẩn xác suất trước (sử dụng Platt scaling hoặc hồi quy đẳng hướng).
- Bỏ qua hiệu chuẩn và quét (sweep): Nó rẻ, chịu được sự trôi dạt hiệu chuẩn và trên các tập dữ liệu nhỏ như Telco, việc quét tập kiểm tra đáng tin cậy hơn mô hình hiệu chỉnh.
Bài viết IBM Telco tiếp theo nên báo cáo điều gì?
Ba thay đổi cụ thể sẽ làm cho 36 phân tích IBM Telco tiếp theo hữu ích hơn 36 bài trước:
- Báo cáo đường cong lợi nhuận, không phải ma trận nhầm lẫn: Điểm F1 tại ngưỡng 0.5 là một chỉ số thi đấu (hữu ích để xếp hạng mô hình khi bạn phải chọn một cái, vô dụng để quyết định cách triển khai nó).
- Neo LTV vào phân tích tồn tại, không phải giả định trạng thái ổn định: Kaplan-Meier trên thời hạn sử dụng chỉ khoảng 30 dòng Python; nó cung cấp cho hoạt động marketing một ngân sách sử dụng được để chi cho giữ chân.
- Tiết lộ giả định hiệu chuẩn khi bạn trích dẫn ngưỡng tối ưu Bayes: Hoặc hiệu chuẩn trước hoặc lưu ý rõ ràng rằng ngưỡng được báo cáo là mức tối thiểu thực nghiệm từ việc quét.
Tôi bước vào vấn đề này mong đợi khoảng cách sẽ nằm ở chỗ mô hình hóa. Nhưng không phải vậy. Tập dữ liệu IBM Telco đã được khai thác đến đáy đá để có độ chính xác dự đoán, và những gì nó vẫn có thể dạy là liệu các quy trình của chúng ta có dẫn đến các quyết định tốt hay không, không chỉ là các dự đoán chính xác.
Bài viết liên quan

Phần mềm
Lỗ hổng kernel Linux mới "Fragnesia" cho phép leo quyền root nguy hiểm
14 tháng 5, 2026

Phần mềm
Chính phủ Mỹ yêu cầu Instructure giải trình về sự cố tấn công mạng và lộ dữ liệu Canvas
13 tháng 5, 2026

Phần mềm
Tấn công Cache Poisoning biến các gói npm TanStack thành mối đe dọa nguy hiểm
12 tháng 5, 2026